标签:pip tin 信息 ext html rop with open extra top
Scrapy是用python实现的一个为了爬取网站数据,提取结构性数据而编写的应用框架。使用Twisted高效异步网络框架来处理网络通信。
Scrapy架构:
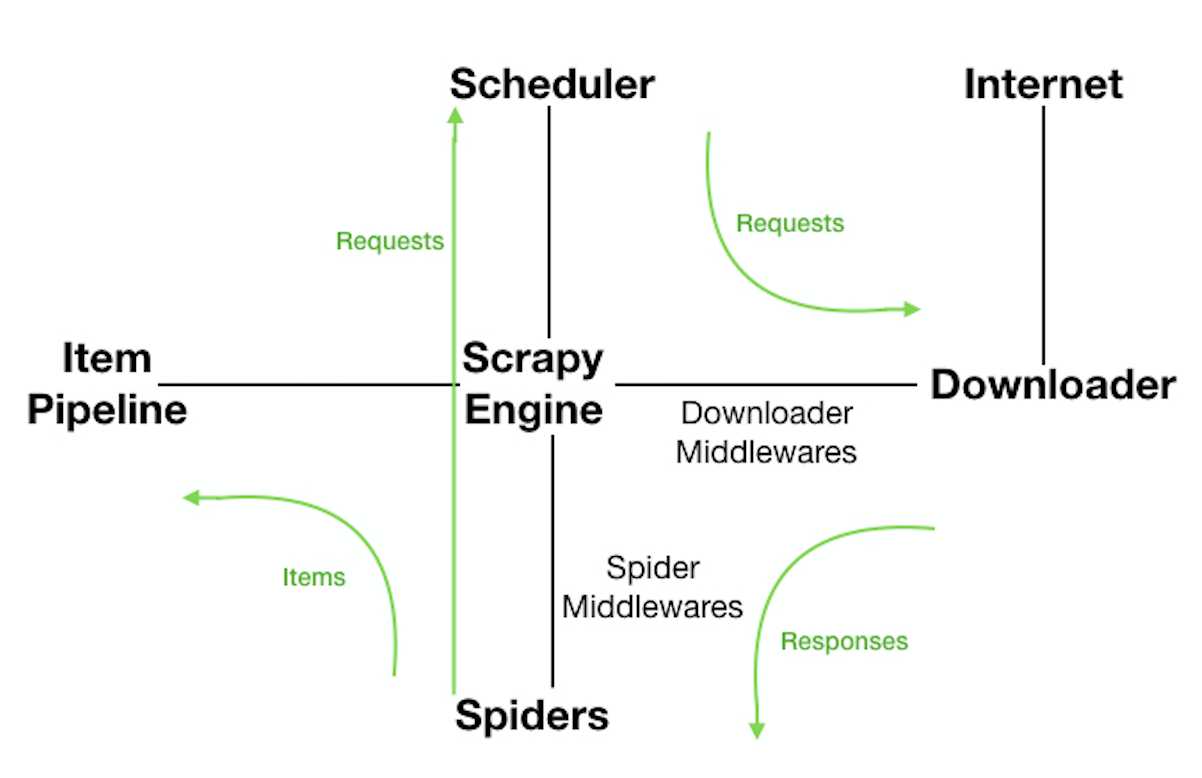
ScrapyEngine:引擎。负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 此组件相当于爬虫的“大脑”,是 整个爬虫的调度中心。
Schedule:调度器。接收从引擎发过来的requests,并将他们入队。初始爬取url和后续在页面里爬到的待爬取url放入调度器中,等待被爬取。调度器会自动去掉重复的url。
Downloader:下载器。负责获取页面数据,并提供给引擎,而后提供给spider。
Spider:爬虫。用户编些用于分析response并提取item和额外跟进的url。将额外跟进的url提交给ScrapyEngine,加入到Schedule中。将每个spider负责处理一个特定(或 一些)网站。
ItemPipeline:负责处理被spider提取出来的item。当页面被爬虫解析所需的数据存入Item后,将被发送到Pipeline,并经过设置好次序
DownloaderMiddlewares:下载中间件。是在引擎和下载器之间的特定钩子(specific hook),处理它们之间的请求(request)和响应(response)。提供了一个简单的机制,通过插入自定义代码来扩展Scrapy功能。通过设置DownloaderMiddlewares来实现爬虫自动更换user-agent,IP等。
SpiderMiddlewares:Spider中间件。是在引擎和Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items或requests)。提供了同样简单机制,通过插入自定义代码来扩展Scrapy功能。
数据流:
1.ScrapyEngine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个(批)要爬取的url(s);
2.ScrapyEngine向调度器请求第一个要爬取的url,并加入到Schedule作为请求以备调度;
3.ScrapyEngine向调度器请求下一个要爬取的url;
4.Schedule返回下一个要爬取的url给ScrapyEngine,ScrapyEngine通过DownloaderMiddlewares将url转发给Downloader;
5.页面下载完毕,Downloader生成一个页面的Response,通过DownloaderMiddlewares发送给ScrapyEngine;
6.ScrapyEngine从Downloader中接收到Response,通过SpiderMiddlewares发送给Spider处理;
7.Spider处理Response并返回提取到的Item以及新的Request给ScrapyEngine;
8.ScrapyEngine将Spider返回的Item交给ItemPipeline,将Spider返回的Request交给Schedule进行从第二步开始的重复操作,直到调度器中没有待处理的Request,ScrapyEngine关闭。
安装scrapy:
1.安装wheel支持:
$ pip install wheel
2.安装scrapy框架:
$ pip install scrapy
3.window下,为了避免windows编译安装twisted依赖,安装下面的二进制包
$ pip install Twisted-18.4.0-cp35-cp35m-win_amd64.whl
scrapy项目结构:
在某路径下创建scrapy项目: $ scrapy startproject my_project
会产生以下目录和文件:
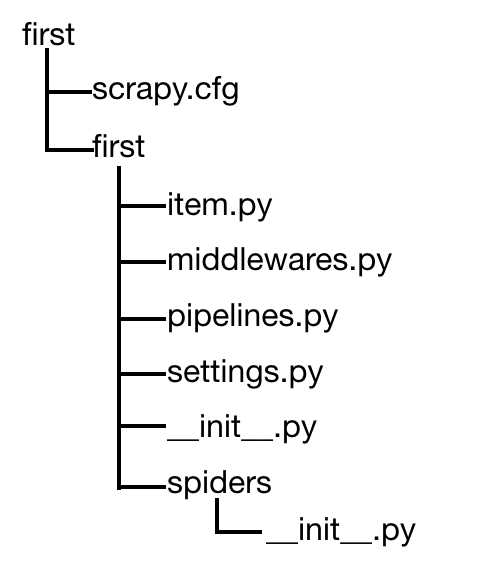
内部的first目录:整个项目的全局目录
item.py:定义Item类,从scrapy.Item继承,里面定义scrapy.Field类
pipelines.py:处理爬取的数据流向。重要的是process_item()方法
first目录下的__init__.py:作为包文件必须有的文件
spiders目录下的__init__.py:也是必须有。在这里可以写爬虫类或爬虫子模块
settings.py:
BOT_NAME # 爬虫名
ROBOTSTXT_OBEY = True # 遵守robots协议
USER_AGENT=‘‘ # 指定爬取时使用。一定要更改user-agent,否则访问会报403错误
CONCURRENT_REQUEST = 16 # 默认16个并行
DOWNLOAD_DELAY = 3 # 下载延时
COOKIES_ENABLED = False # 缺省是启用。一般需要登录时才需要开启cookie
DEFAULT_REQUEST_HEADERS = {} # 默认请求头,需要时填写
SPIDER_MIDDLEWARES # 爬虫中间件
DOWNLOADER_MIDDLEWARES # 下载中间件
‘first.middlewares.FirstDownloaderMiddleware‘: 543 # 543优先级越小越高
‘firstscrapy.pipelines.FirstscrapyPipeline‘: 300 # item交给哪一个管道处理,300优先级越小越高
豆瓣书评爬取:
创建爬虫代码模版
命令:scrapy genspider -t basic book douban.com # book是爬虫名字;douban.com是要爬取的url的域名
模板如下:
# -*- coding: utf-8 -*- import scrapy class BookSpider(scrapy.Spider): name = ‘book‘ allowed_domains = [‘douban.com‘] start_urls = [‘http://douban.com/‘] def parse(self, response): pass
此时就已经成功创建一个名为‘book’的爬虫,可以通过命令scrapy list查看。
response是服务器端HTTP响应,它是scrapy.http.response.html.HtmlResponse类。由此,修改代码如下 :
# -*- coding: utf-8 -*- import scrapy from scrapy.http.response.html import HtmlResponse class BookSpider(scrapy.Spider): name = ‘book‘ # 爬虫名 allowed_domains = [‘douban.com‘] # 域名。爬虫爬取范围 start_urls = [‘https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T‘] # 起始url,从第一页开始爬取 # 下载器获取WebServer的response,parse就是解析响应response的内容 def parse(self, response: HtmlResponse): # 如何解析html;返回一个可迭代对象:利用yiled print(type(response)) # scrapy.http.response.html.HtmlResponse print(type(response.text)) # str print(type(response.body)) # bytes print(response.encoding) # utf-8 # 将网页内容写入book.html文件内 with open(‘/Users/dannihong/Documents/leetcode/scrapy_project/file/book.html‘, ‘w‘, encoding=‘utf-8‘) as f: f.write(response.text) f.flush() except Exception as e: print(e)
爬虫获得的内容response对象,可以使用解析库来解析。scrapy包装了lxml,父类TextResponse类也提供了xpath方法和css方法,可以混合使用这两套接口解析HTML。解析html页面内容的示例代码如下:
# -*- coding: utf-8 -*- from scrapy.http.response.html import HtmlResponse response = HtmlResponse(‘file:/Users/dannihong/Documents/leetcode/scrapy_project/file/book.html‘, encoding=‘utf-8‘) with open(‘/Users/dannihong/Documents/leetcode/scrapy_project/file/book.html‘, encoding=‘utf8‘) as f: response._set_body(f.read().encode()) # _set_body方法将其放入response对象里;需要传入的参数对象是bytes,所以encode() subjects = response.css(‘li.subject-item‘) for subject in subjects: # 提取书籍的网页链接 href = subject.xpath(‘.//h2‘).css(‘a::attr(href)‘).extract() print(‘href:‘, href[0]) # 使用正则表达式,选取评分是9分以上的书籍 rate = subject.xpath(‘.//span[@class="rating_nums"]/text()‘).re(r‘^9.*‘) # rate = subject.css(‘span.rating_nums::text‘).re(r‘^9\..*‘) # 第二种表达方式 if rate: print(rate[0])
item封装数据:
# first/item.py
import scrapy class Test1ProItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() # 存放书籍标题的字段 rate = scrapy.Field() # 存放书籍评分的字段
# first/first/spiders/book.py
# -*- coding: utf-8 -*- import scrapy from scrapy.http.response.html import HtmlResponse from ..items import FirstItem # 从上一层的items.py文件里导入 class BookSpider(scrapy.Spider): name = ‘book‘ # 爬虫名 allowed_domains = [‘douban.com‘] # 爬虫爬取范围 start_urls = [‘https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T‘] # 起始url custom_settings = {‘file_name‘: ‘/Users/dannihong/Documents/leetcode/scrapy_project/file/books.json‘} # 一般设置参数 # 下载器获取WebServer的response,parse解析响应的内容;输出items和requests def parse(self, response: HtmlResponse): # 如何解析html;返回一个可迭代对象:利用yiled subjects = response.xpath(‘//li[@class="subject-item"]‘) items = [] # 如果用items=[],最后函数要return items for subject in subjects: item = FirstItem() # 声明一个item,相当于一个字典,存放要爬取的数据 title = subject.xpath(‘.//h2/a/text()‘).extract() item[‘title‘] = title[0].strip() rate = subject.css(‘span.rating_nums::text‘).extract() item[‘rate‘] = rate[0].strip() items.append(item) with open(‘book.json‘, ‘w‘, encoding=‘utf8‘) as f: for item in items: f.write(‘{} {}\n‘.format(item[‘title‘], item[‘rate‘])) return items
pipeline处理
将book.py中BookSpider改成生成器,只需要把return items改造成yield item,即由产生一个列表变成yield一个个item。脚手架帮我们创建了一个pipelines.py文件和一个类。
# Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { ‘first.pipelines.FirstPipeline‘: 300, }
整数300表示优先级,越小越高。取值范围为0-1000。
pipeline.py里常用的方法:
process_item(self, item, spider) # item表示爬取的一个个数据,spider表示item的爬取者,每一个item处理都得调用。返回一个item对象,或者抛出DropItem异常,被丢弃的item对象将不会被pipeline组件处理;
open_spider(self, spider) # spider表示被开启的spider,调用一次
close_spider(self, spider) # spider表示被关闭的spider,调用一次
__init__(self) # spider创建实例时调用一次
将爬取的数据通过pipeline写入到json文件中,代码如下:
# first/spiders/book.py
# -*- coding: utf-8 -*- import scrapy from scrapy.http.response.html import HtmlResponse from ..items import Test1ProItem class BookSpider(scrapy.Spider): name = ‘book‘ allowed_domains = [‘douban.com‘] start_urls = [‘https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T‘] custom_settings = {‘file_name‘: ‘/Users/dannihong/Documents/leetcode/scrapy_project/file/books.json‘} # spider上自定义配置信息 def parse(self, response: HtmlResponse): # 如何解析html;返回一个可迭代对象:利用yiled subjects = response.xpath(‘//li[@class="subject-item"]‘) for subject in subjects: item =FirstProItem() title = subject.xpath(‘.//h2/a/text()‘).extract() item[‘title‘] = title[0].strip() rate = subject.css(‘span.rating_nums::text‘).extract() item[‘rate‘] = rate[0].strip() yield item # 返回一个可迭代对象生成器
# first/pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import json from scrapy import Spider class Test1ProPipeline(object): def __int__(self): print(‘~~~~~~~~~~init~~~~~~~~~~‘) # 每一个item都会执行一次 def process_item(self, item, spider:Spider): print(‘++++++++++‘) print(item) self.file.write(‘{},\n‘.format(json.dumps(dict(item)))) return item # 所有过程在起始的时候执行一次 def open_spider(self, spider): print(‘==========open spider {}==========‘.format(spider)) # file_name = ‘/Users/dannihong/Documents/leetcode/scrapy_project/file/books.json‘ file_name = spider.settings[‘file_name‘] self.file = open(file_name, ‘w‘, encoding=‘utf-8‘) self.file.write(‘[\n‘) # 所有过程结束的时候执行一次 def close_spider(self, spider): print(‘==========close spider {}==========‘.format(spider)) self.file.write(‘]‘) self.file.close()
标签:pip tin 信息 ext html rop with open extra top
原文地址:https://www.cnblogs.com/hongdanni/p/10585671.html