标签:des style blog http color io os ar 使用
目录
1. 为什么要构建日志系统 2. 通用日志系统的总体架构 3. 日志系统的元数据来源:data source 4. 日志系统的子安全域日志收集系统:client Agent 5. 日志系统的中心日志整合系统:log server 6. 日志系统的后端存储系统:log DB 7. 日志系统搭建学习
1. 为什么要构建日志系统
log是管理员每日需要查看的文件记录。里面记载了大量系统正常和不正常的运行信息,这些信息对管理员分析系统的状况、监视系统的活动、发现系统入侵行为是一个相当重要的部分
对于安全研究员来说,如何有效的利用系统的log来分析和定位攻击成为构建一个完整的IDS、IPS的关键问题
Relevant Link:
http://elf8848.iteye.com/blog/2083306
2. 通用日志系统的总体架构
0x1: 日志系统特征
在一个大型的平台每天会产生大量的日志(一般为流式数据,如: 搜索引擎的pv,查询等),处理这些日志需要特定的日志系统,一般而言,这些系统需要具有以下特征:
1. 构建应用系统和分析系统的桥梁,并将它们之间的关联解耦 2. 支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统 3. 具有高可扩展性。即: 当数据量增加时,可以通过增加节点进行水平扩展
0x2: 各类日志分析系统的对比
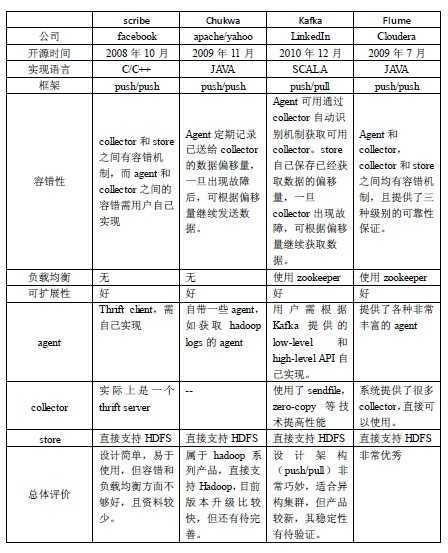
1. FaceBook的Scribe
Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(例如NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的"分布式收集,统一处理"提供了一个可扩展的,高容错的方案
它最重要的特点是容错性好。当后端的存储系统crash时,scribe会将数据写到本地磁盘上,当存储系统恢复正常后,scribe将日志重新加载到存储系统中
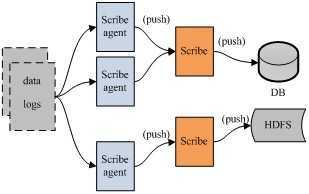
架构:
scribe的架构比较简单,主要包括三部分,分别为scribe agent、scribe、存储系统
1. scribe agent scribe agent实际上是一个thrift client。向scribe(中心server)发送数据的唯一方法是使用thrift client, scribe内部定义了一个thrift接口,用户(scribe agent)使用该接口将数据发送给server(scribe) 2. scribe scribe接收到thrift client发送过来的数据,根据配置文件,将不同topic的数据发送给不同的对象。scribe提供了各种各样的store,如 file, HDFS等,scribe可将数据加载到这些store中。 3. 存储系统 存储系统实际上就是scribe中的store,当前scribe支持非常多的store,包括 1) file(文件) 2) buffer(双层存储: 一个主储存、一个副存储) 3) network(另一个scribe服务器) 4) bucket(包含多个store,通过hash的将数据存到不同store中) 5) null(忽略数据) 6) thriftfile(写到一个Thrift TFileTransport文件中) 7) multi(把数据同时存放到不同store中)
2. Apache的Chukwa
chukwa是一个非常新的开源项目,由于其属于hadoop系列产品,因而使用了很多hadoop的组件(用HDFS存储,用mapreduce处理数据),它提供了很多模块以支持hadoop集群日志分析
特点:
1. 灵活的,动态可控的数据源 2. 高性能,高可扩展的存储系统 3. 合适的框架,用于对收集到的大规模数据进行分析
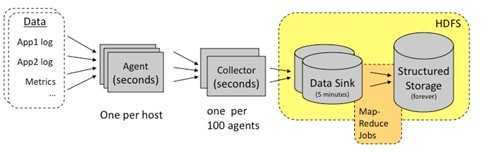
架构:
Chukwa中主要有3种角色,分别为: adaptor、agent、collector
1. Adaptor数据源 可封装其他数据源,如file,unix命令行工具等 目前可用的数据源有: 1) hadoop logs 2) 应用程序度量数据 3) 系统参数数据(如linux cpu使用流率) 2. HDFS存储系统 Chukwa采用了HDFS作为存储系统,对于Chukwa使用的HDFS的这个业务场景,存在几个问题 1) HDFS的设计初衷是支持大文件存储(hadoop的特点)和小并发高速写的应用场景 2) 而日志系统的特点恰好相反,它需支持高并发低速率的写和大量小文件的存储 3. Collector和Agent 为了克服HDFS存储系统和Chukwa日志采集速率不兼容的问题,增加了agent和collector阶段。 3.1 Agent的作用: 给adaptor提供各种服务,包括 1) 启动和关闭adaptor 2) 将数据通过HTTP传递给Collector 3) 定期记录adaptor状态,以便crash后恢复 3.2 Collector的作用: 1) 对多个数据源发过来的数据进行合并,然后加载到HDFS中 2) 隐藏HDFS实现的细节,如,HDFS版本更换后,只需修改collector即可 4. Demux和achieving 直接支持利用MapReduce处理数据。它内置了两个mapreduce作业,分别用于获取data和将data转化为结构化的log。存储到data store(可以是数据库或者HDFS等)中
3. LinkedIn的Kafka
Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群
特点:
1. 数据在磁盘上的存取代价为O(1) 2. 高吞吐率,在普通的服务器上每秒也能处理几十万条消息 3. 分布式架构,能够对消息分区 4. 支持将数据并行的加载到hadoop
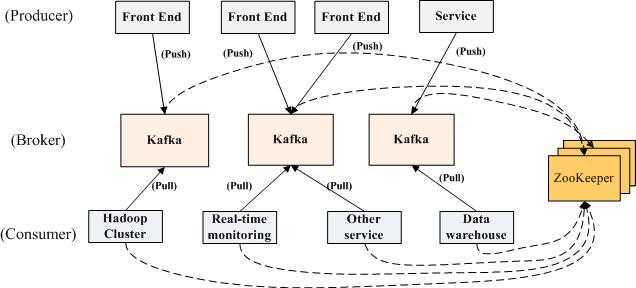
架构:
Kafka实际上是一个消息发布订阅系统。producer向某个topic发布消息,而consumer订阅某个topic的消息,进而一旦有新的关于某个topic的消息,broker会传递给订阅它的所有consumer
在kafka中,消息是按topic组织的,而每个topic又会分为多个partition,这样便于管理数据和进行负载均衡。同时,它也使用了zookeeper进行负载均衡。
Kafka中主要有三种角色,分别为producer、broker、consumer
1. Producer Producer的任务是向broker发送数据。Kafka提供了两种producer接口 1) low_level接口: 使用该接口会向特定的broker的某个topic下的某个partition发送数据 2) high level接口: 该接口支持同步/异步发送数据 基于zookeeper的broker自动识别和负载均衡(基于Partitioner) producer可以通过zookeeper获取可用的broker列表,也可以在zookeeper中注册listener,该listener在以下情况下会被唤醒: a.添加一个broker b.删除一个broker c.注册新的topic d.broker注册已存在的topic 当producer得知以上时间时,可根据需要采取一定的行动 2. Broker Broker采取了多种策略提高数据处理效率,包括sendfile和zero copy等技术 3. Consumer consumer的作用是将日志信息加载到中央存储系统上。kafka提供了两种consumer接口 1) low level接口: 它维护到某一个broker的连接,并且这个连接是无状态的,即,每次从broker上pull数据时,都要告诉broker数据的偏移量 2) high-level接口 它隐藏了broker的细节,允许consumer从broker上push数据而不必关心网络拓扑结构。更重要的是,对于大部分日志系统而言,consumer已经获取的数据信息都由broker保存,而在kafka中,由consumer自己维护所取数据信息
4. Cloudera的Flume
Flume是cloudera于2009年7月开源的日志系统。它内置的各种组件非常齐全,用户几乎不必进行任何额外开发即可使用
特点:
1. 可靠性 当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为 1) end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送) 2) Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送) 3) Best effort(数据发送到接收方后,不会进行确认) 2. 可扩展性 Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题 3. 可管理性 所有agent和colletor由master统一管理,这使得系统便于维护。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web和shell script command两种形式对数据流进行管理 4. 功能可扩展性 用户可以根据需要添加自己的agent,colletor或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)
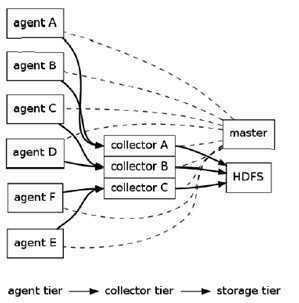
架构:
Flume采用了分层架构,由三层组成,分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向
1. agent agent的作用是将数据源的数据发送给collector 1.1 source: 数据来源 Flume自带了很多直接可用的数据源(source),如: 1) text("filename"): 将文件filename作为数据源,按行发送 2) tail("filename"): 探测filename新产生的数据,按行发送出去 3) fsyslogTcp(5140): 监听TCP的5140端口,并且接收到的数据发送出去 1.2 sink 1) console[("format")]: 直接将将数据显示在桌面上 2) text("txtfile"): 将数据写到文件txtfile中 3) dfs("dfsfile"): 将数据写到HDFS上的dfsfile文件中 4) syslogTcp("host", port): 将数据通过TCP传递给host节点 2. collector collector的作用是将多个agent的数据汇总后,加载到storage中。它的source和sink与agent类似。从本质上来说,也可以把collector看成是一个agent,只是它所处的网络架构的位置为中心汇总的位置,负责将所有子安全域的agent上报的信息进行整理汇总 3. storage storage是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase等
0x3: 日志系统架构的通用特点
根据这四个系统的架构设计,可以总结出典型的日志系统需具备三个基本组件,分别为
1. agent(封装数据源,将数据源中的数据发送给collector):日志采集 2. collector(接收多个agent的数据,并进行汇总后导入后端的store中):日志综合汇总、整理 3. store(中央存储系统,应该具有可扩展性和可靠性,应该支持当前非常流行的HDFS):日志存储
Relevant Link:
http://dongxicheng.org/search-engine/log-systems/
3. 日志系统的元数据来源:data source
0x1: syslog
syslog是Linux系统提供的一个系统服务进程,默认运行监听在514端口,syslog服务是Linux提供的一个统一的日志整合接口,原则上来说,Linux系统下的所有的系统常规行为信息都可以通过syslog得到
关于Linux系统日志、syslog的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3892465.html
syslog默认有两个守护进程
1. klogd klogd进程是记录系统运行的过程中内核生成的日志,而在系统启动的过程中内核初始化过程中生成的信息记录到控制台(/dev/console)当系统启动完成之后会把此信息存放到/var/log/dmesg文件中,我可以通过cat /var/log/dmesg查看这个文件,也可以通过dmesg命令来查看 2. syslogd syslogd 进程是记录非内核以外的信息
Relevant Link:
http://fanqiang.chinaunix.net/a1/b5/20011011/1200021437.html http://ant595.blog.51cto.com/5074217/1080922
0x2: snoopy logger
syslog只能记录一些简单的系统操作指令、SSH/FTP登录失败等安全事件,如果需要一些更深层次的系统事件,例如系统调用,网络连接状态等信息,就需要借助一些第三方的软件进行日志源获取了,snoopy logger就是一个很优秀的系统监控软件
snoopy logger的基本工作原理是将自己的.so插入到/etc/ld.so.preload中(类似windows中的DLL注入),以监视exec系统调用
Relevant Link:
http://bbs.gxnu.edu.cn/nForum/#!article/Programming/1386 http://blog.sina.com.cn/s/blog_704836f40101kyys.html http://mewbies.com/how_to_use_snoopy_logger_tutorial.htm
0x3: kprobe
kprobe是Linux系统原生提供的一个系统调用监控机制,kprobe允许编程人员对Linux系统的某个系统调用函数的执行流上的"前pre_handler"、"后after_handler"、"错误fault_handler"进行回调注册,当代码逻辑流到达预定位置的时候,自动触发程序员注册的回调函数。
在回调函数中,程序员可以获取到当前执行系统调用的参数、进程环境相关参数、调用执行结果等信息从本质上来讲,入侵检测的感知模块就是一个系统行为的监控系统,kprobe的这种特性使得它能很好的充当日志数据源provider的角色
关于kprobe的相关原理,请参阅另外2篇文章
http://www.cnblogs.com/LittleHann/p/3854977.html http://www.cnblogs.com/LittleHann/p/3920387.html
0x4: syslog-ng
syslog-ng可以简单的看成取代syslog的企业级的日志服务器
syslog-ng可运行于"server"和"agent"模式,分别支持UDP、可靠的TCP和加密的TLS协议
syslog-ng可以用来在混合复杂的环境里建立灵活的、可靠的日志服务器
syslog-ng开源版本的特性还有:
1. 支持SSL/TSL协议 2. 支持将日志写入数据库中,支持的数据库有MySQL, Microsoft SQL (MSSQL), Oracle, PostgreSQL, and SQLite. 3. 支持标准的syslog协议 4. 支持filter、parse以及rewrite 5. 支持更多的平台 6. 更高的负载能力
syslog-ng对性能进行了优化,可以处理巨大的数据量。一般的硬件,在正确的配置下,可以实时地处理75000个消息每秒钟,超过24GB的RAW日志每小时
Relevant Link:
http://www.php-oa.com/2012/01/13/linux-syslog-ng.html
0x5: 程序运行产生的运行日志
除了系统原生的日志和系统调用日志之外,程序运行中产生的运行日志也可以作为一个日志数据源,通过将运行信息输出到Linux下指定文件中,可以获得更加定制化的日志信息
4. 日志系统的子安全域日志收集系统:client Agent
在client agent的方案设计和具体实现上,我们需要重点考虑几个问题
1. 如何对异构的客户端日志数据源进行收集、转换、整合 2. 客户端的日志provider(产生日志的数据源)的日志产生速率并不一致,有的应用的日志产生方式是低速大文件、有的是高速小文件。如何在这些异构、异速的日志源之间进行日志采集是一个需要考虑的问题 3. client agent充当的是日志采集的客户端,在从客户端上获得原始日志数据后,必然要通过网络方式同步到一个中心的日志server上,这是个1:N的消息集中,为了防止出现性能瓶颈,一个好的思路是采用异步消息queue的方式将日志消息push到中心log server上
0x1: Fluentd
Fluentd is a fully free and fully open-source log collector that instantly enables you to have a "Log Everything" architecture
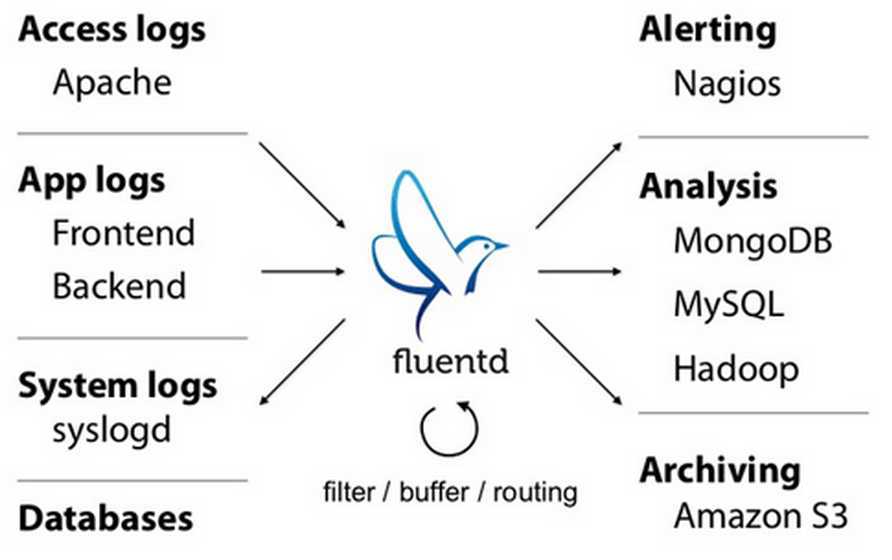
Fluentd treats logs as JSON, a popular machine-readable format. It is written primarily in C with a thin-Ruby wrapper that gives users flexibility.
Fluentd的特点
1. Unified Logging with JSON Fluentd tries to structure data as JSON as much as possible: this allows Fluentd to unify all the collect, filter, buffer, and output mechanisms across multiple sources and destinations (Unified Logging Layer). The downstream data processing is much easier with JSON, since you don‘t have to maintain any adhoc scripts. 通过JSON的方式,在clinet agent这一层提供了一个统一的日志源抽象层 2. Pluggable Architecture Fluentd has a flexible plugin system that allows community to extend its functionality. Community contributed 300+ plugins makes it compatible with dozens of data sources and data outputs, and let you immediately utilize the data. 3. Minimum Resources Required Fluentd is written in a combination of C language and Ruby, and requires very little system resource. The vanilla instance runs on 30-40MB of memory and can process 13,000 events/second/core. 4. Built-in Reliability Fluentd supports memory- and file-based buffering to prevent inter-node data loss. Fluentd also support robust failover and can be set up for high availability. 2,000+ data-driven companies rely on Fluentd to differentiate their products and services through a better use and understanding of their log data.
Relevant Link:
http://docs.fluentd.org/articles/quickstart
5. 日志系统的中心日志整合系统:log server
log server在架构上位于所有client agent的网络中心节点的位置,通常来说是一个分布式集群,通过前端负载均衡将来自client agent的日志汇集流量平均分配到后端的log server集群上。
0x1: TimeTunnel
TimeTunnel(简称TT)是一个基于thrift通讯框架搭建的实时数据传输平台,具有如下特点
1. 高性能 2. 实时性 3. 顺序性 4. 高可靠性 5. 高可用性 6. 可扩展性等特点(基于Hbase)
TT非常适合在流式数据实时接入的业务场景,可应用于
1. 日志收集 2. 数据监控 3. 广告反馈 4. 量子统计 5. 数据库同步等领域
使用TimeTunnel的业务场景架构图如下
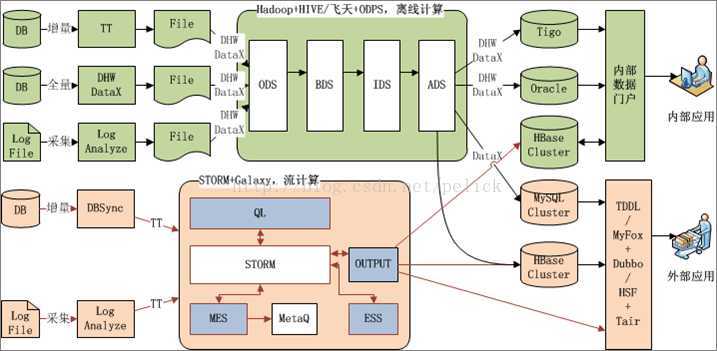
TimeTunnel逻辑架构图如下
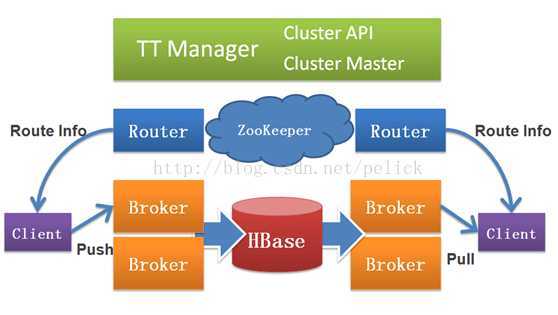
Time Tunnel大概有几部分组成
1. TTmanager 1) 负责对外提供队列申请、删除、查询和集群的管理接口 2) 对内故障发现,发起队列迁移 2. Client 一组访问timetunnel的API,主要有三部分组成 1) 安全认证api 2) 发布api 3) 订阅api 目前client支持java,python,php三种语言 3. Router 客户端提供路由信息,找到为消息队列提供服务的Broker。Router是访问timetunnel的门户,主要负责路由、安全认证和负载均衡
1) Client访问timetunnel的第一步是向Router进行安全认证 2) 如果认证通过,Router根据Client要发布或者订阅的topic对Client进行路由,使Client和正确的Broker建立连接 3) 路由的过程包含负载均衡策略,Router保证让所有的Broker平均地接收Client访问 4. Zookeeper Zookeeper是hadoop的开源项目,其主要功能是状态同步,Broker和Client的状态都存储在这里 5. Broker Broker是timetunnel的核心,负责消息的存储转发,承担实际的流量,进行消息队列的读写操作
Relevant Link:
http://blog.csdn.net/pelick/article/details/26265663 http://code.taobao.org/p/TimeTunnel/wiki/index/ http://code.taobao.org/p/TimeTunnel/src/ http://www.oschina.net/question/3307_14476
6. 日志系统的后端存储系统:log DB
日志系统的业务场景是一个以存储、呈现为主的需求,并不需要十分高的实时性需求
Relevant Link:
7. 日志系统搭建学习
了解了日志系统的基本原理和架构后,我们接下来尝试自己在搭建一个日志demo系统
0x1: HAProxy + Keepalived + Flume
Relevant Link:
http://my.oschina.net/pzh0819/blog/143800
0x2: Fluentd + MongoDB
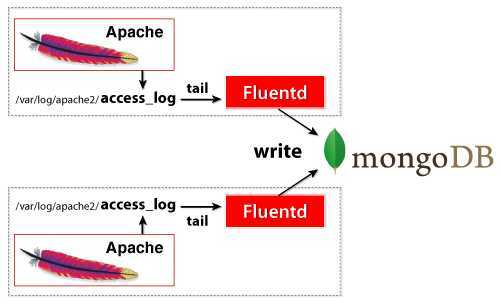
1. 安装
//You can easily do this via rubygems (beware it requires at least ruby 1.9.2): $ gem install fluentd //When you’re done you can create a setup file: $ fluentd -s ~/.fluentd This will create the file ~/.fluentd/fluent.conf and setup the ~/.fluent/plugins folder.
2. 配置Fluentd:fluentd.conf file
example
## built-in TCP input ## $ echo <json> | fluent-cat <tag> <source> type forward port 24224 </source> ## match tag=fluentd.test.** and dump to console <match fluentd.test.**> type stdout </match> <match mongo.**> type mongo host 127.0.0.1 port 27017 database fluentd collection test # for capped collection capped capped_size 1024m # flush flush_interval 1s </match>
修改完配置文件后,我们可以重启Fluentd
$ fluentd -c ~/.fluent/fluent.conf
3. Logging from log datasource
配置完fluentd之后,我们就可以使用fluentd进行异构日志收集,并将日志汇总到后端的存储系统中了
Logging from bash to STDOUT
#!/bin/sh fluent_log(){ local project="$1" local script_name="$2" local message="$3" echo "{\""project\"":\""$project"\",\""script_name\"":\""$script_name"\",\""message\"":\""$message\""}" | fluent-cat fluentd.test.log } fluent_log "Library" "Reload books" "Started"
Relevant Link:
http://metalelf0.github.io/tools/2013/08/09/fluentd-usage-example-with-bash-and-ruby/ http://blog.nosqlfan.com/html/3521.html http://bbs.linuxtone.org/home.php?mod=space&uid=15973&do=blog&id=3492
Copyright (c) 2014 LittleHann All rights reserved
Linux System Log Collection、Log Integration、Log Analysis System Building Learning
标签:des style blog http color io os ar 使用
原文地址:http://www.cnblogs.com/LittleHann/p/4036830.html