标签:hint sem 类别 多个 通用 efficient 文章 ber teacher
teacher student net
顾名思义:就是老师和学生的网络,也就是老师训练好,然后教学生去怎么训练
这里着重介绍两篇论文,
第一篇是hinton的paper:Distilling the Knowledge in a Neural Network
第二篇是阿里的一个paper:Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net\
首先讲第一篇paper的思路:
这篇文章主要是两个contribution:
1 提出了一个knowledge distilling 的过程,也就是知识蒸馏,具体的思路先训练一个大的精准的网络,然后让这个大的网络去教这个小的网络怎么学习
2提出一种新的集成模型(esemble of models),包括一个通用模型(Generalist Model)和多个专用模型(Specialist Models),其中,专用模型用来对那些通用模型无法区分的细粒度(Fine-grained)类别的图像进行区分
1先介绍几个名词:
hard targets:标签(0,1,0,1,1.......)
soft targets:经过softmax的结果(0.99,0.01,0.02,0.98......),并且这个softmax的结果还可以进一步soft,
1什么是进一步soft
2 为什么能进一步soft
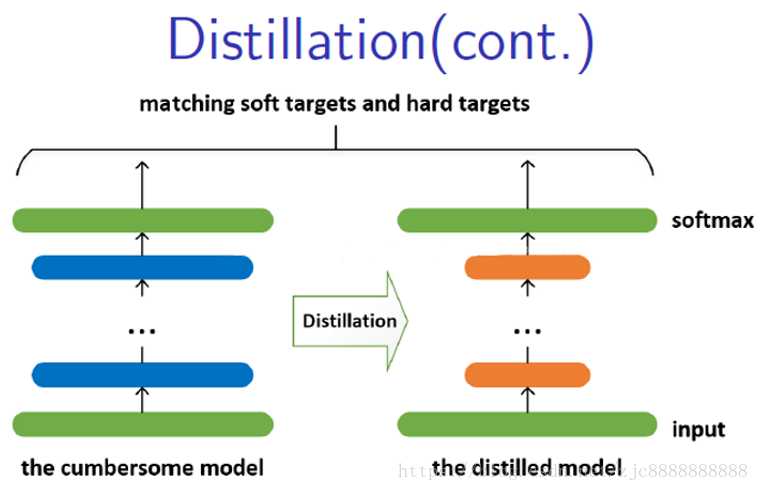
流程:
1 先用一个大的网络(cumber)也就是复杂的网络去做分类,标签是hard target(1,0,1,0)也就是正常的学习
2再用一个小的网络,标签是
标签:hint sem 类别 多个 通用 efficient 文章 ber teacher
原文地址:https://www.cnblogs.com/lllcccddd/p/10651236.html