标签:cat hdfs width sed 分析 api 本地 dea 去除
一、数据集
网站用户购物行为数据集2030万条,包括raw_user.csv(2000万条)和small_user.csv(30万条,适合新手)
字段说明:
user_id 用户编号,item_id 商品编号,behavior_type 用户操作类型:1(浏览)、2(收藏)、3(加入购物车)、4(购买)
user_geohash 用户地理位置哈希值,在预处理中将其转化为province省份、item_category商品分类,time 用户操作时间
二、实验任务
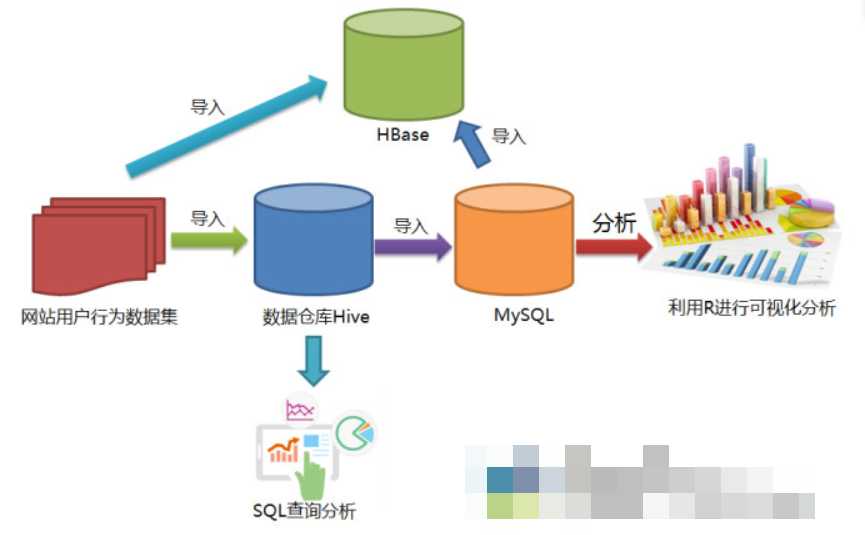
三、实验步骤
(一)对csv进行预处理
1.去除csv文件的表头
cd ~/下载
sed -i ‘1d‘ raw_user.csv # 删除第一行
sed -i ‘1d‘ small_user.csv
head -5 raw_user.csv # 查看前5行内容
head -g small-user.csv
2.将user_geohash转化为province,并将文件格式转化为txt
具体转化细节不说明,本文注重整个分析过程,详细内容参考林子雨老师的博客。
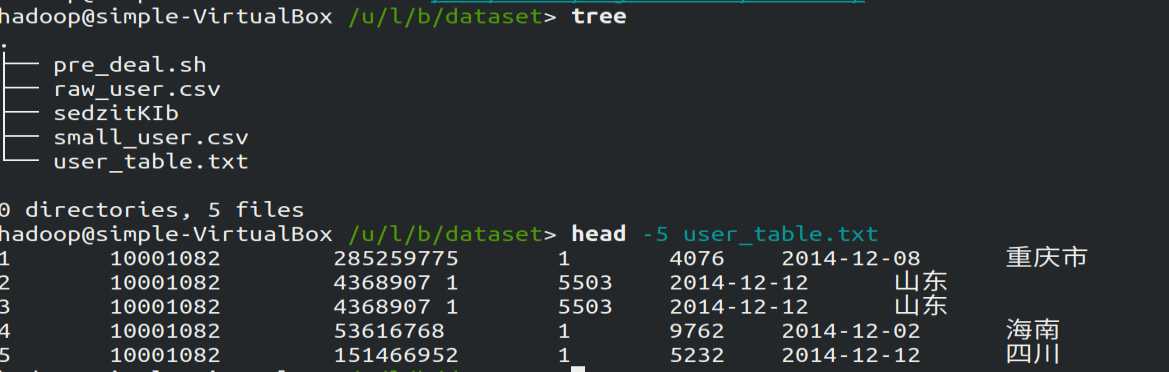
转化成功后,在该目录通过pre_deal.sh脚本加载small_user.csv生成user_table.txt文件,使用tree查看该目录结构:
Hive是基于Hadoop的数据仓库,在将user_table中的数据导入的数据仓库之前,需要先把user_table.txt文件上传到HDFS中。然后再Hive中创建外部表,完成数据的导入。
启动HDFS:由于笔者在安装hadoop时已完成了环境变量的配置,现在在任意目录执行下面的语句开启hadoop: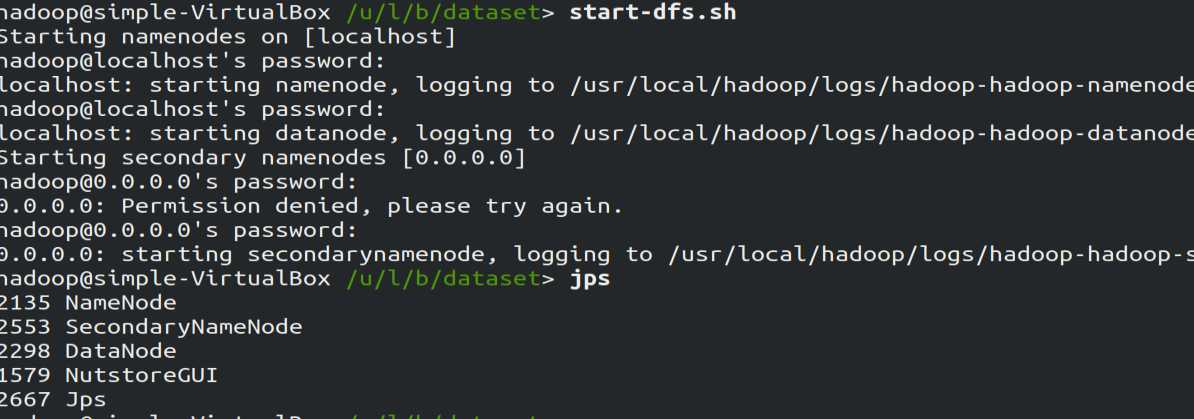
将user_table.txt文件上传到HDFS中

在HDFS中查看该文件的前10行:

(二)将HDFS中的文件导入到Hive数据仓库中
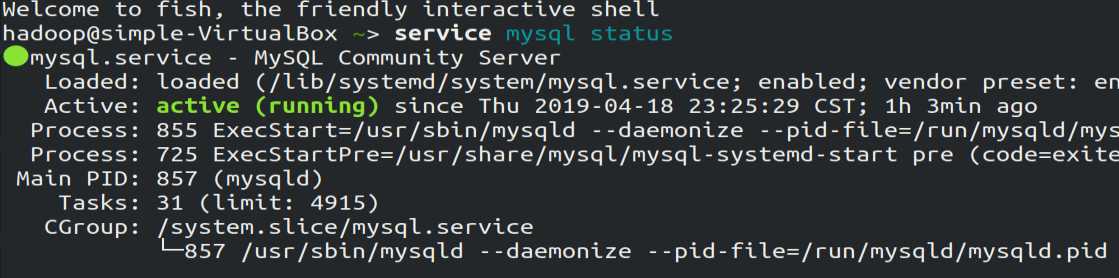
1.启动mysql数据库
mysql用于保存Hive的元数据(在安装Hive时需要配置),因此需先开启mysql服务
2.启动hive,启动成功后如下图所示
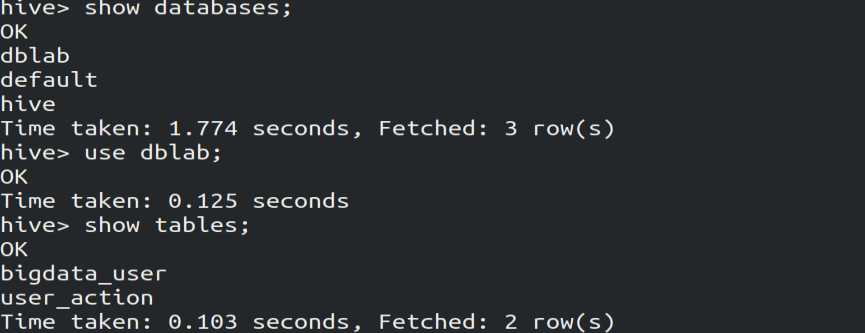
3.创建数据库,并建立外部表,将HDFS中/bigdatacase/dataset目录下的文件作为该外部表的内容
hive> create database dblab;
hive> use dblab;
hive> CREATE EXTERNAL TABLE dblab.bigdata_user(id INT,
uid STRING,item_id STRING,behavior_type INT,item_category STRING,
visit_date DATE,province STRING) COMMENT ‘Welcome to xmu dblab!‘
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ STORED AS TEXTFILE LOCATION
‘/bigdatacase/dataset‘;
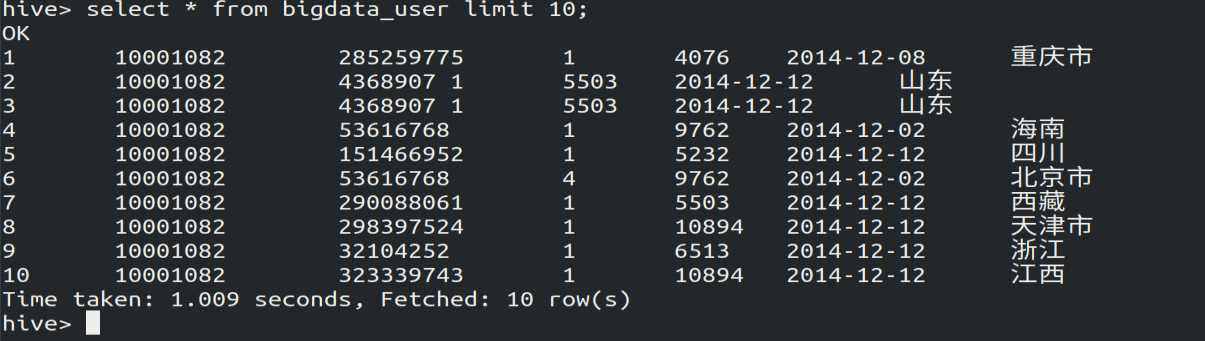
4.使用Hive命令进行查询
标签:cat hdfs width sed 分析 api 本地 dea 去除
原文地址:https://www.cnblogs.com/2sheep2simple/p/10729415.html