标签:res properly sys reac 指定 注意 img logger 临时表
在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:通过Spark的数据源进行创建;从一个存在的RDD进行转换;还可以从Hive Table进行查询返回。
读取json文件创建DataFrame
spark读取json按行读取;只要一行符合json的格式即可;
scala> val rdd = spark.read.json("/opt/module/spark/spark-local/examples/src/main/resources/people.json") rdd: org.apache.spark.sql.DataFrame = [age: bigint, name: string] scala> rdd.show +----+-------+ | age| name| +----+-------+ |null|Michael| | 30| Andy| | 19| Justin| +----+-------+
① SQL风格语法
##转化成sql去执行
scala> rdd.createTempView("user") //view是table的查询结果,只能查不能改 scala> spark.sql("select * from user").show +----+-------+ | age| name| +----+-------+ |null|Michael| | 30| Andy| | 19| Justin| +----+-------+ scala> spark.sql("select * from user where age is not null").show +---+------+ |age| name| +---+------+ | 30| Andy| | 19|Justin| +---+------+
注意:普通临时view是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.people
scala> rdd.createGlobalTempView("emp") //提升为全局 scala> spark.sql("select * from user where age is not null").show +---+------+ |age| name| +---+------+ | 30| Andy| | 19|Justin| +---+------+ scala> spark.sql("select * from emp where age is not null").show //sql默认从当前session中查找,所以查询时需要加上global_temp org.apache.spark.sql.AnalysisException: Table or view not found: emp; line 1 pos 14 scala> spark.sql("select * from global_temp.emp where age is not null").show +---+------+ |age| name| +---+------+ | 30| Andy| | 19|Justin| +---+------+
② 以面向对象方式访问;DSL风格语法 模仿面向对象的方式
scala> rdd.printSchema root |-- age: long (nullable = true) |-- name: string (nullable = true) scala> rdd.select("age").show +----+ | age| +----+ |null| | 30| | 19| +----+ scala> rdd.select($"age"+1).show +---------+ |(age + 1)| +---------+ | null| | 31| | 20| +---------+
RDD转成DF
注意:如果需要RDD与DF或者DS之间操作,那么都需要引入 import spark.implicits._ 【spark不是包名,而是sparkSession对象的名称】
前置条件:导入隐式转换并创建一个RDD
scala> import spark.implicits._ spark对象中的隐式转换规则,而不是导入包名 import spark.implicits._
scala> val df = rdd.toDF("id", "name") df: org.apache.spark.sql.DataFrame = [id: bigint, name: string] scala> df.show +----+-------+ | id| name| +----+-------+ |null|Michael| | 30| Andy| | 19| Justin| +----+-------+ scala> df.createTempView("Student") scala> spark.sql("select * from student").show
scala> val x = sc.makeRDD(List(("a",1), ("b",4), ("c", 3))) scala> x.collect res36: Array[(String, Int)] = Array((a,1), (b,4), (c,3)) scala> x.toDF("name", "count") res37: org.apache.spark.sql.DataFrame = [name: string, count: int] scala> val y = x.toDF("name", "count") y: org.apache.spark.sql.DataFrame = [name: string, count: int] scala> y.show +----+-----+ |name|count| +----+-----+ | a | 1| | b | 4| | c | 3| +----+-----+
scala> y.rdd.collect res46: Array[org.apache.spark.sql.Row] = Array([a,1], [b,4], [c,3]) scala> df.rdd.collect res49: Array[org.apache.spark.sql.Row] = Array([null,Michael], [30,Andy], [19,Justin])
SparkSQL能够自动将包含有case类的RDD转换成DataFrame,case类定义了table的结构,case类属性通过反射变成了表的列名。Case类可以包含诸如Seqs或者Array等复杂的结构。 DataSet是具有强类型的数据集合,需要提供对应的类型信息。
scala> case class People(age: BigInt, name: String) defined class People scala> rdd.collect res77: Array[org.apache.spark.sql.Row] = Array([null,Michael], [30,Andy], [19,Justin]) scala> val ds = rdd.as[People] ds: org.apache.spark.sql.Dataset[People] = [age: bigint, name: string] scala> ds.collect res31: Array[People] = Array(People(null,Michael), People(30,Andy), People(19,Justin))
scala> case class Person(name: String, age: Long) defined class Person scala> val caseclassDS = Seq(Person("kris", 20)).toDS() caseclassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint] scala> caseclassDS.show +----+---+ |name|age| +----+---+ |kris| 20| +----+---+ scala> caseclassDS.collect res51: Array[Person] = Array(Person(kris,20))
通过textFile方法创建rdd并转DS
scala> val textFileRDD = sc.textFile("/opt/module/spark/spark-local/examples/src/main/resources/people.txt") scala> textFileRDD.collect res78: Array[String] = Array(Michael, 29, Andy, 30, Justin, 19) scala> case class Person(name: String, age: Long) defined class Person scala> textFileRDD.map(x=>{val rddMap = x.split(","); Person(rddMap(0), rddMap(1).trim.toInt)}).toDS res80: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
DataSet转换为RDD 调用rdd方法即可
scala> val DS = Seq(Person("Andy", 32)).toDS() 用这种方式可创建一个DataSet DS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint] scala> ds.collect res76: Array[People] = Array(People(null,Michael), People(30,Andy), People(19,Justin)) scala> ds.rdd.collect res75: Array[People] = Array(People(null,Michael), People(30,Andy), People(19,Justin))
DF ---> DS
spark.read.json(“ path ”)即是DataFrame类型;
scala> df.collect res72: Array[org.apache.spark.sql.Row] = Array([null,Michael], [30,Andy], [19,Justin]) scala> case class Student(id: BigInt, name: String) defined class Student scala> df.as[Student] res69: org.apache.spark.sql.Dataset[Student] = [id: bigint, name: string]
DS-->DF
这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型是DataFrame又需要针对各个字段处理时极为方便。在使用一些特殊的操作时,一定要加上 import spark.implicits._ 不然toDF、toDS无法使用。
scala> ds.collect res73: Array[People] = Array(People(null,Michael), People(30,Andy), People(19,Justin)) scala> ds.toDF res74: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
(1)RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利;
(2)三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算;
(3)三者有许多共同的函数,如filter,排序等;
(4)在对DataFrame和Dataset进行操作许多操作都需要这个包:import spark.implicits._(在创建好SparkSession对象后尽量直接导入)
互相转化
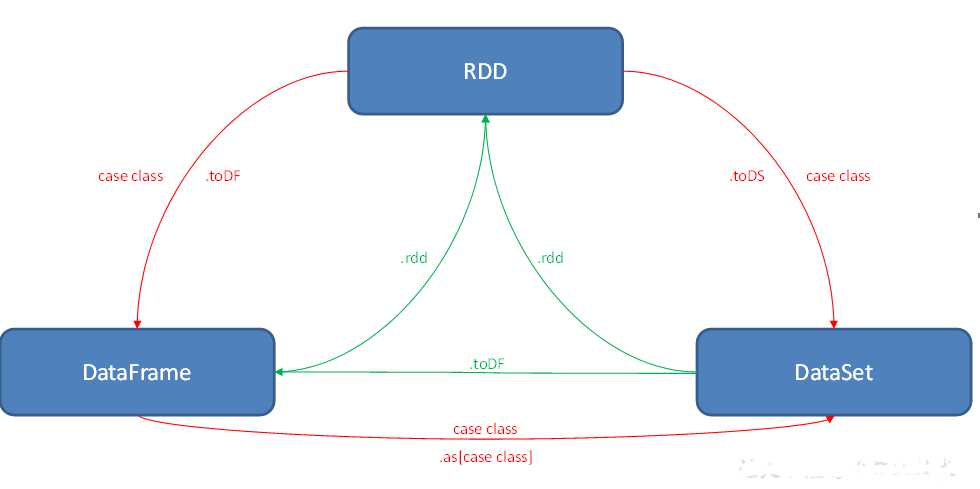
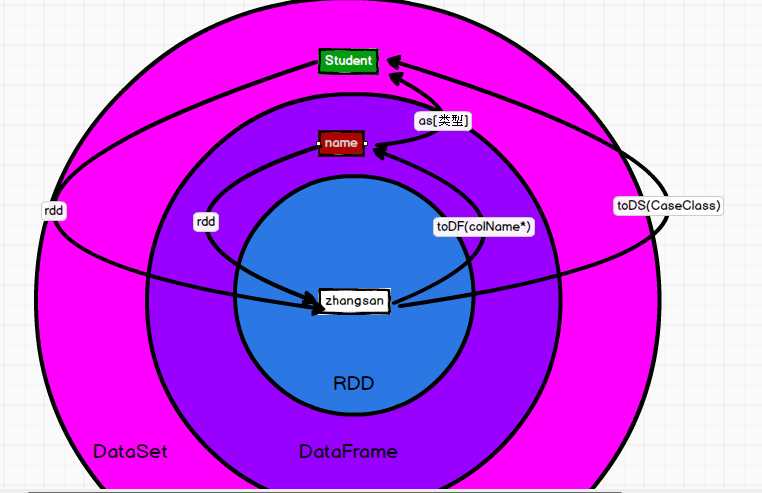

通用的读写方法是 sparkSql只读这parquet file这种类型的文件; 否则要改变它的文件类型需要加.format
加上format("json");输出也是这个类型
scala>val df = spark.read.load("/opt/module/spark/spark-local/examples/src/main/resources/users.parquet").show scala>df.select("name", " color").write.save("user.parquet") //保存数据 java.lang.RuntimeException: file:/opt/module/spark/spark-local/examples/src/main/resources/people.json is not a Parquet file. 用load读取json数据 scala> spark.read.format("json").load("/opt/module/spark/spark-local/examples/src/main/resources/people.json").show df.write.format("json").save("/..") spark.read.format("json").mode("overwrite").save("/..json")
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
可在启动shell时指定相关的数据库驱动路径,或者将相关的数据库驱动放到spark的类路径下。
[kris@hadoop101 jars]$ cp /opt/software/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar ./ scala> val connectionProperties = new java.util.Properties() connectionProperties: java.util.Properties = {} scala> connectionProperties.put("user", "root") res0: Object = null scala> connectionProperties.put("password", "123456") res1: Object = null scala> val jdbcDF2 = spark.read.jdbc("jdbc:mysql://hadoop101:3306/rdd", "test", connectionProperties) jdbcDF2: org.apache.spark.sql.DataFrame = [id: int, name: string] scala> jdbcDF2.show +---+-------+ | id| name| +---+-------+ | 1| Google| | 2| Baidu| | 3| Ali| | 4|Tencent| | 5| Amazon| +---+-------+ jdbcDF2.write.mode("append").jdbc("jdbc:mysql://hadoop101:3306/rdd", "test", connectionProperties) scala> val rdd = sc.makeRDD(Array((6, "FaceBook"))) rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[4] at makeRDD at <console>:24 scala> rdd.toDF("id", "name") res5: org.apache.spark.sql.DataFrame = [id: int, name: string] scala> val df = rdd.toDF("id", "name") df: org.apache.spark.sql.DataFrame = [id: int, name: string] scala> df.show +---+--------+ | id| name| +---+--------+ | 6|FaceBook| +---+--------+ scala> df.write.mode("append").jdbc("jdbc:mysql://hadoop101:3306/rdd", "test", connectionProperties) scala> jdbcDF2.show +---+--------+ | id| name| +---+--------+ | 1| Google| | 2| Baidu| | 3| Ali| | 4| Tencent| | 5| Amazon| | 6|FaceBook| +---+--------+
Apache Hive是Hadoop上的SQL引擎,Spark SQL编译时可以包含Hive支持,也可以不包含。包含Hive支持的Spark SQL可以支持Hive表访问、UDF(用户自定义函数)以及Hive查询语言(HQL)等。spark-shell默认是Hive支持的;代码中是默认不支持的,需要手动指定(加一个参数即可)。
如果要使用内嵌的Hive,什么都不用做,直接用就可以了。
可以修改其数据仓库地址,参数为:--conf spark.sql.warehouse.dir=./wear
scala> spark.sql("create table emp(name String, age Int)").show 19/04/11 01:10:17 WARN HiveMetaStore: Location: file:/opt/module/spark/spark-local/spark-warehouse/emp specified for non-external table:emp scala> spark.sql("load data local inpath ‘/opt/module/spark/spark-local/examples/src/main/resources/people.txt‘ into table emp").show scala> spark.sql("show tables").show +--------+---------+-----------+ |database|tableName|isTemporary| +--------+---------+-----------+ | default| emp| false| +--------+---------+-----------+ scala> spark.sql("select * from emp").show /opt/module/spark/spark-local/spark-warehouse/emp [kris@hadoop101 emp]$ ll -rwxr-xr-x. 1 kris kris 32 4月 11 01:10 people.txt
外部Hive应用
[kris@hadoop101 spark-local]$ rm -rf metastore_db/ spark-warehouse/ [kris@hadoop101 conf]$ cp hive-site.xml /opt/module/spark/spark-local/conf/ [kris@hadoop101 spark-local]$ bin/spark-shell scala> spark.sql("show tables").show +--------+--------------------+-----------+ |database| tableName|isTemporary| +--------+--------------------+-----------+ | default| bigtable| false| | default| business| false| | default| dept| false| | default| dept_partition| false| | default| dept_partition2| false| | default| dept_partitions| false| | default| emp| false| ... [kris@hadoop101 spark-local]$ bin/spark-sql log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell). log4j:WARN Please initialize the log4j system properly. spark-sql (default)> show tables;
代码中操作Hive
val sparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate() 支持hive
标签:res properly sys reac 指定 注意 img logger 临时表
原文地址:https://www.cnblogs.com/shengyang17/p/10683487.html