标签:edr 管理 actor 测试 利用 处理 连接查询 term 等等
用户通过界面配置数据源,可能包括oracle、mysql、mongodb等等;配置完数据源后,支持对于具体数据源进行实时sql查询操作。
一般来说,如果不考虑性能,最简单的实现就是每次进行sql connecntion操作,实时连接查询。很显然,这样的操作,没有利用到数据库连接池。性能不好。所以 本篇博客的具体实现就是利用spring框架提供的AbstractRoutingDataSource类来实现动态的添加数据源。最终实现不同数据源的请求,都通过数据库连接池来实现。
本文通过原理剖析、实践操作,最后附上demo代码的github项目地址。
前面提到了spring框架提供的AbstractRoutingDataSource类,能够帮助我门实现动态的添加数据源。所以这边我们就先一起来看下这个接口的内部实现。
首先我们会发现这是一个抽象类,然后我们看一下它的依赖关系。可以看到两个关键,一个是它实现了DataSource接口,这个接口我们很熟悉,就是进行sql连接的核心类。另外一个是它实现了InitializingBean接口,这个接口的作用是进行初始化。
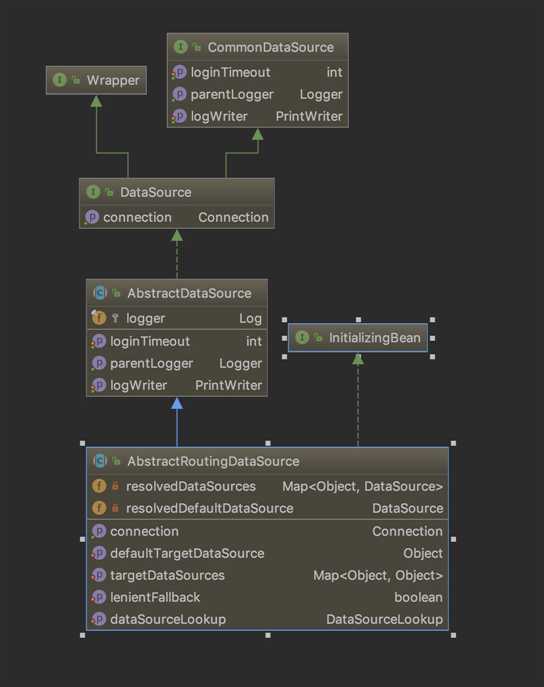
首先我们看下这个类的注释,好的注释基本能够说明很多事情。
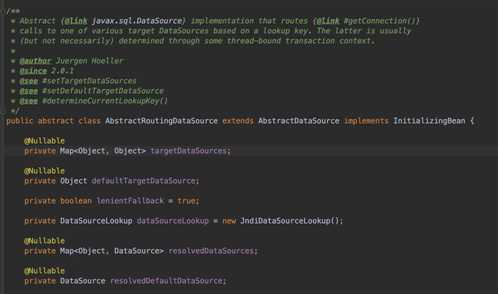
我来蹩脚翻一下,首先这个类是DataSource的一个抽象实现,它基于一个lookup key来实现目标数据源的调用。然后这个key一般(但是也不一定)通过一些线程绑定的事务上下文来确定。ok,我们能够掌握一个关键点,就是这个类是基于lookup key来进行目标数据源调用的。
前面提到AbstractRoutingDataSource类实现了InitializingBean接口,我们来看下这个接口的具体实现:
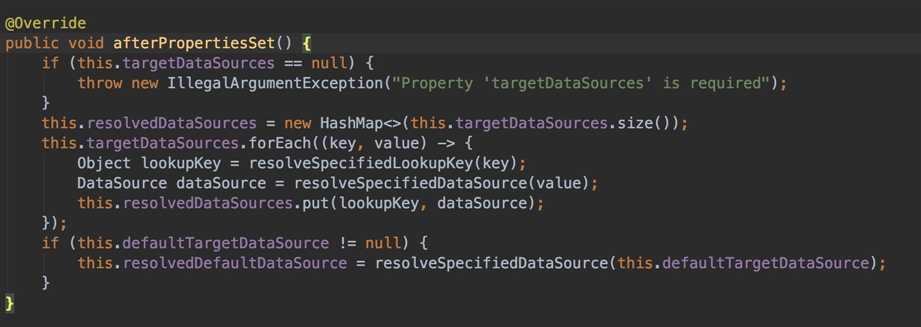
方法不复杂,简单介绍下:
这里为什么需要这么处理?我们可以看下resolveSpecifiedDataSource()这个解析方法。它这里做了一个判断,如果targetDataSources的value是string则会从Jndi数据源查找。
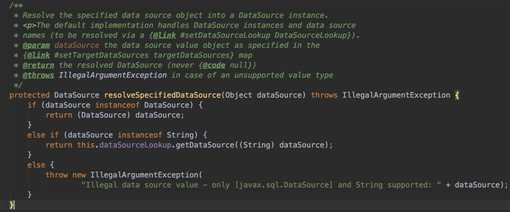
通过上述分析,我们知道一点,就是这个AbstractRoutingDataSource类必须有默认的数据源。否则初始化阶段就会报错。然后我们也发现它内部的targetDataSources其实是一个map,存储的就是lookup key 以及对应的DataSource对象。很自然的,我们可以想到,其实 所谓的动态数据源切换,其实就是 其内部 缓存了所有目标数据源,并且通过对应的key能够找到对应的数据源。
继续查看代码,我们需要找寻下,哪边去触发动态数据源的切换动作。我们知道这个AbstractRoutingDataSource是个抽象类,它是需要子类为其实现具体的方法的,所以我们就去看下它的抽象方法。可以看到,这个类就一个抽象方法:determineCurrentLookupKey()
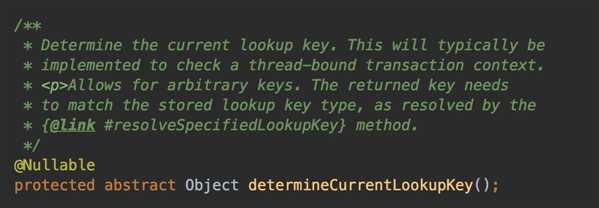
我们看下 调用这个抽象方法的地方,继续找线索。发现只有这个determineTargetDataSource()进行了调用。我们一起过下这个方法。方法的实现依然不复杂,就是获取对应的lookupkey,然后根据key去resolvedDataSource里获取解析的数据源对象,返回。
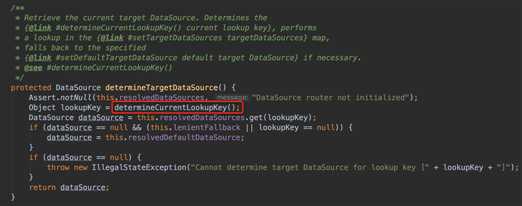
很明显,这就是我们想要的答案。动态数据源的切换,就是子类实现具体lookupKey的实现,然后就可以切换到对应的数据源对象了。这个AbstractRoutingDataSource,其实就是做的这个事情。
现在我们了解了AbstractRoutingDataSource类的作用,可以结合我们的原始需求来看下具体应该如何进行。
首先我们再回顾下原始需求,就是现在任何一个数据源的配置信息和sql过来,我们服务能够实现动态添加数据源到数据库连接池,进行数据库的查询。等到下次再次访问时,可以动态切换来查询。另外,如果注册的数据源,长时间不使用,我们也需要支持过期失效的操作。
上面的原始需求,简单概括下来,就是以下几个步骤:
根据上面我们对AbstractRoutingDataSource类的原理剖析,我们会发现,其实对于上述需求1和2,都是在对AbstractRoutingDataSource类里管理的数据源进行添加或者切换。所以我们需要基于这个关键类来实现我们的需求。
前面我们在分析AbstractRoutingDataSource类的时候,有提到,必须设置一个默认数据源。这里我们利用spring boot的配置文件进行默认数据源的配置。

然后通过Configuration类来进行配置,具体代码如下。利用@Bean进行动态数据源类的注册。在配置的核心实现里,需要将默认的配置数据源注册上去。其中lookupKey这里随便取了个默认名,只要保证后面动态添加的数据源与其不重复就ok了。
@Configuration
public class DataSourceConfigurer{
private static final Logger LOGGER = LoggerFactory.getLogger(DataSourceConfigurer.class);
@Value("${spring.datasource.url}")
private String url;
@Value("${spring.datasource.username}")
private String username;
@Value("${spring.datasource.password}")
private String password;
@Value("${spring.datasource.driverClassName}")
private String driverClassName;
public Map<String, Object> getProperties() {
Map<String, Object> map = new HashMap<>();
map.put("driverClassName", driverClassName);
map.put("url", url);
map.put("username", username);
map.put("password", password);
return map;
}
public DataSource dataSource() {
DataSource dataSource = null;
try {
dataSource = DruidDataSourceFactory.createDataSource(getProperties());
} catch (Exception e) {
LOGGER.error("Create DataSource Error : {}", e);
throw new RuntimeException();
}
return dataSource;
}
/**
* 注册动态数据源
*
* @return
*/
@Bean("dynamicDataSource")
public DynamicRoutingDataSource dynamicDataSource() {
DynamicRoutingDataSource dynamicRoutingDataSource = new DynamicRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>(1);
dataSourceMap.put("default_db", dataSource());
// 设置默认数据源
dynamicRoutingDataSource.setDefaultTargetDataSource(dataSource());
dynamicRoutingDataSource.setTargetDataSources(dataSourceMap);
return dynamicRoutingDataSource;
}
}这里的主要做法就是继承AbstractRoutingDataSource类。
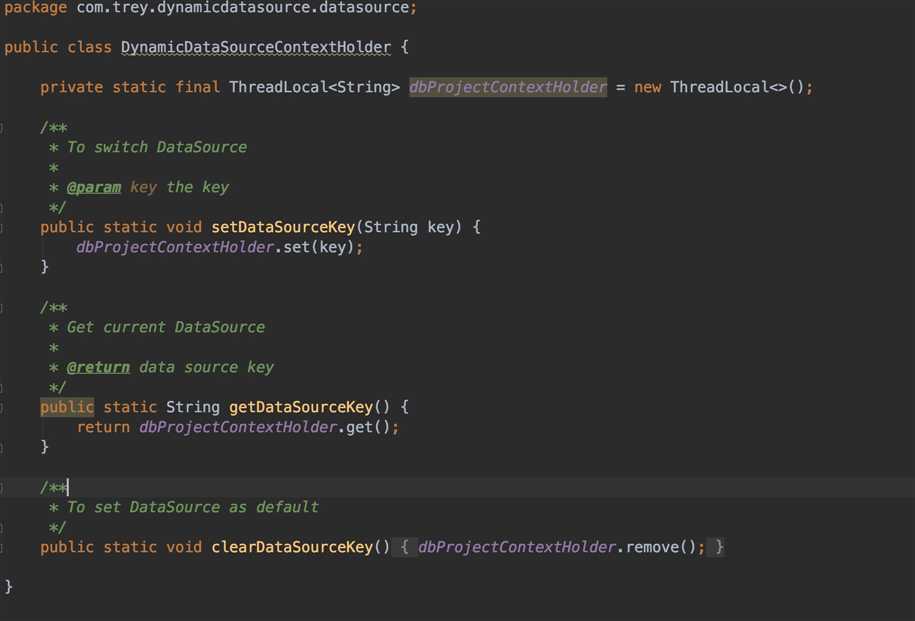
首先我们需要需要实现determineCurrentLookupKey()方法。前面的分析,我们已经知道该方法是获取目标数据源的lookupKey。所以这里涉及到lookupKey在上下文的存储。
这里我们使用ThreadLocal来实现lookupKey的管理。ThreadLocal适用于每个线程需要自己独立的实例且该实例需要在多个方法中被使用,也即变量在线程间隔离而在方法或类间共享的场景。所以很适合我们这里的场景。下面是具体的实现代码。
回到最原始的需求,结合目前获取的信息,我们可以整理下动态数据源查询的具体步骤:
以上步骤的核心,我们通过代码一步步演示。首先通过如下的代码,实现目标数据源的判断操作。这个判断也可以通过切面来实现,这边只是简单的集成在业务实现内部。
DynamicDataSourceContextHolder.setDataSourceKey(sqlInfoVO.getProjectId());
if(!DynamicRoutingDataSource.isExistDataSource(sqlInfoVO.getProjectId())) {
dynamicDataSource.addDataSource(sqlInfoVO);
}添加数据源的方法,主要就是先构建Connection连接进行测试,然后添加进AbstractRoutingDataSource的目标数据源map里。切记,添加完毕后,要进行afterPropertiesSet()操作,相当于刷新操作。
public synchronized boolean addDataSource(SqlInfoVO sqlInfoVO) {
try {
Connection connection = null;
// 排除连接不上的错误
try {
Class.forName(sqlInfoVO.getDriverClassName());
connection = DriverManager.getConnection(
sqlInfoVO.getUrl(),
sqlInfoVO.getUsername(),
sqlInfoVO.getPassword());
} catch (Exception e) {
e.printStackTrace();
return false;
} finally {
if (connection != null && !connection.isClosed()) {
connection.close();
}
}
//获取要添加的数据库名
String projectId = sqlInfoVO.getProjectId();
if (StringUtils.isBlank(projectId)) {
return false;
}
if (DynamicRoutingDataSource.isExistDataSource(projectId)) {
return true;
}
DruidDataSource druidDataSource = (DruidDataSource) DruidDataSourceFactory.createDataSource(beanToMap(sqlInfoVO));
druidDataSource.init();
Map<Object, Object> targetMap = DynamicRoutingDataSource.targetTargetDataSources;
targetMap.put(projectId, druidDataSource);
this.setTargetDataSources(targetMap);
this.afterPropertiesSet();
logger.info("dataSource [{}] has been added" + projectId);
} catch (Exception e) {
logger.error(e.getMessage());
return false;
}
return true;
}关于获取lookupKey的实现,应该很容易了,就是通过ThreadLocal去上下文获取。这里看到进行了updateTimer()操作,这个操作是为了数据源的连接过期断开而设定的。
// 每次设置当前数据源key时,更新timeMap中的时间
String lookupKey = DynamicDataSourceContextHolder.getDataSourceKey();
updateTimer(lookupKey);
return lookupKey;根据以上的实现,其实我们已经实现了数据源的动态添加和切换操作。然而我们还需要考虑下,对于部分很少甚至只连接一次的数据源,其实是没必要一直缓存的。所以我们需要实现一个过期检测的操作。
具体的功能,这里实现的思路是:
这里面核心的操作涉及到三块,首先是需要构建一个带有时间戳的数据源扩展类:
public class DynamicDataSourceTimer {
/**
* 空闲时间周期。超过这个时长没有访问的数据库连接将被释放。默认为10分钟。
*/
private static long idlePeriodTime = 10 * 60 * 1000;
/**
* 动态数据源
*/
private DataSource dds;
/**
* 上一次访问的时间
*/
private long lastUseTime;
public DynamicDataSourceTimer(DataSource dds) {
this.dds = dds;
this.lastUseTime = System.currentTimeMillis();
}
/**
* 更新最近访问时间
*/
public void refreshTime() {
lastUseTime = System.currentTimeMillis();
}
/**
* 检测数据连接是否超时关闭。
*
* @return true-已超时关闭; false-未超时
*/
public boolean checkAndClose() {
if (System.currentTimeMillis() - lastUseTime > idlePeriodTime)
{
return true;
}
return false;
}
}构建一个定时任务,这里我们利用spring的@Schedula注解实现:
/**
* 通过定时任务周期性清除不使用的数据源
*/
@Scheduled(initialDelay= 10 * 60 * 1000, fixedRate= 10 * 60 * 1000)
public void clearTask() {
// 遍历timetMap,判断
clearIdleDDS();
}
private void clearIdleDDS() {
timerMap.forEach((k,v) -> {
if(v.checkAndClose()) {
delDatasources(k.toString());
}
});实现一个移除数据源的方法,其核心依然在于更新AbstractRoutingDataSource的AbstractRoutingDataSource:
// 删除数据源
public synchronized boolean delDatasources(String datasourceid) {
Map<Object, Object> dynamicTargetDataSources2 = DynamicRoutingDataSource.targetTargetDataSources;
if (dynamicTargetDataSources2.containsKey(datasourceid)) {
Set<DruidDataSource> druidDataSourceInstances = DruidDataSourceStatManager.getDruidDataSourceInstances();
for (DruidDataSource l : druidDataSourceInstances) {
if (datasourceid.equals(l.getName())) {
System.out.println(l);
dynamicTargetDataSources2.remove(datasourceid);
DruidDataSourceStatManager.removeDataSource(l);
// 将map赋值给父类的TargetDataSources
setTargetDataSources(dynamicTargetDataSources2);
// 将TargetDataSources中的连接信息放入resolvedDataSources管理
super.afterPropertiesSet();
return true;
}
}
return false;
} else {
return false;
}
}基于上述的实现和分析,我整理了一个完整的demo项目:
https://github.com/trey-tao/spring-dynamic-datasource-demo
标签:edr 管理 actor 测试 利用 处理 连接查询 term 等等
原文地址:https://www.cnblogs.com/trey/p/10610172.html