标签:程序 amp info 展示 正文 dmi ini 路径 desktop
制作LMDB详细教程
摘要:
当我们在使用Caffe做深度学习项目时,经常需要制作Caffe常用的数据类型lmdb、leveldb以及hdf5等(尽管可以使用原始图片,效率低),而不是我们常见的JPG、PNG、TIF。因此,我们需要对我们采集的数据进行格式转换,即通过输入我们自己的图片目录(包含有训练集和验证集的大量图片)转换成一个lmdb库文件的输出;这个过程一般是有Caffe工具中的convert_imageset,该工具在编译过的Caffe中,具体位置是:D:\你的caffe根目录\caffe\caffe-windows\Build\Int\convert_imageset(这里其实没啥用,不要管它)。
开始正文:
格式转换的4个必要条件:
(1)编译好Caffe,而且convert_imageset存在;
(2)需要被转换的图像和目录,注意它们是有要求的(请看稍后的文件目录架构);
(3)在将图像转换为lmdb格式之前,首先生成两个标签文件train.txt和val.txt(具体格式见下文);
(4)运行编辑修改好的create_imagenet.sh(最好将其制到你的项目文件夹下,不修改原始文件)生成lmdb文件。
所在位置:D:\你的caffe根目录\caffe\caffe-windows\examples\imagenet
1. 数据集的组织架构(文件目录结构)
接下来,我将会使用一个例子详细介绍即将要使用的数据集的目录结构。这里制作的是一个分类数据集,主要包括两个类别:dog和cat,我们用数字0表示cat的类别,数字1来表示dog类别。在总目录data_set文件夹下,包括两个子文件夹分别是train和val,它们分别存储着训练集和验证集的所有图片。在train文件夹下 也包含两个子文件夹,它们分别是“0”和“1”,里面分别存储的是dog和cat的所有图像。在val的文件夹下没有子文件夹(其实也可以像train一样),直接是将要用于验证的图像数据,我们可以根据图像的名字知道它所属的类别,便于写出val.txt文件。鉴于这一步是格式转换的基础,我将整个目录详细结构用图展示如下:
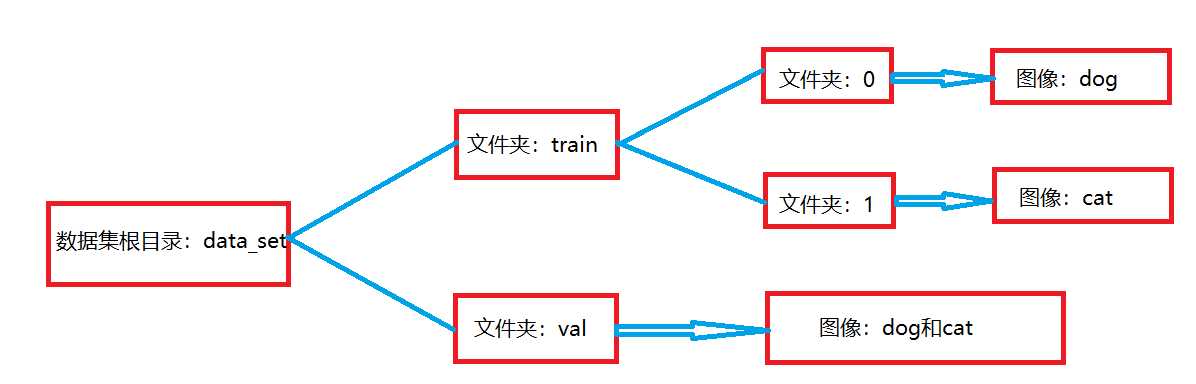
(1)数据集根目录所在路径:C:\Users\Administrator\Desktop

(2)data_set的子文件夹:C:\Users\Administrator\Desktop\data_set
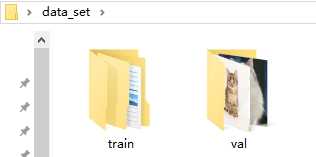
(3)train的子文件夹:C:\Users\Administrator\Desktop\data_set\train
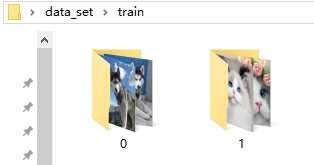
(a)“0”文件夹下的文件:C:\Users\Administrator\Desktop\data_set\train\0
这里图片文件的名字其实可以随意,因为文件夹就指出了它所属的类别。
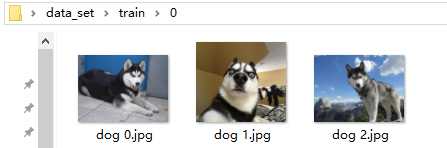
(b)“1”文件夹下的文件:C:\Users\Administrator\Desktop\data_set\train\1
这里图片文件的名字其实可以随意,因为文件夹就指出了它所属的类别。

(4)val的子文件夹:C:\Users\Administrator\Desktop\data_set\val
这里的图像文件的名字必须可以判断它所属的类别,我们使用python中的split()函数可以将文件名以“_”分隔开来获取图像所属类别,具体见程序。

至此,我已经详细介绍了整个数据集的详细目录结构,我相信这已经足够详细啦!接下来,我们开始更至关重要的一步操作。
Caffe系列2——制作LMDB数据详细过程(手把手教你制作LMDB)
标签:程序 amp info 展示 正文 dmi ini 路径 desktop
原文地址:https://www.cnblogs.com/xiaoboge/p/10678658.html