标签:led ade EDA charset sts erro abs user create
业务场景:
现在项目中需要通过对spark对原始数据进行计算,然后将计算结果写入到mysql中,但是在写入的时候有个限制:
1、mysql中的目标表事先已经存在,并且当中存在主键,自增长的键id
2、在进行将dataFrame写入表的时候,id字段不允许手动写入,因为其实自增长的
要求:
1、写入数据库的时候,需要指定字段写入,也就是说,只指定部分字段写入
2、在写入数据库的时候,对于操作主键相同的记录要实现更新操作,非插入操作
分析:
spark本身提供了对dataframe的写入数据库的操作,即:
/**
* SaveMode is used to specify the expected behavior of saving a DataFrame to a data source.
*
* @since 1.3.0
*/
public enum SaveMode {
/**
* Append mode means that when saving a DataFrame to a data source, if data/table already exists,
* contents of the DataFrame are expected to be appended to existing data.
*
* @since 1.3.0
*/
Append,
/**
* Overwrite mode means that when saving a DataFrame to a data source,
* if data/table already exists, existing data is expected to be overwritten by the contents of
* the DataFrame.
*
* @since 1.3.0
*/
Overwrite,
/**
* ErrorIfExists mode means that when saving a DataFrame to a data source, if data already exists,
* an exception is expected to be thrown.
*
* @since 1.3.0
*/
ErrorIfExists,
/**
* Ignore mode means that when saving a DataFrame to a data source, if data already exists,
* the save operation is expected to not save the contents of the DataFrame and to not
* change the existing data.
*
* @since 1.3.0
*/
Ignore
}
但是,显然这种方式写入的时候,需要我们的dataFrame中的每个字段都需要对mysql目标表中相对应,在写入的时候需要全部字段都写入,这是种方式简单,但是这不符合我们的业务需求,所以我们需要换一种思路,也就是说,如果我们能够通过自定义insert语句的方式,也就是说通过jdbc的方式进行写入数据,那就更好了。这样也更符合我们的业务需求。
具体实现(开发环境:IDEA):
实现方式:通过c3p0连接池的方式进行数据的写入,这样我们就可以直接通过自己拼接sql,来实现我们需要插入数据库的指定的字段值,当然这种方式实现起来也比较繁琐。
第一步:
我们需要先导入响应的依赖包:
sbt项目导入方式:
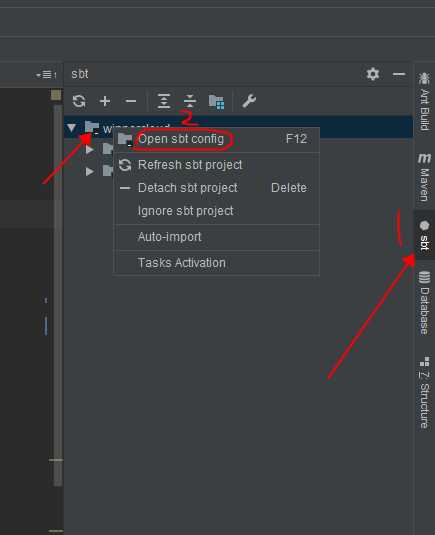
打开build.sbt文件
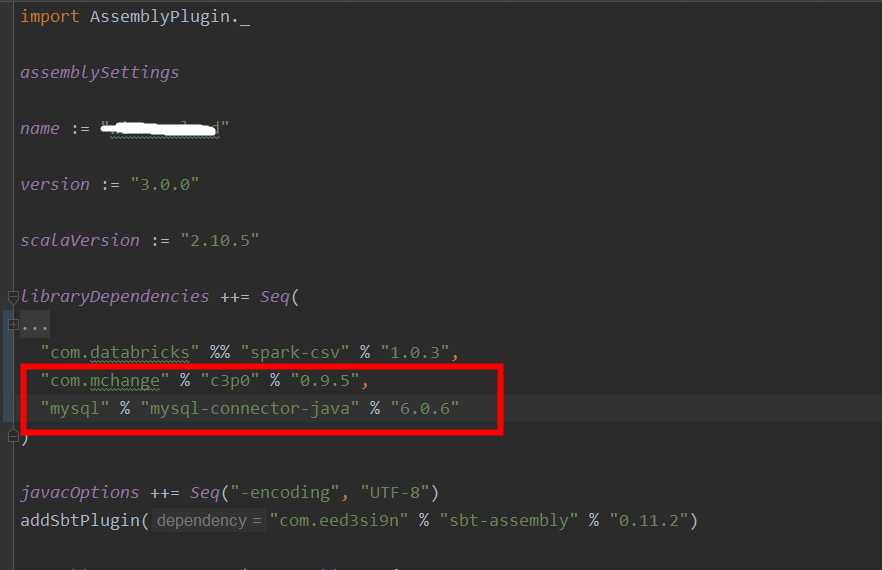
在红色框出进行添加即可
maven项目导入方式:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>6.0.6</version>
</dependency>
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.5</version>
</dependency>
我习惯与将关于数据库操作的几个库类放到单独的一个BDUtils包中
第一步:定义读取配置文件的类
package cn.com.xxx.audit.DBUtils
import java.util.Properties
object PropertiyUtils {
def getFileProperties(fileName: String, propertityKey: String): String = {
val result = this.getClass.getClassLoader.getResourceAsStream(fileName)
val prop = new Properties()
prop.load(result)
prop.getProperty(propertityKey)
}
}
第二步:定义一个配置文件(db.properties),将该文件放在resource目录中,并且内容使用"="进行连接
mysql.jdbc.url=jdbc:mysql://localhost:3306/test?serverTimezone=UTC mysql.jdbc.host=127.0.0.1 mysql.jdbc.port=3306 mysql.jdbc.user=root mysql.jdbc.password=123456 mysql.pool.jdbc.minPoolSize=20 mysql.pool.jdbc.maxPoolSize=50 mysql.pool.jdbc.acquireIncrement=10 mysql.pool.jdbc.maxStatements=50 mysql.driver=com.mysql.jdbc.Driver
第三步:定义一个连接池的类,负责获取配置文件,并创建数据库连接池
package cn.com.xxx.audit.DBUtils
import java.sql.Connection
import com.mchange.v2.c3p0.ComboPooledDataSource
class MySqlPool extends Serializable {
private val cpds: ComboPooledDataSource = new ComboPooledDataSource(true)
try {
cpds.setJdbcUrl(PropertiyUtils.getFileProperties("db.properties", "mysql.jdbc.url"))
cpds.setDriverClass(PropertiyUtils.getFileProperties("db.properties", "mysql.driver"))
cpds.setUser(PropertiyUtils.getFileProperties("db.properties", "mysql.jdbc.user"))
cpds.setPassword(PropertiyUtils.getFileProperties("db.properties", "mysql.jdbc.password"))
cpds.setMinPoolSize(PropertiyUtils.getFileProperties("db.properties", "mysql.pool.jdbc.minPoolSize").toInt)
cpds.setMaxPoolSize(PropertiyUtils.getFileProperties("db.properties", "mysql.pool.jdbc.maxPoolSize").toInt)
cpds.setAcquireIncrement(PropertiyUtils.getFileProperties("db.properties", "mysql.pool.jdbc.acquireIncrement").toInt)
cpds.setMaxStatements(PropertiyUtils.getFileProperties("db.properties", "mysql.pool.jdbc.maxStatements").toInt)
} catch {
case e: Exception => e.printStackTrace()
}
def getConnection: Connection = {
try {
cpds.getConnection()
} catch {
case ex: Exception =>
ex.printStackTrace()
null
}
}
def close() = {
try {
cpds.close()
} catch {
case ex: Exception =>
ex.printStackTrace()
}
}
}
第四步:创建连接池管理器对象,用来获取数据库连接
package cn.com.winner.audit.DBUtils
object MySqlPoolManager {
var mysqlManager: MySqlPool = _
def getMysqlManager: MySqlPool = {
synchronized {
if (mysqlManager == null) {
mysqlManager = new MySqlPool
}
}
mysqlManager
}
}
第五步:对数据库的操作对象
package cn.com.winner.audit.DBUtils
import java.sql.{Date, Timestamp}
import java.util.Properties
import org.apache.log4j.Logger
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, SQLContext}
object OperatorMySql {
val logger: Logger = Logger.getLogger(this.getClass.getSimpleName)
/**
* 将dataframe所有类型(除id外)转换为string后,通过c3p0的连接池方式,向mysql写入数据
*
* @param tableName 表名
* @param resultDateFrame datafream
*/
def saveDFtoDBUsePool(tableName: String, resultDateFrame: DataFrame): Unit = {
val colNumbsers = resultDateFrame.columns.length
val sql = getInsertSql(tableName, colNumbsers)
val columnDataTypes = resultDateFrame.schema.fields.map(_.dataType)
resultDateFrame.foreachPartition(partitionRecords => {
val conn = MySqlPoolManager.getMysqlManager.getConnection
val prepareStatement = conn.prepareStatement(sql)
val metaData = conn.getMetaData.getColumns(null, "%", tableName, "%")
try {
conn.setAutoCommit(false)
partitionRecords.foreach(record => {
for (i <- 1 to colNumbsers) {
val value = record.get(i - 1)
val dateType = columnDataTypes(i - 1)
if (value != null) {
prepareStatement.setString(i, value.toString)
dateType match {
case _: ByteType => prepareStatement.setInt(i, record.getAs[Int](i - 1))
case _: ShortType => prepareStatement.setInt(i, record.getAs[Int](i - 1))
case _: IntegerType => prepareStatement.setInt(i, record.getAs[Int](i - 1))
case _: LongType => prepareStatement.setLong(i, record.getAs[Long](i - 1))
case _: BooleanType => prepareStatement.setBoolean(i, record.getAs[Boolean](i - 1))
case _: FloatType => prepareStatement.setFloat(i, record.getAs[Float](i - 1))
case _: DoubleType => prepareStatement.setDouble(i, record.getAs[Double](i - 1))
case _: StringType => prepareStatement.setString(i, record.getAs[String](i - 1))
case _: TimestampType => prepareStatement.setTimestamp(i, record.getAs[Timestamp](i - 1))
case _: DateType => prepareStatement.setDate(i, record.getAs[Date](i - 1))
case _ => throw new RuntimeException("nonsupport $ {dateType} !!!")
}
} else {
metaData.absolute(i)
prepareStatement.setNull(i, metaData.getInt("DATA_TYPE"))
}
}
prepareStatement.addBatch()
})
prepareStatement.executeBatch()
conn.commit()
} catch {
case e: Exception => println(s"@@ saveDFtoDBUsePool ${e.getMessage}")
} finally {
prepareStatement.close()
conn.close()
}
})
}
/**
* 拼接sql
*/
def getInsertSql(tableName: String, colNumbers: Int): String = {
var sqlStr = "insert into " + tableName + "values("
for (i <- 1 to colNumbers) {
sqlStr += "?"
if (i != colNumbers) {
sqlStr += ","
}
}
sqlStr += ")"
sqlStr
}
/**
* 以元祖的额方式返回mysql属性信息
*
* @return
*/
def getMysqlInfo: (String, String, String) = {
val jdbcURL = PropertiyUtils.getFileProperties("", "")
val userName = PropertiyUtils.getFileProperties("", "")
val password = PropertiyUtils.getFileProperties("", "")
(jdbcURL, userName, password)
}
/**
* 从mysql中获取dataframe
*
* @param sqlContext sqlContext
* @param mysqlTableName 表名
* @param queryCondition 查询条件
* @return
*/
def getDFFromeMysql(sqlContext: SQLContext, mysqlTableName: String, queryCondition: String = ""): DataFrame = {
val (jdbcURL, userName, password) = getMysqlInfo
val prop = new Properties()
prop.put("user", userName)
prop.put("password", password)
//scala中其实equals和==是相同的,并不跟java中一样
if (null == queryCondition || "" == queryCondition) {
sqlContext.read.jdbc(jdbcURL, mysqlTableName, prop)
} else {
sqlContext.read.jdbc(jdbcURL, mysqlTableName, prop).where(queryCondition)
}
}
/**
* 删除数据表
*
* @param SQLContext
* @param mysqlTableName
* @return
*/
def dropMysqlTable(SQLContext: SQLContext, mysqlTableName: String): Boolean = {
val conn = MySqlPoolManager.getMysqlManager.getConnection
val preparedStatement = conn.createStatement()
try {
preparedStatement.execute(s"drop table $mysqlTableName")
} catch {
case e: Exception =>
println(s"mysql drop MysqlTable error:${e.getMessage}")
false
} finally {
preparedStatement.close()
conn.close()
}
}
/**
* 从表中删除数据
*
* @param SQLContext
* @param mysqlTableName 表名
* @param condition 条件,直接从where后面开始
* @return
*/
def deleteMysqlTableData(SQLContext: SQLContext, mysqlTableName: String, condition: String): Boolean = {
val conn = MySqlPoolManager.getMysqlManager.getConnection
val preparedStatement = conn.createStatement()
try {
preparedStatement.execute(s"delete from $mysqlTableName where $condition")
} catch {
case e: Exception =>
println(s"mysql delete MysqlTableNameData error:${e.getMessage}")
false
} finally {
preparedStatement.close()
conn.close()
}
}
/**
* 保存dataframe到mysql中,如果表不存在的话,会自动创建
*
* @param tableName
* @param resultDataFrame
*/
def saveDFtoDBCreateTableIfNotExists(tableName: String, resultDataFrame: DataFrame) = {
//如果没有表,根据dataframe建表
createTableIfNotExist(tableName, resultDataFrame)
//验证数据表字段和dataframe字段个数和名称,顺序是否一致
verifyFieldConsistency(tableName, resultDataFrame)
//保存df
saveDFtoDBUsePool(tableName, resultDataFrame)
}
/**
* 如果表不存在则创建
*
* @param tableName
* @param df
* @return
*/
def createTableIfNotExist(tableName: String, df: DataFrame): AnyVal = {
val conn = MySqlPoolManager.getMysqlManager.getConnection
val metaData = conn.getMetaData
val colResultSet = metaData.getColumns(null, "%", tableName, "%")
//如果没有该表,创建数据表
if (!colResultSet.next()) {
//构建表字符串
val sb = new StringBuilder(s"create table `$tableName`")
df.schema.fields.foreach(x => {
if (x.name.equalsIgnoreCase("id")) {
//如果字段名是id,则设置为主键,不为空,自增
sb.append(s"`${x.name}` int(255) not null auto_increment primary key,")
} else {
x.dataType match {
case _: ByteType => sb.append(s"`${x.name}` int(100) default null,")
case _: ShortType => sb.append(s"`${x.name}` int(100) default null,")
case _: IntegerType => sb.append(s"`${x.name}` int(100) default null,")
case _: LongType => sb.append(s"`${x.name}` bigint(100) default null,")
case _: BooleanType => sb.append(s"`${x.name}` tinyint default null,")
case _: FloatType => sb.append(s"`${x.name}` float(50) default null,")
case _: DoubleType => sb.append(s"`${x.name}` double(50) default null,")
case _: StringType => sb.append(s"`${x.name}` varchar(50) default null,")
case _: TimestampType => sb.append(s"`${x.name}` timestamp default current_timestamp,")
case _: DateType => sb.append(s"`${x.name}` date default null,")
case _ => throw new RuntimeException(s"non support ${x.dataType}!!!")
}
}
})
sb.append(") engine = InnDB default charset=utf8")
val sql_createTable = sb.deleteCharAt(sb.lastIndexOf(‘,‘)).toString()
println(sql_createTable)
val statement = conn.createStatement()
statement.execute(sql_createTable)
}
}
/**
* 拼接insertOrUpdate语句
*
* @param tableName
* @param cols
* @param updateColumns
* @return
*/
def getInsertOrUpdateSql(tableName: String, cols: Array[String], updateColumns: Array[String]): String = {
val colNumbers = cols.length
var sqlStr = "insert into " + tableName + "("
for (i <- 1 to colNumbers) {
sqlStr += cols(i - 1)
if (i != colNumbers) {
sqlStr += ","
}
}
sqlStr += ") values("
for (i <- 1 to colNumbers) {
sqlStr += "?"
if (i != colNumbers) {
sqlStr += ","
}
}
sqlStr += ") on duplicate key update "
updateColumns.foreach(str => {
sqlStr += s"$str=?,"
})
sqlStr.substring(0, sqlStr.length - 1)
}
/**
*
* @param tableName
* @param resultDateFrame 要入库的dataframe
* @param updateColumns 要更新的字段
*/
def insertOrUpdateDFtoDBUserPool(tableName: String, resultDateFrame: DataFrame, updateColumns: Array[String]): Boolean = {
var status = true
var count = 0
val colNumbsers = resultDateFrame.columns.length
val sql = getInsertOrUpdateSql(tableName, resultDateFrame.columns, updateColumns)
val columnDataTypes = resultDateFrame.schema.fields.map(_.dataType)
println(s"\n$sql")
resultDateFrame.foreachPartition(partitionRecords => {
val conn = MySqlPoolManager.getMysqlManager.getConnection
val prepareStatement = conn.prepareStatement(sql)
val metaData = conn.getMetaData.getColumns(null, "%", tableName, "%")
try {
conn.setAutoCommit(false)
partitionRecords.foreach(record => {
//设置需要插入的字段
for (i <- 1 to colNumbsers) {
val value = record.get(i - 1)
val dateType = columnDataTypes(i - 1)
if (value != null) {
prepareStatement.setString(i, value.toString)
dateType match {
case _: ByteType => prepareStatement.setInt(i, record.getAs[Int](i - 1))
case _: ShortType => prepareStatement.setInt(i, record.getAs[Int](i - 1))
case _: IntegerType => prepareStatement.setInt(i, record.getAs[Int](i - 1))
case _: LongType => prepareStatement.setLong(i, record.getAs[Long](i - 1))
case _: BooleanType => prepareStatement.setBoolean(i, record.getAs[Boolean](i - 1))
case _: FloatType => prepareStatement.setFloat(i, record.getAs[Float](i - 1))
case _: DoubleType => prepareStatement.setDouble(i, record.getAs[Double](i - 1))
case _: StringType => prepareStatement.setString(i, record.getAs[String](i - 1))
case _: TimestampType => prepareStatement.setTimestamp(i, record.getAs[Timestamp](i - 1))
case _: DateType => prepareStatement.setDate(i, record.getAs[Date](i - 1))
case _ => throw new RuntimeException("nonsupport $ {dateType} !!!")
}
} else {
metaData.absolute(i)
prepareStatement.setNull(i, metaData.getInt("Data_Type"))
}
}
//设置需要 更新的字段值
for (i <- 1 to updateColumns.length) {
val fieldIndex = record.fieldIndex(updateColumns(i - 1))
val value = record.get(i)
val dataType = columnDataTypes(fieldIndex)
println(s"\n更新字段值属性索引: $fieldIndex,属性值:$value,属性类型:$dataType")
if (value != null) {
dataType match {
case _: ByteType => prepareStatement.setInt(colNumbsers + i, record.getAs[Int](fieldIndex))
case _: ShortType => prepareStatement.setInt(colNumbsers + i, record.getAs[Int](fieldIndex))
case _: IntegerType => prepareStatement.setInt(colNumbsers + i, record.getAs[Int](fieldIndex))
case _: LongType => prepareStatement.setLong(colNumbsers + i, record.getAs[Long](fieldIndex))
case _: BooleanType => prepareStatement.setBoolean(colNumbsers + i, record.getAs[Boolean](fieldIndex))
case _: FloatType => prepareStatement.setFloat(colNumbsers + i, record.getAs[Float](fieldIndex))
case _: DoubleType => prepareStatement.setDouble(colNumbsers + i, record.getAs[Double](fieldIndex))
case _: StringType => prepareStatement.setString(colNumbsers + i, record.getAs[String](fieldIndex))
case _: TimestampType => prepareStatement.setTimestamp(colNumbsers + i, record.getAs[Timestamp](fieldIndex))
case _: DateType => prepareStatement.setDate(colNumbsers + i, record.getAs[Date](fieldIndex))
case _ => throw new RuntimeException(s"no support ${dataType} !!!")
}
} else {
metaData.absolute(colNumbsers + i)
prepareStatement.setNull(colNumbsers + i, metaData.getInt("data_Type"))
}
}
prepareStatement.addBatch()
count += 1
})
//批次大小为100
if (count % 100 == 0) {
prepareStatement.executeBatch()
}
conn.commit()
} catch {
case e: Exception =>
println(s"@@ ${e.getMessage}")
status = false
} finally {
prepareStatement.executeBatch()
conn.commit()
prepareStatement.close()
conn.close()
}
})
status
}
/**
* 验证属性是否存在
*/
def verifyFieldConsistency(tableName: String, df: DataFrame) = {
val conn = MySqlPoolManager.getMysqlManager.getConnection
val metaData = conn.getMetaData
val colResultSet = metaData.getColumns(null, "%", tableName, "%")
colResultSet.last()
val tableFieldNum = colResultSet.getRow
val dfFieldNum = df.columns.length
if (tableFieldNum != dfFieldNum) {
throw new Exception("")
}
for (i <- 1 to tableFieldNum) {
colResultSet.absolute(i)
val tableFieldName = colResultSet.getString("column_name")
val dfFieldName = df.columns.apply(i - 1)
if (tableFieldName.equals(dfFieldName)) {
throw new Exception("")
}
}
colResultSet.beforeFirst()
}
}
第六步:调用对应的方法,对数据库进行自定义增删改查,而不是通过dataFrame自带的api对数据库操作,这样更加的灵活。
package cn.com.xxx.audit
import cn.com.winner.audit.DBUtils.{OperatorMySql, PropertiyUtils}
import cn.com.winner.common.until.{DateOperator, DateUtil}
import org.apache.spark.HashPartitioner
import org.apache.spark.sql.DataFrame
/**
* 持久化数据
*/
object SaveData {
/**
* DF数据写入mysql结果表
*
* @param tableName 保存的表名
* @param ResultDFs 需要保存的DF
* @param updateCols 更新的字段
* @return
*/
def saveToMysql(tableName: String, ResultDFs: Array[DataFrame], updateCols: Array[String]) = {
//将DataFrmae进行合并
val resultDF = LoadData.mergeDF(ResultDFs.toVector)
//这里直接调用OperatorMysql的insert方法,使用拼接sql的方式进行对数据库进行插入操作
OperatorMySql.insertOrUpdateDFtoDBUserPool(tableName, resultDF, updateCols)
}
}
对于第五步中的sql拼接,我只是根据我的需求进行拼接,我们可以根据自己不同的需求对sql进行拼接,并且调用不同的方法对dataFrame进行操作。
Spark操作dataFrame进行写入mysql,自定义sql的方式
标签:led ade EDA charset sts erro abs user create
原文地址:https://www.cnblogs.com/Gxiaobai/p/10652338.html