标签:normal 基于 fit 统计 call coding cpi pat def
目录
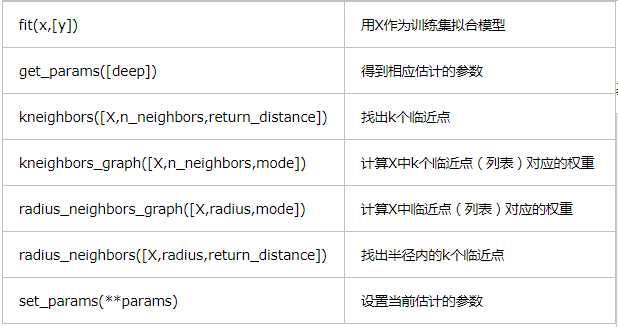
sklearn.neighbors.NearestNeighbors
参数/方法
基础用法
用于监督学习
检测异常操作(一)
检测异常操作(二)
检测rootkit
检测webshell
sklearn.neighbors.NearestNeighbors
参数:

方法:
基础用法
print(__doc__) from sklearn.neighbors import NearestNeighbors import numpy as np X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) nbrs = NearestNeighbors(n_neighbors=2, algorithm=‘ball_tree‘).fit(X) distances, indices = nbrs.kneighbors(X) #indeices邻节点,distances邻节点距离 print(‘邻节点距离\n‘,distances) print(‘邻节点\n‘, indices) print(nbrs.kneighbors_graph(X).toarray())
邻节点距离 [[ 0. 1. ] [ 0. 1. ] [ 0. 1.41421356] [ 0. 1. ] [ 0. 1. ] [ 0. 1.41421356]] 邻节点 [[0 1] [1 0] [2 1] [3 4] [4 3] [5 4]] 可视化结果 [[ 1. 1. 0. 0. 0. 0.] [ 1. 1. 0. 0. 0. 0.] [ 0. 1. 1. 0. 0. 0.] [ 0. 0. 0. 1. 1. 0.] [ 0. 0. 0. 1. 1. 0.] [ 0. 0. 0. 0. 1. 1.]]
用于监督学习
sklearn.neighbors.KNeighborsClassifier
使用很简单,三步:1)创建KNeighborsClassifier对象,2)调用fit函数,3)调用predict/predict_proba函数进行预测。
#predict返回概率最大的预测值
#predict_proba返回的是一个n行k列的数组, 第i行j列上的数值是模型预测第i个预测样本为某个标签的概率,并且每一行的概率和为1。
from sklearn.neighbors import KNeighborsClassifier x=[[0],[1],[2],[3]] y=[0,0,1,1] neigh = KNeighborsClassifier(n_neighbors=3) neigh.fit(x,y) print(neigh.predict([[1.1]])) print(neigh.predict_proba([[0.9]]))
[0] [[ 0.66666667 0.33333333]]
检测异常操作(一)
# -*- coding:utf-8 -*- import numpy as np import nltkfrom nltk.probability import FreqDistfrom sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import classification_report from sklearn import metrics #测试样本数 N=100 """ 数据收集和数据清洗(清洗换行符\n) 从scholaon数据集的user3文件导入信息;一百条命令组成一个列表x[],最终组成二维列表cmd_set[[]]; 返回二维列表,最频繁50条命令,和最不频繁50条命令 """ def load_user_cmd(filename): cmd_set=[] dist_max=[] dist_min=[] dist=[] with open(filename) as f: i=0 x=[] for line in f: line=line.strip(‘\n‘) x.append(line) dist.append(line) i+=1 if i == 100: cmd_set.append(x) x=[] i=0 fdist = list(FreqDist(dist).keys()) dist_max=set(fdist[0:50]) dist_min = set(fdist[-50:]) return cmd_set,dist_max,dist_min """ 特征化 将load_user_cmd函数的输出作为输入; 以100个命令为统计单元,作为一个操作序列,去重后的操作命令个数作为特征;(函数FreqDist会统计每个单词的频度,重新整合成一个+1维度的新的列表) KNN只能以标量作为输入参数,所以需要将f2和f3表量化,最简单的方式就是和统计的最频繁使用的前50个命令以及最不频繁使用的前50个命令计算重合程度。 返回一个150×3的列表;3里的0:不重复单词的个数,1:最频繁单词重合程度<=min{10,50},2最不频繁单词重合程度<=min{10,50} """ def get_user_cmd_feature(user_cmd_set,dist_max,dist_min): user_cmd_feature=[] for cmd_block in user_cmd_set: f1=len(set(cmd_block)) fdist = list(FreqDist(cmd_block).keys()) f2=fdist[0:10] f3=fdist[-10:] f2 = len(set(f2) & set(dist_max)) f3=len(set(f3) & set(dist_min)) x=[f1,f2,f3] user_cmd_feature.append(x) return user_cmd_feature """ 训练模型 导入标识文件,100×50,正常命令为0,异常命令为1; 从标识文件中加载针对操作序列正确/异常的标识 返回一个容量为150的list 0/1数值,(只要这一行有1) """ def get_label(filename,index=0): x=[] with open(filename) as f: for line in f: line=line.strip(‘\n‘)#清空每行的\n x.append(int(line.split()[index]))#???? return x if __name__ == ‘__main__‘: user_cmd_set,user_cmd_dist_max,user_cmd_dist_min=load_user_cmd("../data/MasqueradeDat/User3") user_cmd_feature=get_user_cmd_feature(user_cmd_set,user_cmd_dist_max,user_cmd_dist_min) labels=get_label("../data/MasqueradeDat/label.txt",2) y=[0]*50+labels#y长度150,labels长度100 x_train=user_cmd_feature[0:N] y_train=y[0:N] x_test=user_cmd_feature[N:150] y_test=y[N:150] neigh = KNeighborsClassifier(n_neighbors=3) neigh.fit(x_train, y_train) y_predict=neigh.predict(x_test) score=np.mean(y_test==y_predict)*100 #print(y) #print(y_train) print(‘y_test\n‘,y_test) print(‘y_predict\n‘,y_predict) print(‘score\n‘,score) print(‘classification_report(y_test, y_predict)\n‘,classification_report(y_test, y_predict)) print(‘metrics.confusion_matrix(y_test, y_predict)\n‘,metrics.confusion_matrix(y_test, y_predict))
y_test [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] y_predict [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] score 100.0 classification_report(y_test, y_predict) precision recall f1-score support 0 1.00 1.00 1.00 30 avg / total 1.00 1.00 1.00 30 metrics.confusion_matrix(y_test, y_predict) [[30]]
检测异常操作(二)
上例只比较了最频繁和最不频繁的操作命令,这次我们全量比较。
# -*- coding:utf-8 -*- import sys import urllib #import urlparse import re #from hmmlearn import hmm import numpy as np from sklearn.externals import joblib #import HTMLParser import nltk import csv import matplotlib.pyplot as plt from nltk.probability import FreqDist from sklearn.feature_extraction.text import CountVectorizer from sklearn.neighbors import KNeighborsClassifier from sklearn import cross_validation #测试样本数 N=90 """ 数据搜集和数据清洗(清洗换行符) 返回cmd_list:150×100的二维列表和fdist:去重的字符串集 """ def load_user_cmd_new(filename): cmd_list=[] dist=[] with open(filename) as f: i=0 x=[] for line in f: line=line.strip(‘\n‘) x.append(line) dist.append(line) i+=1 if i == 100: cmd_list.append(x) x=[] i=0 fdist = FreqDist(dist).keys() return cmd_list,fdist """ 特征化 使用词集将操作命令向量化 """ def get_user_cmd_feature_new(user_cmd_list,dist): user_cmd_feature=[] for cmd_list in user_cmd_list: v=[0]*len(dist) for i in range(0,len(dist)): if list(dist)[i] in list(cmd_list): v[i]+=1 user_cmd_feature.append(v) return user_cmd_feature def get_label(filename,index=0): x=[] with open(filename) as f: for line in f: line=line.strip(‘\n‘) x.append( int(line.split()[index])) return x if __name__ == ‘__main__‘: """ 训练模型 """ user_cmd_list,dist=load_user_cmd_new("../data/MasqueradeDat/User3") print( "len(dist):%d" % len(dist)) print( "dist:%s" % dist) user_cmd_feature=get_user_cmd_feature_new(user_cmd_list,dist) labels=get_label("../data/MasqueradeDat/label.txt",2) y=[0]*50+labels x_train=user_cmd_feature[0:N] y_train=y[0:N] x_test=user_cmd_feature[N:150] y_test=y[N:150] neigh = KNeighborsClassifier(n_neighbors=3) neigh.fit(x_train, y_train) y_predict=neigh.predict(x_test) """ 交叉验证效果,10次随机取样和验证 """ print(cross_validation.cross_val_score(neigh,user_cmd_feature, y, n_jobs=-1,cv=10))
len(dist):107 dist:dict_keys([‘Xsession‘, ‘sed‘, ‘grep‘, ‘wc‘, ‘date‘, ‘uname‘, ‘true‘, ‘xsetroot‘, ‘cpp‘, ‘sh‘, ‘xrdb‘, ‘cat‘, ‘stty‘, ‘basename‘, ‘ksh‘, ‘tail‘, ‘xmodmap‘, ‘ls‘, ‘hostname‘, ‘netstat‘, ‘netscape‘, ‘xterm‘, ‘sccs‘, ‘get‘, ‘diff‘, ‘more‘, ‘.java_wr‘, ‘expr‘, ‘dirname‘, ‘egrep‘, ‘java‘, ‘make‘, ‘mailx‘, ‘pq‘, ‘bdiff‘, ‘delta‘, ‘ex‘, ‘rm‘, ‘javac‘, ‘mkdir‘, ‘man‘, ‘od‘, ‘ln‘, ‘cfe‘, ‘ugen‘, ‘as1‘, ‘driver‘, ‘ld_‘, ‘readacct‘, ‘touch‘, ‘bc‘, ‘sendmail‘, ‘seecalls‘, ‘FvwmPage‘, ‘GoodStuf‘, ‘fvwm‘, ‘xdm‘, ‘chmod‘, ‘id‘, ‘nawk‘, ‘getopt‘, ‘lp‘, ‘find‘, ‘FIFO‘, ‘generic‘, ‘pr‘, ‘postprin‘, ‘file‘, ‘post‘, ‘awk‘, ‘getpgrp‘, ‘LOCK‘, ‘gethost‘, ‘download‘, ‘tcpostio‘, ‘UNLOCK‘, ‘rmdir‘, ‘tcppost‘, ‘cpio‘, ‘xargs‘, ‘gzip‘, ‘jar‘, ‘nslookup‘, ‘rlogin‘, ‘xhost‘, ‘admin‘, ‘runnit‘, ‘gs‘, ‘ppost‘, ‘hpost‘, ‘tracerou‘, ‘unpack‘, ‘col‘, ‘telnet‘, ‘ptelnet‘, ‘tset‘, ‘logname‘, ‘matlab‘, ‘launchef‘, ‘MediaMai‘, ‘a.out‘, ‘dbx‘, ‘dbxpcs‘, ‘mimencod‘, ‘sim301bS‘, ‘sim301bK‘, ‘ps‘]) [ 1. 1. 0.93333333 1. 1. 1. 1. 1. 0.93333333 0.92857143]
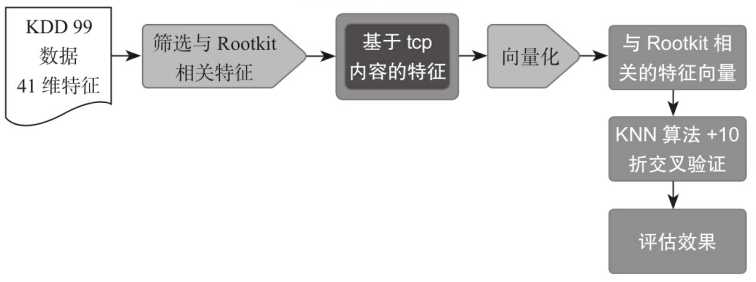
检测Rootkit(三)
Rootkit是一种特殊的恶意软件,它的功能是在安装目标上隐藏自身及指定的文件,进程和网络链接等信息,比较常见的是Rootkit,一般都和木马,后门等其他恶意程序结合使用。
基于KDD 99的样本数据,尝试使用KNN算法识别基于telnet连接的Rootkit行为,检测流程如下所示。
# -*- coding:utf-8 -*- from sklearn import cross_validation from sklearn.neighbors import KNeighborsClassifier """ 数据集已经完成了大部分的清洗工作; 41个特征描述 加载KDD 99数据集中的数据 """ def load_kdd99(filename): x=[] with open(filename) as f: for line in f: line=line.strip(‘\n‘) line=line.split(‘,‘) x.append(line) return x """ 特征化 """ def get_rootkit2andNormal(x): v=[] w=[] y=[] for x1 in x: if ( x1[41] in [‘rootkit.‘,‘normal.‘] ) and ( x1[2] == ‘telnet‘ ): if x1[41] == ‘rootkit.‘: y.append(1) else: y.append(0) """ 挑选与Rootkit相关的特征作为样本特征 """ x1 = x1[9:21] v.append(x1) for x1 in v : v1=[] for x2 in x1: v1.append(float(x2)) w.append(v1) return w,y if __name__ == ‘__main__‘: v=load_kdd99("../data/kddcup99/corrected") x,y=get_rootkit2andNormal(v) """ 训练样本 """ clf = KNeighborsClassifier(n_neighbors=3) """ 效果验证 """ print(cross_validation.cross_val_score(clf, x, y, n_jobs=-1, cv=10))
[ 0.9 0.9 1. 1. 1. 0.77777778 1. 1. 1. 1. ]
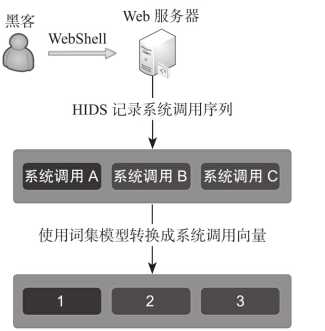
检测Webshell(四)
使用ADFA-LD数据集中webshell相关数据,ADFA-LD数据集中记录下了系统调用序列(比如A,B,C),然后使用数字标识每一个系统调用(1,2,3),这时(1,2,3)就转换成了一个序列向量。
以下是系统调用的顺序抽象成序列向量的过程
# -*- coding:utf-8 -*- import re import os import numpy as np from sklearn.feature_extraction.text import CountVectorizer from sklearn import cross_validation from sklearn.neighbors import KNeighborsClassifier def load_one_flle(filename): x=[] with open(filename) as f: line=f.readline() line=line.strip(‘\n‘) return line #加载ADFA-LD中的正常样本数据 def load_adfa_training_files(rootdir): x=[] y=[] list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isfile(path): x.append(load_one_flle(path)) y.append(0) return x,y #定义遍历目录下文件的函数 def dirlist(path, allfile): filelist = os.listdir(path) for filename in filelist: filepath = os.path.join(path, filename) if os.path.isdir(filepath): dirlist(filepath, allfile) else: allfile.append(filepath) return allfile #从攻击数据集中筛选和webshell相关的数据 def load_adfa_webshell_files(rootdir): x=[] y=[] allfile=dirlist(rootdir,[]) for file in allfile: #此处小心,前部分分隔符为/,web_shell_x后为 if re.match(r"../data/ADFA-LD/Attack_Data_Master/Web_Shell_\d+\\UAD-W*",file): x.append(load_one_flle(file)) y.append(1) return x,y if __name__ == ‘__main__‘: x1,y1=load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/") x2,y2=load_adfa_webshell_files("../data/ADFA-LD/Attack_Data_Master/") x=x1+x2 y=y1+y2 #print(x) vectorizer = CountVectorizer(min_df=1) x=vectorizer.fit_transform(x) x=x.toarray() #print(y) clf = KNeighborsClassifier(n_neighbors=3) scores=cross_validation.cross_val_score(clf, x, y, n_jobs=-1, cv=10) print(scores) print(np.mean(scores))
[ 0.95833333 0.94791667 0.97916667 0.96842105 0.96842105 0.84210526 0.97894737 0.98947368 0.9787234 0.9787234 ] 0.959023189623
参考:
标签:normal 基于 fit 统计 call coding cpi pat def
原文地址:https://www.cnblogs.com/p0pl4r/p/10671100.html