标签:大写 字母 pass click into return bsp 释放 atom
最近又复习了mysql中的一些概念:视图,触发器,存储过程,函数,事务,记录下。
1.视图
视图是一个虚拟表,本身并不存储数据,当sql在操作视图时所有数据都是从其他表中查出来的,因此其本质是:根据SQL语句获取动态的数据集,并为其命名,用户使用时只需使用【名称】即可获取结果集,并可以将其当作表来使用。
视图操作:

-- CREATE TABLE students( -- nid INT NOT NULL AUTO_INCREMENT, -- name VARCHAR(128) NOT NULL, -- gender CHAR(8) NOT NULL, -- age INT NOT NULL, -- class VARCHAR(64) NOT NULL, -- PRIMARY KEY (nid) -- )DEFAULT CHARSET=utf8; -- INSERT INTO students(name, gender,age,class) VALUES(‘李木‘,‘男‘,24,‘python班‘); -- INSERT INTO students(name, gender,age,class) -- VALUES(‘王华‘,‘男‘,26,‘python班‘), -- (‘王钰‘,‘女‘,22,‘前端‘); -- 创建并使用视图view1 -- SELECT * FROM (SELECT nid,name FROM students WHERE nid>1) AS view1 WHERE view1.name="王华"; -- 创建视图格式: CREATE VIEW 视图名称 AS sql语句; -- CREATE VIEW view1 AS SELECT nid, name FROM students WHERE nid>1; -- 修改视图格式:ALTER VIEW 视图名称 AS sql语句; -- ALTER VIEW view1 AS SELECT nid,name FROM students WHERE name="李木"; -- 使用视图:使用视图时,将其当作表进行操作即可,由于视图是虚拟表,所以无法使用其对真实表进行创建、更新和删除操作,仅能做查询用。 -- SELECT * FROM view1; -- 删除视图格式:DROP VIEW 视图名称; -- DROP VIEW view1;
2.触发器
对某个表行进行增删改操作,如果希望操作前后触发某些特定的操作,便可以使用触发器。触发器就像信号或中间件类似,可以定制特定的操作,注意的是行操作触发。
触发器操作:
-- 创建触发器语法
每一行插入前触发
CREATE TRIGGER tri_before_insert_table BEFORE INSERT ON students FOR EACH ROW;
BEGIN
END
插入后触发
CREATE TRIGGER tri_after_insert_table AFTER INSERT ON students FOR EACH ROW;
BEGIN
END
删除前触发
CREATE TRIGGER tri_before_delete_table BEFORE DELETE ON students FOR EACH ROW;
BEGIN
END
删除后触发
CREATE TRIGGER tri_after_delete_table AFTER DELETE ON students FOR EACH ROW;
BEGIN
END
更新前触发
CREATE TRIGGER tri_before_update_table BEFORE UPDATE ON students FOR EACH ROW;
BEGIN
ON
更新后触发
CREATE TRIGGER tri_after_update_table AFTER UPDATE ON students FOR EACH ROW;
BEGIN
触发器使用示例
CREATE TABLE class( nid INT NOT NULL AUTO_INCREMENT, name VARCHAR(64) NOT NULL, count INT NOT NULL, PRIMARY KEY (nid) ) DEFAULT CHARSET = utf8 INSERT INTO class(name,count) VALUES("python班",45),("算法班",50); 创建插入前触发器 NEW表示即将新插入的行 delimiter // CREATE TRIGGER tri_before_insert BEFORE INSERT ON students FOR EACH ROW BEGIN IF NEW.class = "前端" THEN INSERT INTO class ( name,count ) VALUES ( "前端",1 ) ; END IF; END// delimiter; 创建插入后触发器 delimiter // CREATE TRIGGER tri_after_insert AFTER INSERT ON students FOR EACH ROW BEGIN IF NEW.class="python" THEN INSERT INTO class(name,count) VALUES("python",1); ELSEIF NEW.class = "数据结构" THEN INSERT INTO class(name,count) VALUES("数据结构",2); END IF; END// delimiter; 使用触发器(插入一行数据时触发) insert into students(name,gender,age,class)values(‘李曼‘,"女",25,"python"); insert into students(name,gender,age,class)values(‘王军‘,"男",25,"数据结构"); 删除触发器 DROP TRIGGER tri_before_insert;
(触发器中,NEW表示即将插入的数据行,OLD表示即将删除的数据行。)
触发器性能:https://segmentfault.com/q/1010000004907411
https://www.cnblogs.com/geaozhang/p/6819648.html
3. 存储过程
存储过程是一组SQL语句集合,经过编译创建并保存在数据库中,用户可以通过指定存储过程的名字并给定参数(若需要时)来调用。当调用存储过程时,其内部的SQL语句会按逻辑顺序执行。
创建存储过程:
--创建存储过程 delimiter // CREATE PROCEDURE p1() BEGIN SELECT * FROM students WHERE class = "前端"; END // delimiter; --调用存储过程 call p1()
存储过程还可以接受参数,包括三类参数:
-- 传入和传出参数 delimiter // CREATE PROCEDURE p2( IN i1 INT, IN i2 INT, INOUT i3 INT, OUT i4 INT ) BEGIN DECLARE temp1 INT; DECLARE temp2 INT DEFAULT 0; SET temp1=1; SET i4 =i1+i2+temp1+temp2; set i3 = i3+100; END// delimiter; -- 执行存储过程p2() SET @t1=4; SET @t2=5; CALL p2(1,2,@t1,@t2); SELECT @t1,@t2; -- 输出结果 -- @t1,@t2 -- 104, 4
通过存储过程的返回值,可以用来判断其执行状态,如下:
-- 支持事务(通过返回值能判断执行的状态) delimiter// CREATE PROCEDURE p3( OUT p_return_code TINYINT ) BEGIN -- 出现错误 DECLARE EXIT HANDLER FOR SQLEXCEPTION BEGIN set p_return_code=1; ROLLBACK; END; -- 出现警告 DECLARE EXIT HANDLER FOR SQLWARNING BEGIN set p_return_code=2; ROLLBACK; END; START TRANSACTION; DELETE FROM class; INSERT INTO students(name,gender,age,class) VALUES("宋红云","女",23,"python"); COMMIT; -- 成功执行 SET p_return_code = 0; END// delimiter; SET @r1 = -1; CALL p3(@r1); SELECT @r1; -- 输出结果 @r1=0
存储过程使用游标
-- 使用游标 delimiter// CREATE PROCEDURE p4() BEGIN DECLARE sage INT; DECLARE sname VARCHAR(128); DECLARE done INT DEFAULT FALSE; DECLARE my_cursor CURSOR FOR SELECT name,age FROM students; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done =TRUE; OPEN my_cursor; myloop: LOOP FETCH my_cursor INTO sname,sage; IF done THEN LEAVE myloop; END IF; INSERT INTO class(cname) values(sname); END LOOP myloop; CLOSE my_cursor; END// delimiter; CALL p4();
利用prepare,execute,dellocate, 可以实现动态执行SQL语句,同时对SQL语句进行检查,防治SQL注入(?为查询条件中占位符)
delimiter// CREATE PROCEDURE p5( IN i INT ) BEGIN SET @i2 = i; PREPARE prod FROM "select * from students where nid=? "; EXECUTE prod USING @i2; -- 变量只能是SET @i2 = value的变量,传入和declare的变量不行 DEALLOCATE PREPARE prod; END// delimiter; CALL p5(2); -- sql注入: -- sql = "select * from students where name="+i+";" -- 如果采用上面字符窜拼接sql语句时,当用户输入的i="ss or 1=1",则where语句肯定为TRUE,会拿到所有的name数据
上述语句中注意EXECUTE prod USING @i1,@i2;可以传入多个查询变量,和占位符按顺序对应,而且变量只能是变量只能是SET @i2 = value的变量,传入和declare的变量不行。
python中通过pymysql模块也可以调用存储过程
#coding:utf-8 import pymysql conn = pymysql.connect(host="localhost",port=3306,db="learningsql",user="root",passwd="",charset="utf8") cursor = conn.cursor() #cursor = conn.cursor(cursor = pymysql.cursors.DictCursors) 最后返回的结果,每一行为字典 cursor.callproc("p5",args=(1,)) #执行需要参数的存储过程 # a,b=0,0 # cursor.callproc("p2",args=(1,2,a,b)) # cursor.execute("select @_p2_0,@_p2_1,@_p2_3,@_p2_4") #拿到第1,2,3,4个参数。。。。 result = cursor.fetchall() cursor.close() conn.close() print(result)
4.函数
内置函数:https://dev.mysql.com/doc/refman/5.7/en/functions.html(官方文档)
常用内置函数
CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 length: 是计算字段的长度,一个汉字是算两个或三个字符,一个数字或字母算一个字符; char_length:不管汉字还是数字或者是字母都算是一个字符; CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV(‘a‘,16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为‘#,###,###.##‘,以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: ‘12,332.1000‘ INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 LTRIM(str) 返回字符串 str ,其引导空格字符被删除。 RTRIM(str) 返回字符串 str ,结尾空格字符被删去。 SUBSTRING(str,pos,len) 获取字符串子序列 LOCATE(substr,str,pos) 获取子序列索引位置 REPEAT(str,count) 返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。 若 count <= 0,则返回一个空字符串。 若str 或 count 为 NULL,则返回 NULL 。 REPLACE(str,from_str,to_str) 返回字符串str 以及所有被字符串to_str替代的字符串from_str 。 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 RIGHT(str,len) 从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N) 返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING(‘Quadratically‘,5); -> ‘ratically‘ mysql> SELECT SUBSTRING(‘foobarbar‘ FROM 4); -> ‘barbar‘ mysql> SELECT SUBSTRING(‘Quadratically‘,5,6); -> ‘ratica‘ mysql> SELECT SUBSTRING(‘Sakila‘, -3); -> ‘ila‘ mysql> SELECT SUBSTRING(‘Sakila‘, -5, 3); -> ‘aki‘ mysql> SELECT SUBSTRING(‘Sakila‘ FROM -4 FOR 2); -> ‘ki‘ TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str) 返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(‘ bar ‘); -> ‘bar‘ mysql> SELECT TRIM(LEADING ‘x‘ FROM ‘xxxbarxxx‘); -> ‘barxxx‘ mysql> SELECT TRIM(BOTH ‘x‘ FROM ‘xxxbarxxx‘); -> ‘bar‘ mysql> SELECT TRIM(TRAILING ‘xyz‘ FROM ‘barxxyz‘); -> ‘barx‘ 部分内置函数
自定义函数
-- 定义函数,注意定义返回值类型 delimiter \CREATE FUNCTION fun( i1 INT, i2 INT ) RETURNS INT BEGIN DECLARE sum INT; SET sum = i1+i2; RETURN(sum); END \delimiter ; -- -- 通过select使用 SELECT fun(1,2); -- -- 对查询表字段进行函数操作 SELECT name,fun(1,age) from students; -- 将函数结果存储到变量 SELECT fun(1,2) INTO @sum; SELECT @sum; SELECT UPPER("zack") INTO @name; SELECT @name; -- 删除函数 DROP FUNCTION fun;
自定义函数时注意用户变量,局部变量,全局变量,会话变量,参考:https://blog.csdn.net/qq_34626097/article/details/86528466
5.事务
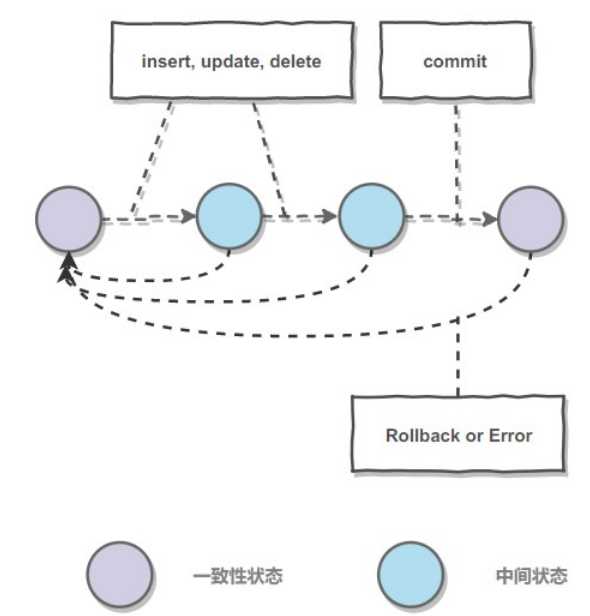
事务是满足 ACID 特性的一组操作,要么全部执行,要么全部不执行,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。在mysql中,事务用于将某些操作的多个SQL操作作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
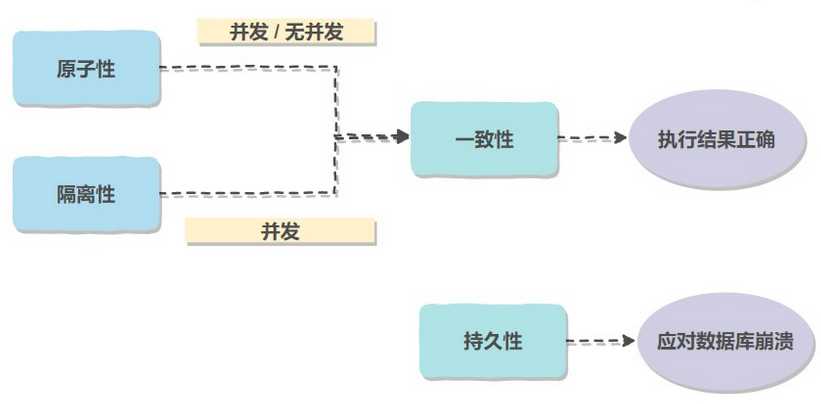
原子性(Atomicity):事务被视为不可分割的最小单位,要么全部执行成功,要么全部失败,进行回滚。(回滚可以通过回滚日志实现,回滚日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可。)
一致性(Consistency):数据库在事务执行前后都保持一致性状态。在一致性状态下,所有事务对一个数据的读取结果都是相同的。
隔离性(Isolation):一个事务所做修改在最终提交前,对其他事务是不可见的。多个事务并发执行时互不影响。
持久性(Durability):一但事务提交,其所做的修改将永远保存在数据库中,即使系统发生崩溃,事务执行的结果也不能丢失。(可以用重做日志来保证持久性)
对ACID特性的理解:(几个特性不是一种平级关系)
ACID特性
一致性状态和中间状态
5.1 事务的并发一致性问题
在多并发条件下,多个事务的隔离性很难保证,因此会出现很多并发一致性问题,包括丢失修改,脏读,不可重复读,幻读。
丢失修改:事务T1和T2都修改了数据,T1先修改,T2后修改,T2的修改覆盖了T1的修改。
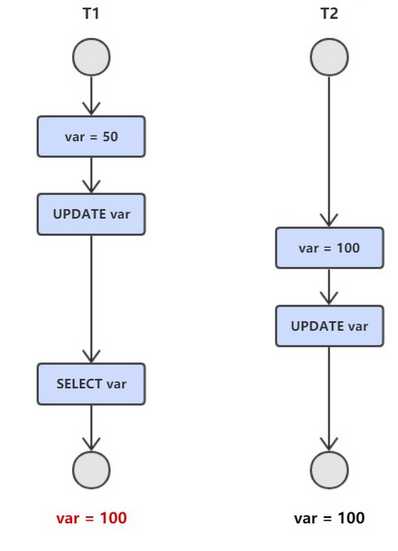
脏读:事务T1修改了数据,事务T2读取了修改后的数据。随后T1回滚撤销了修改,事务T2读取到的就是脏数据。
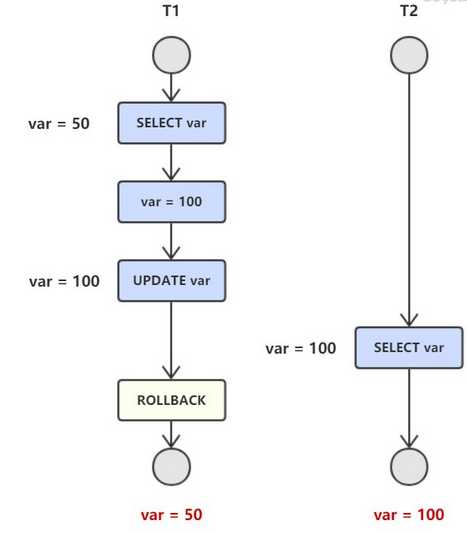
不可重复读:事务T2读取一个数据,T1对数据做了修改,如果T2再次 读取这个数据,此时读取的结果和第一次不一致。
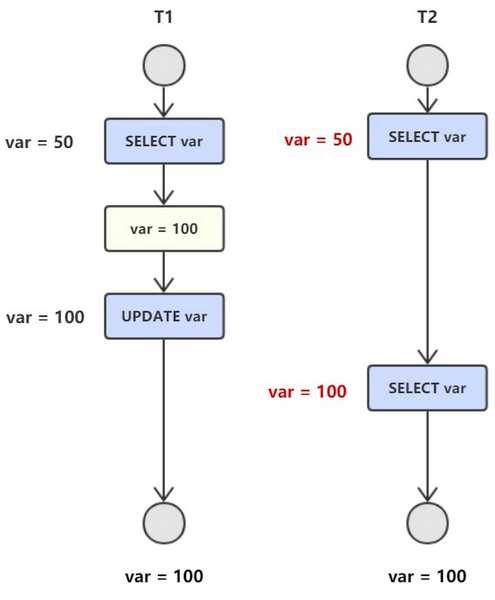
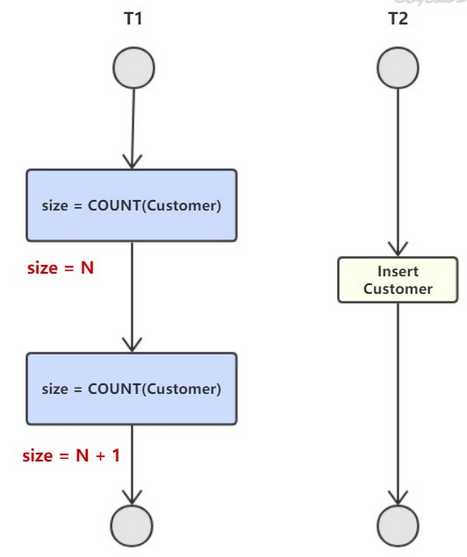
幻读:T1读取某个范围的数据,T2在这个范围了插入了一条数据,T1再次读取这个范围了数据,和第一次读取的结果不同。
(场景:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。)
5.2 事务的隔离级别
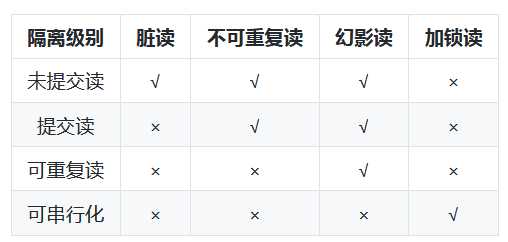
上述的并发一致性问题是由于破坏了事务的隔离性,得通过并发控制来保证事务的隔离性。数据库管理系统提供了事务的隔离级别来处理并发一致性问题,包括未提交读(read uncommitted),提交读(read committed),可重复读(repeated read),可串行化(serilization)。(并发控制可以通过封锁来实现,但是封锁操作需要用户自己控制,相当复杂。)
未提交读:最低的隔离级别,什么都不需要做,一个事务可以读到另一个事务未提交的结果。所有的并发事务问题都会发生
提交读:只有在事务提交后,其更新结果才会被其他事务看见。可以解决脏读问题。
可重复读:在一个事务中,对于同一份数据的读取结果总是相同的,无论是否有其他事务对这份数据进行操作,以及事务是否提交。可以解决脏读、不可重复读。
可串行化:事务串行化执行,隔离级别最高,牺牲了系统的并发性。可以解决并发事务的所有问题。
5.3 多版本并发控制(MVCC,Multi-Version Concurrent Control)
多版本并发控制是MySQL的InnoDB提供的一种实现隔离级别的具体方式。MVCC可以用于实现提交读和可重复读。未提交读隔离级别,总是读取最新的数据行,无需使用 MVCC。可串行化需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。(一句话讲,MVCC就是同一份数据临时保留多个版本/快照)
MVCC实现机制
1.版本号:
系统版本号:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。(包含insert、delete和update操作的事务)
事务版本号:事务开始时的系统版本号。
2.隐藏的列
MVCC 在每行记录后面都保存着两个隐藏的列,用来存储两个版本号:创建版本号和删除版本号
创建版本号:对该行数据创建操作时的事务版本号
删除版本号:对该行数据进行删除操作时的事务版本号
3.实现过程(可重复读隔离级别)
由于旧数据并不真正的删除,所以必须对这些数据进行清理,innodb会开启一个后台线程执行清理工作,具体的规则是将删除版本号小于当前系统版本的行删除,这个过程叫做purge。
4.undo日志
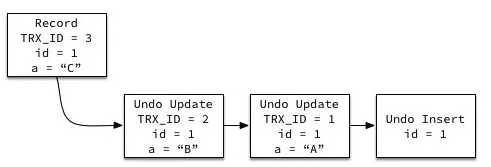
MVCC 使用到的快照存储在 Undo 日志中,该日志通过回滚指针把一个数据行(Record)的所有快照连接起来。
(TRX_ID: 事务版本号,为3时表示最新版本快照,通过回滚指针依次指向2,1,版本号)
5.4 Next-key locks
参考:https://www.cnblogs.com/zhoujinyi/p/3435982.html
http://hedengcheng.com/?p=771
https://zhuanlan.zhihu.com/p/35477890
Next-Key Locks是MySQL的InnoDb的一种锁实现。MVCC不能解决幻读问题,Next-Key Locks 就是为了解决这个问题而存在的。在可重复读隔离级别下,MVCC+Next-Key Locks可以解决幻读问题。Next-Key Locks是Record Locks和Gap Locks的结合。
Record Locks:锁定一个记录上的索引,而不是记录本身。(如果表没有设置索引,InnoDB 会自动在主键上创建隐藏的聚簇索引,因此 Record Locks 依然可以使用。)
Gap Locks:锁定索引之间的间隙,但是不包含索引本身。例如当一个事务执行以下语句,其它事务就不能在 t.c 中插入 15。
SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
Next-Key Locks:不仅锁定一个记录上的索引,也锁定索引之间的间隙。例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)
索引在[10,20]区间会被锁定,锁定后对该区间的操作都会被阻塞
5.5 封锁
5.5.1封锁粒度:
MySQL提供了两种封锁粒度:行级锁和表级锁。 在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。因为锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。但是加锁需要消耗资源,锁的各种操作(包括获取锁、释放锁、以及检查锁状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。
5.5.2封锁类型:
a.读写锁:
排它锁(Exclusive),简写为 X 锁,又称写锁。
一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
共享锁(Shared),简写为 S 锁,又称读锁。
一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
兼容性

b .意向锁:
使用意向锁(Intention Locks)可以更容易地支持多粒度封锁。
在存在行级锁和表级锁的情况下,事务 T 想要对表 A 加 X 锁,就需要先检测是否有其它事务对表 A 或者表 A 中的任意一行加了锁,那么就需要对表 A 的每一行都检测一次,这是非常耗时的。
意向锁在原来的 X/S 锁之上引入了 IX/IS,IX/IS 都是表锁,用来表示一个事务想要在表中的某个数据行上加 X 锁或 S 锁。有以下两个规定:
1. 一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;
2. 一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
通过引入意向锁,事务 T 想要对表 A 加 X 锁,只需要先检测是否有其它事务对表 A 加了 X/IX/S/IS 锁,如果加了就表示有其它事务正在使用这个表或者表中某一行的锁,因此事务 T 加 X 锁失败。
兼容性:
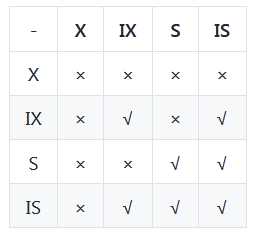
任意 IS/IX 锁之间都是兼容的,因为它们只是表示想要对表加锁,而不是真正加锁;
S 锁只与 S 锁和 IS 锁兼容,也就是说事务 T 想要对数据行加 S 锁,其它事务可以已经获得对表或者表中的行的 S 锁。
5.5.3封锁协议:
参考:https://yq.aliyun.com/articles/626848
https://yq.aliyun.com/articles/626848
a.三级封锁协议
一级封锁协议:事务T修改数据时必须加X锁,直到T结束才能释放。因为不能同时有两个事务对数据修改,可以解决丢失修改问题
二级封锁协议:在一级的基础上,要求读数据A时必须加S锁,读完马上释放锁。因为一个事务对数据A修改时会加X锁,就不会再加S锁,不能 读取数据,可以解决脏读问题。
三级封锁协议:在二级的基础上,要求读取数据A时必须加S锁,直到事务结束时才能释放锁。因为读数据A时一直有S锁,不能再加X锁,保证了 数据不会改变,可以解决不可重复读问题
b.两段锁协议:加锁和解锁分为两个阶段进行。
可串行化调度是指,通过并发控制,使得并发执行的事务结果与某个串行执行的事务结果相同。
事务遵循两段锁协议是保证可串行化调度的充分条件
5.5.4隐式锁和显式锁:MySQL 的 InnoDB 存储引擎采用两段锁协议,会根据隔离级别在需要的时候自动加锁,并且所有的锁都是在同一时刻被释放,这被 称为隐式锁定。InnoDB 也可以使用特定的语句进行显示锁定。(SELECT ... LOCK In SHARE MODE;)
5.6 事务语句
start transaction........commit;
失败时rollback
delimiter \create PROCEDURE p1( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; DELETE from tb1; insert into tb2(name)values(‘seven‘); COMMIT; -- SUCCESS set p_return_code = 0; END\delimiter ; 使用事务 set @i=-1; call p1(@i); select @i;
6.条件判断和循环语句
条件语句:if..then.;.elseif.then.;.else..;.end if;
-- 条件判断语句 delimiter \CREATE PROCEDURE p1( IN i INT ) BEGIN IF i = 2 THEN SELECT * FROM students WHERE nid=2; ELSEIF i>2 THEN SELECT * FROM students WHERE nid>2; ELSE SELECT * FROM students WHERE nid<2; END IF; END\delimiter ; CALL p1(2);
循环语句:while循环,repeat循环,loop循环
-- while 循环语句 delimiter \CREATE PROCEDURE p2( IN i INT ) BEGIN DECLARE sum INT; SET sum = 0; WHILE sum<10 DO SELECT sum; SET sum = sum +i; END WHILE; END \delimiter ; CALL p2(1);
-- repeat 循环 delimiter \CREATE PROCEDURE p3() BEGIN DECLARE i INT; SET i = 0; REPEAT SET i = i+1; SELECT i; UNTIL i>3 END REPEAT; END \delimiter; CALL p3();
-- loop循环 delimiter \CREATE PROCEDURE p4() BEGIN DECLARE i INT DEFAULT 0; label: LOOP SET i = i+2; IF i=4 THEN SELECT * FROM students WHERE nid>4; END IF; IF i>6 THEN LEAVE label; END IF; SELECT i; END LOOP label; END \delimiter; CALL p4();
参考:http://www.cnblogs.com/wupeiqi/articles/5713323.html
https://github.com/CyC2018/CS-Notes
标签:大写 字母 pass click into return bsp 释放 atom
原文地址:https://www.cnblogs.com/silence-cho/p/10667705.html
