标签:asn 官网 down 安装包 func str stc actor xmx
spark-windows(含eclipse配置)下本地开发环境搭建
>>>>>>注意:这里忽略JDK的安装,JDK要求是1.8及以上版本,请通过 java –version查看。
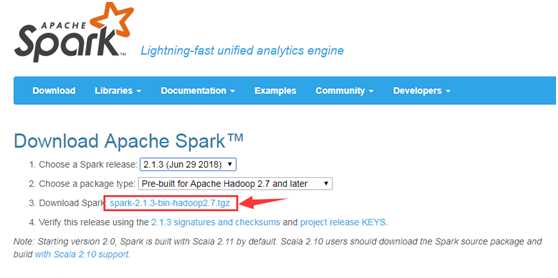
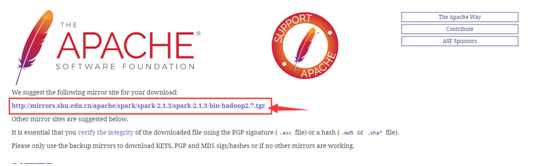
到官网http://spark.apache.org/downloads.html选择相应版本,下载安装包。我这里下的是2.1.3版本,后面安装的Hadoop版本需要跟Spark版本对应。下载后找个合适的文件夹解压即可。这里新建了一个home文件夹,底下放了spark, hadoop解压后的目录:
other_jars 是用来存放一些自己开发中用到的jar包
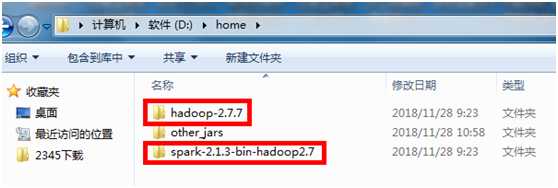
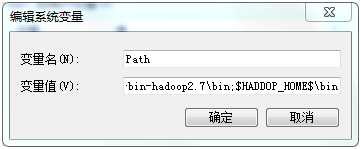
解压之后配置环境变量,将Spark底下的bin文件所在的目录添加到环境变量的Path变量中,后面Hadoop也一样。
配置SPARK_HOME
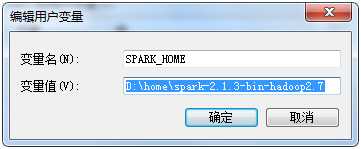
配置PATH D:\home\spark-2.1.3-bin-hadoop2.7\bin;
也可以使用SPARK_HOME
到这里Spark算是安装成功。
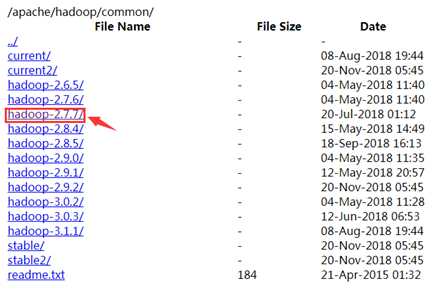
到http://mirrors.hust.edu.cn/apache/hadoop/common/下载相应版本的Hadoop安装包,我下的是2.7.7。具体的Spark和Hadoop版本对应可以到网上查,Spark和Hadoop版本不一致可能会导致出问题。
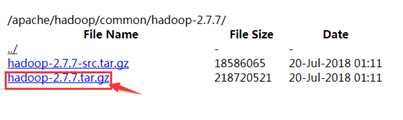
将下载好的安装包进行解压,然后将Hadoop下的bin目录配置到Path变量中。
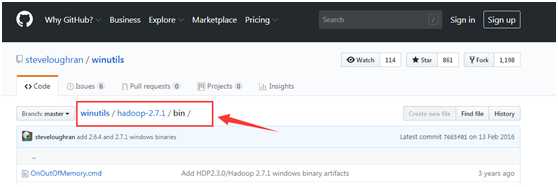
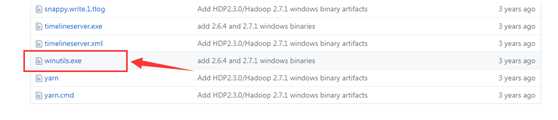
为了防止运行程序的时候出现nullpoint异常,到github下载 winutils.exe 下载地址:https://github.com/steveloughran/winutils
找到对应的hadoop版本,然后进入bin目录下,下载winutils.exe, 然后复制到hadoop的bin目录下。
系统环境变量配置:
HADOOP_HOME:
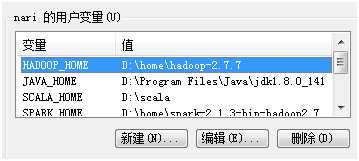
Path: $HADDOP_HOME$\bin
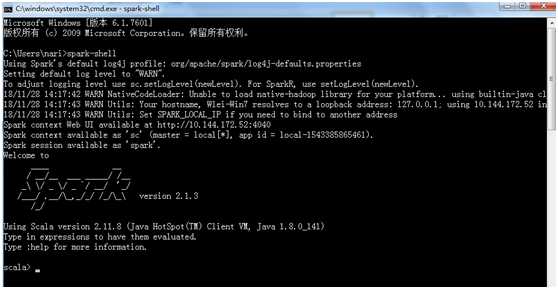
到官网https://www.scala-lang.org/download/下载镜像,然后安装即可。一般默认会自动配置好环境变量。安装好之后打开cmd测试,输入scala,如果出现以下内容则安装成功。(这里安装的是2.12.6版本)

如果没有成功,检查一下Path环境变量,如果安装之后没有自动配置,则手动配置,参照Spark的环境配置。
如下图则表示命令行环境配置成功:
新建一个java项目导入spark-assembly-*.jar包作为工程的第三方依赖包即可
spark2.0以后版本不在提供spark-assembly-*.jar 包;
则将spark环境目录下jars目录的jar包导入即可。
我本地的路径:D:\home\spark-2.1.3-bin-hadoop2.7\jars
注意:该方法,在我本地没有成功一直缺少各种jar包,我本地使用2.1的方法;jar包的路径为spark-assembly-1.6.1-hadoop2.6.0.jar 下载地址:
https://download.csdn.net/download/miss_peng/10472450
a、问题:
在Eclipse里开发spark项目,尝试直接在spark里运行程序的时候,遇到下面这个报错:
ERROR SparkContext: Error initializing SparkContext.
java.lang.IllegalArgumentException: System memory 468189184 must be at least 4.718592E8. Please use a larger heap size.
b、解决办法:
有2个地方可以设置
1. 自己的源代码处,可以在conf之后加上:
val conf = new SparkConf().setAppName("word count")
conf.set("spark.testing.memory", "2147480000")//后面的值大于512m即可
2. 可以在Eclipse的Run Configuration处,有一栏是Arguments,下面有VMarguments,在下面添加下面一行(值也是只要大于512m即可)
-Dspark.testing.memory=1073741824
其他的参数,也可以动态地在这里设置,比如-Dspark.master=spark://hostname:7077
再运行就不会报这个错误了。
解决:
1)、Window——Preference——Java——Installed JREs——选中一个Jre 后
2)、Edit在Default VM arguments 里加入:-Xmx512M
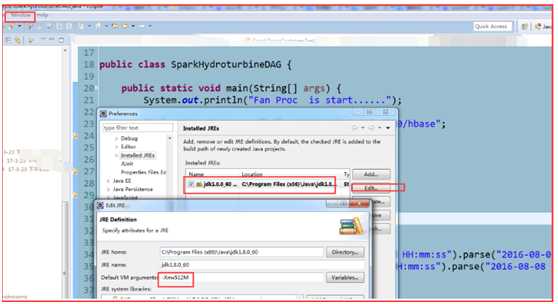
这里的截图是在另外一台机子上配置的环境,用的jar目录会有所区别,但是不影响。
这里ojdbc6.jar 是为了链接数据库使用的jar包,需要根据不同环境自行修改
package spark.jdbc.oracle;
import java.math.BigDecimal;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.rdd.JdbcRDD.ConnectionFactory;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.DataFrameReader;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import scala.Tuple2;
public class TestConn {
private static final String userName = "scott";
private static final String passWord = "tiger";
private static final String driver = "oracle.jdbc.OracleDriver";
private static final String URL = "jdbc:oracle:thin:@localhost:1521/orcl2";
private static final String dbTable = "scott.emp"; //emp
Connection conn = null;
ConnectionFactory connf = null;
// java.lang.ClassNotFoundException: org.apache.commons.configuration.Configuration
public Connection getConn(){
try {
Class.forName(driver);
conn = DriverManager.getConnection(URL,userName,passWord);
//connf = new ConnectionFactory(conn);
System.out.println("orcl2 链接成功");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return conn;
}
public void ReleaseResouce(){
if(conn != null){
try {
conn.close();
System.out.println(conn+" 连接关闭");
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}else{
System.out.println("连接已经关闭");
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
TestConn testConn = new TestConn();
System.out.println(testConn.getConn());
//初始化
SparkConf conf = new SparkConf().setAppName("conn_orcl").setMaster("local");
conf.set("spark.testing.memory","2147480000");
JavaSparkContext jsc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(jsc);
//设置数据库连接参数
Map<String,String> connArgs = new HashMap<String,String>();
connArgs.put("url", TestConn.URL);
connArgs.put("user", TestConn.userName);
connArgs.put("password", TestConn.passWord);
connArgs.put("driver", TestConn.driver);
connArgs.put("dbtable", TestConn.dbTable);
DataFrameReader dfReader = sqlContext.read().format("jdbc").options(connArgs);
DataFrame df = dfReader.load();
df.show();
System.out.println("df Schema : ");
df.printSchema();
df.select("HIREDATE").show();
System.out.println();
System.out.println("---------------------To Table--------------------");
df.registerTempTable("emp");
DataFrame dfSQL = sqlContext.sql("Select JOB,SAL From emp");
System.out.println("dfSQL : ");
dfSQL.show();
JavaPairRDD<String,BigDecimal> jpRDD = dfSQL.toJavaRDD().mapToPair(new PairFunction<Row,String,BigDecimal>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, BigDecimal> call(Row r) throws Exception {
// TODO Auto-generated method stub
/*System.out.println("Row : ");
System.out.println(r);*/
Tuple2<String, BigDecimal> t2 = new Tuple2<String, BigDecimal>((String) r.get(0),(BigDecimal)r.get(1));
return t2;
}
});
System.out.println("jpRDD : ");
System.out.println(jpRDD.collect());
JavaPairRDD<String, Iterable<BigDecimal>> jpRDD2 = jpRDD.groupByKey();
System.out.println("jpRDD2 : ");
System.out.println(jpRDD2.collect());
JavaPairRDD<String, Double> jpRDD3 = jpRDD2.mapToPair(new PairFunction<Tuple2<String, Iterable<BigDecimal>>,String,Double>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Double> call(
Tuple2<String, Iterable<BigDecimal>> t) throws Exception {
// TODO Auto-generated method stub
double sum = 0;
Iterator<BigDecimal> it = t._2.iterator();
while(it.hasNext()){
sum += Double.valueOf(it.next().toString());
}
Tuple2<String, Double> t2 = new Tuple2<String, Double>(t._1,sum);
System.out.println(t._1+" : "+sum);
return t2;
}
});
System.out.println("jpRDD3 : ");
System.out.println(jpRDD3.collect());
}
}
代码执行情况:
https://blog.csdn.net/qq_32653877/article/details/81913648
https://blog.csdn.net/u011513853/article/details/52865076
https://blog.csdn.net/wypersist/article/details/80140334
spark-windows(含eclipse配置)下本地开发环境搭建
标签:asn 官网 down 安装包 func str stc actor xmx
原文地址:https://www.cnblogs.com/lushanyanyu/p/10716655.html