标签:正则表达 scripts original input 优化 dir csr 节点 val
图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。为了解决这种问题,通过前后端配合,使图片仅在浏览器当前视窗内出现时才加载该图片,达到减少首屏图片请求数的技术就被称为“图片懒加载”。
在网页源码中,在img标签中首先会使用一个“伪属性”(通常使用src2,original......)去存放真正的图片链接而并非是直接存放在src属性中。当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。
其实很简单,在对标签属性进行定位的时候,仔细观察它真正的属性进行提取。
例如:
import requests
from lxml import etree
def main():
responses = requests.get(url=url, headers=headers)
coding = responses.apparent_encoding
responses.encoding = coding
res_text = responses.text
# 创建etree对象
tree = etree.HTML(res_text)
div_lst = tree.xpath(‘//div[@id="container"]/div‘)
for one_div in div_lst:
image_name = one_div.xpath(‘.//img/@alt‘)[0]
image_url = one_div.xpath(‘.//img/@src2‘)
print(image_name)
print(image_url)
if __name__ == ‘__main__‘:
headers = {"User-Agent":‘Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0‘}
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
main()
以上例子中就将src属性换为了src2属性。
selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作。
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器。
selenium安装就不再概述了
查看自己的谷歌浏览器版本

查看自己对用的谷歌驱动: https://blog.csdn.net/huilan_same/article/details/51896672
下载自己的谷歌驱动: http://chromedriver.storage.googleapis.com/index.html
这里我下载是:
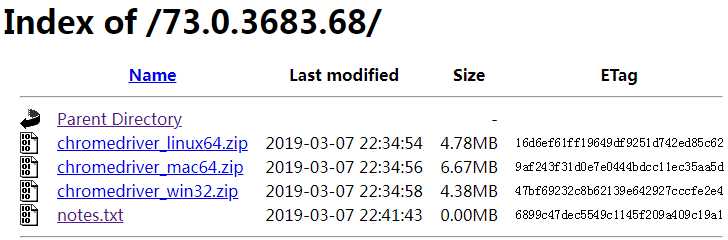
然后加压后把它放到python解释器的scripts目录中即可.
from selenium import webdriver
from time import sleep
# 启动你的谷歌浏览
driver = webdriver.Chrome()
# 用get方法打开百度首页
driver.get(‘https://www.baidu.com‘)
# 找到第一个链接标签的文本并点击
driver.find_elements_by_link_text(‘设置‘)[0].click()
# 睡一秒
sleep(1)
# 找到搜索设置并点击
driver.find_elements_by_link_text(‘搜索设置‘)[0].click()
sleep(2)
# 找到id为nr的标签
ch = driver.find_element_by_id(‘nr‘)
sleep(1)
# 选择第3个标签点击
# ch.find_element_by_xpath(‘//*[@id="nr"]/option[3]‘).click()
ch.find_element_by_xpath(‘.//option[3]‘).click()
sleep(2)
# 保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(2)
# 处理弹出的警告
driver.switch_to_alert().accept()
sleep(2)
# 网搜索框里传入数据
driver.find_element_by_id(‘kw‘).send_keys(‘nba‘)
sleep(2)
# 点击搜索按钮
driver.find_element_by_id(‘su‘).click()
sleep(2)
# 关闭驱动
driver.close()
# 关闭浏览器
driver.quit()
这是一个设置百度搜索每个页面显示50条数据并搜索nba的程序
Selenium支持的浏览器非常多,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS,也就是后面要说的内容。
# 通过id属性
find_element_by_id()
# 通过name属性
find_element_by_name()
# 通过class的名字
find_element_by_class_name()
# 通过标签的名字
find_element_by_tag_name()
# 通过链接标签的文本
find_element_by_link_text()
# 通过链接标签的部分文本
find_element_by_partial_link_text()
# 通过xpath
find_element_by_xpath()
# 通过css选择器
find_element_by_css_selector()
注意:
1 find_element_by_xxx找的是第一个符合条件的标签,find_elements_by_xxx找的是所有符合条件的标签。
2 elenium还提供了通用方法find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()
这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID, id),二者得到的结果完全一致。
# 通过id知道输入框
input = browser.find_element_by_id(‘q‘)
# 向里面出入文本MAC
input.send_keys(‘MAC‘)
# 清楚文本框
input.clear()
# 再传入一个文本IPhone
input.send_keys(‘IPhone‘)
# 通过classname找到一个事件
button = browser.find_element_by_class_name(‘btn-search‘)
# 点击它
button.click()
什么是动作链呢?
在节点交互中,交互动作都是针对某个节点执行的。比如对于输入框,就调用它输入和清空的方法,对于按钮,就调用它点击的方法,其实还有一些操作,它们没有特定的执行对象,比如鼠标拖拽,键盘按键,它们使用另一种方式来执行,就是动作链。
以下例子演示了把一个节点从一处拖动到另一处:
from selenium import webdriver
from time import sleep
from selenium.webdriver import ActionChains
driver = webdriver.Chrome()
# 菜鸟教程的js演示代码
url = ‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘
driver.get(url)
# 进入嵌套的页面
driver.switch_to.frame(‘iframeResult‘)
# 点位要拖动的标签
start = driver.find_element_by_css_selector(‘.ui-draggable‘)
# 拖动的目标标签
end = driver.find_element_by_css_selector(‘.ui-droppable‘)
# 创建一个鼠标事件
actions = ActionChains(driver)
# 点击要拖动的标签不松动
sleep(1)
actions.click_and_hold(start).perform()
# 然后移动到另一个标签
actions.move_to_element(end).perform()
# 往x轴移动40,y轴移动20
sleep(1)
actions.move_by_offset(xoffset=40, yoffset=20).perform()
# 释放动作
actions.release()
可能有人会对driver.switch_to.frame(‘iframeResult‘)这句代码有疑问
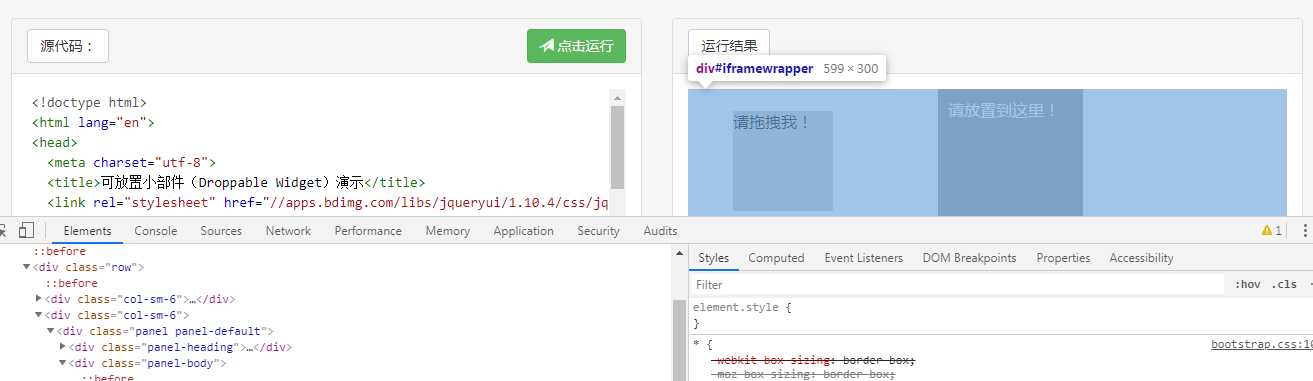
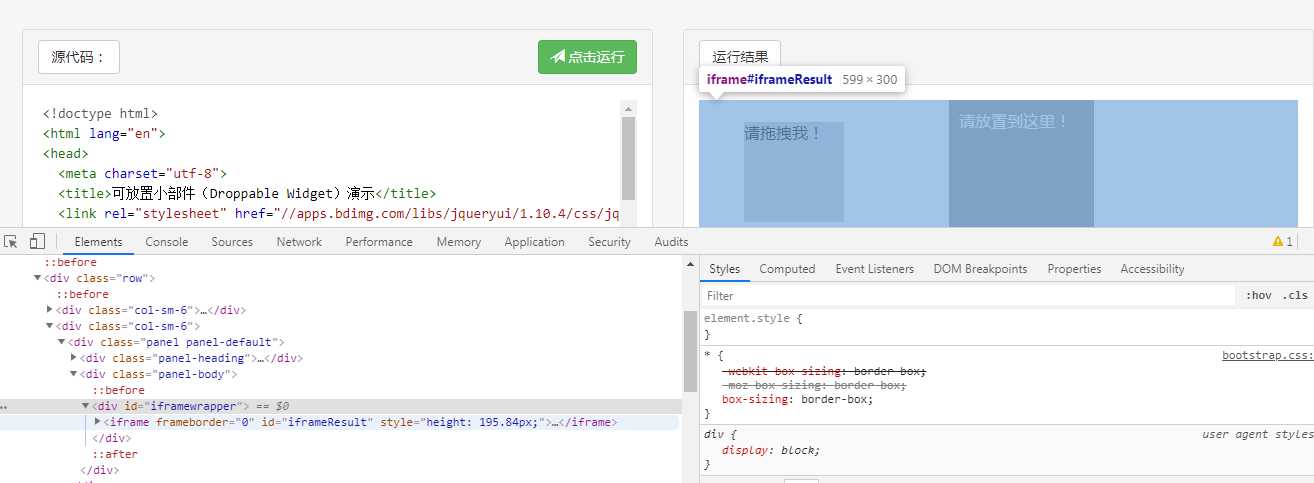
这个就是frame嵌套的。
在 web 应用中经常会出现 iframe 嵌套的应用,假设页面上有 A、B 两个 iframe,其中 B 在 A 内,那么定位 B 中的内容则需要先到 A,然后再到 B。
所以我们使用driver.switch_to.frame(‘iframeResult‘)直接进入嵌套的页面。
有些api是selenium没有提供的,比如下拉进度条,但是可以通过吗模拟运行js来实现。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(‘https://www.jd.com/‘)
# 移动到页面最底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
sleep(2)
# 执行alert123这个代码 就是弹出123
driver.execute_script("alert(‘123‘)")
这一块自动化测试用的挺多的,想学自动化测试的同学可以多学习下。
通过page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery等)来提取信息了。
selenium自己也提供了提取节点信息的方法,如属性、文本等。这样的话,我们就可以不用通过解析源代码来提取信息了,非常方便。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as E
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
# 访问亚马逊首页
driver.get("https://www.amazon.cn/")
# 显示等待10秒
wait = WebDriverWait(driver, 10)
# 判断元素是否被加载到了dom中
wait.until(E.presence_of_element_located((By.ID,‘cc-lm-tcgShowImgContainer‘)))
# 通过选择器找到这个元素
tag=driver.find_element(By.CSS_SELECTOR,‘#cc-lm-tcgShowImgContainer img‘)
#获取标签属性,
print(tag.get_attribute(‘src‘))
#获取标签ID,位置,名称,大小(了解)
print(tag.id)
print(tag.location)
print(tag.tag_name)
print(tag.size)
driver.close()
在selenium中,get()方法会在页面框加载结束后,结束执行。此时如果获得get_source,可能不是浏览器完全加载完成后的页面,某些额外的js,ajax可能不一定获取到,所以需要延时等待一下,确保节点加载出来了,这里等待的方式有2中:显式等待和隐式等待。
1 显式等待
上个例子就用到了显式等待,显式等待会设置一个固定的等待时间,但是实际情况是由于外界因素的影响,我们也不可能判断出需要多少时间,所有显示等待还有一种写法,如果在规定时间加载出了这个节点,就对这个节点进行操作,如果没有加载出,就抛出超时异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as E
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
driver.get(‘https://www.baidu.com/‘)
input_tag = driver.find_element_by_id(‘kw‘)
input_tag.send_keys(‘美女‘)
# 模拟键盘回车键
input_tag.send_keys(Keys.ENTER)
# 创建一个显式等待
wait = WebDriverWait(driver, 10)
# 等待直到加载出content_left(content是左半区)
wait.until(E.presence_of_element_located((By.ID, ‘content_left‘)))
content = driver.find_element(By.CSS_SELECTOR, "#content_left")
print(content)
driver.close()
如果将webDriverWait中的时间设置过低,会报错:

2 隐式等待
当使用隐式等待执行测试的时候,如果Selenium没有在DOM中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
# 设置隐式等待
driver.implicitly_wait(10)
driver.get(‘https://www.baidu.com/‘)
input_tag = driver.find_element_by_id(‘kw‘)
input_tag.send_keys(‘NBA‘)
# 模拟键盘回车键
input_tag.send_keys(Keys.ENTER)
content = driver.find_element(By.CSS_SELECTOR, "#content_left")
print(content)
driver.close()
使用selenium还可以对cookie进行操作,获取,添加,删除cookie:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(‘https://www.zhihu.com/explore‘)
# 获取cookie
print(driver.get_cookies())
# 添加cookie
driver.add_cookie({‘name‘: ‘name‘, ‘domain‘: ‘www.zhihu.com‘, ‘value‘: ‘germey‘})
print(driver.get_cookies())
# 删除cookie
driver.delete_all_cookies()
print(driver.get_cookies())
[{‘domain‘: ‘.zhihu.com‘, ‘httpOnly‘: False, ‘name‘: ‘l_n_c‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘1‘}, {‘domain‘: ‘www.zhihu.com‘, ‘expiry‘: 1555763561.220174, ‘httpOnly‘: False, ‘name‘: ‘tgw_l7_route‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘537a925d07d06cecbf34cd06a153f671‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1650370661.220268, ‘httpOnly‘: False, ‘name‘: ‘q_c1‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘9ca2467feeaa4987a63360951034c876|1555762662000|1555762662000‘}, {‘domain‘: ‘www.zhihu.com‘, ‘httpOnly‘: False, ‘name‘: ‘_xsrf‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘270095e8c0bc05224a3eb61674d59ce0‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1558354661.220341, ‘httpOnly‘: False, ‘name‘: ‘r_cap_id‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘"ZjhkMmMxZWE5NjlhNDY3OWE4ODA1NjI4MjhkYzc0Y2Y=|1555762662|257a989723432c66a22d10794cd998b22d419794"‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1558354661.220391, ‘httpOnly‘: False, ‘name‘: ‘cap_id‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘"NTY2OWZiYmI2ODdlNDFkZWE1MzBiZTEyYTQ5MDFmYzk=|1555762662|5c5e5d6a7150c0da99f86af9d85cc63cafbea752"‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1558354661.220438, ‘httpOnly‘: False, ‘name‘: ‘l_cap_id‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘"Njk2NWI1ZTIxYjg2NGZhZDhiOGJiYjM5ODg0Y2U2ZmM=|1555762662|6a4e7d4ab33c72012e5bf133ffadfe34aa88b8eb"‘}, {‘domain‘: ‘.zhihu.com‘, ‘httpOnly‘: False, ‘name‘: ‘n_c‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘1‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1650370664.061236, ‘httpOnly‘: False, ‘name‘: ‘d_c0‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘"AJDm50C_Tg-PTkHkupcfIBQqf8xnPhGsu4M=|1555762665"‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1633522664.358119, ‘httpOnly‘: False, ‘name‘: ‘_xsrf‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘mzatpYVVTALiHdu45yqz9q4yljxCPZ7n‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1618834664, ‘httpOnly‘: False, ‘name‘: ‘_zap‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘ec95407d-3b81-4e43-81d5-277adf4b33b9‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1618834664, ‘httpOnly‘: False, ‘name‘: ‘__utma‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390.2113439272.1555762665.1555762665.1555762665.1‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1555764464, ‘httpOnly‘: False, ‘name‘: ‘__utmb‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390.0.10.1555762665‘}, {‘domain‘: ‘.zhihu.com‘, ‘httpOnly‘: False, ‘name‘: ‘__utmc‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1571530664, ‘httpOnly‘: False, ‘name‘: ‘__utmz‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390.1555762665.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1618834664, ‘httpOnly‘: False, ‘name‘: ‘__utmv‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390.000--|3=entry_date=20190420=1‘}]
[{‘domain‘: ‘.zhihu.com‘, ‘httpOnly‘: False, ‘name‘: ‘l_n_c‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘1‘}, {‘domain‘: ‘www.zhihu.com‘, ‘expiry‘: 1555763561.220174, ‘httpOnly‘: False, ‘name‘: ‘tgw_l7_route‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘537a925d07d06cecbf34cd06a153f671‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1650370661.220268, ‘httpOnly‘: False, ‘name‘: ‘q_c1‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘9ca2467feeaa4987a63360951034c876|1555762662000|1555762662000‘}, {‘domain‘: ‘www.zhihu.com‘, ‘httpOnly‘: False, ‘name‘: ‘_xsrf‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘270095e8c0bc05224a3eb61674d59ce0‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1558354661.220341, ‘httpOnly‘: False, ‘name‘: ‘r_cap_id‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘"ZjhkMmMxZWE5NjlhNDY3OWE4ODA1NjI4MjhkYzc0Y2Y=|1555762662|257a989723432c66a22d10794cd998b22d419794"‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1558354661.220391, ‘httpOnly‘: False, ‘name‘: ‘cap_id‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘"NTY2OWZiYmI2ODdlNDFkZWE1MzBiZTEyYTQ5MDFmYzk=|1555762662|5c5e5d6a7150c0da99f86af9d85cc63cafbea752"‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1558354661.220438, ‘httpOnly‘: False, ‘name‘: ‘l_cap_id‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘"Njk2NWI1ZTIxYjg2NGZhZDhiOGJiYjM5ODg0Y2U2ZmM=|1555762662|6a4e7d4ab33c72012e5bf133ffadfe34aa88b8eb"‘}, {‘domain‘: ‘.zhihu.com‘, ‘httpOnly‘: False, ‘name‘: ‘n_c‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘1‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1650370664.061236, ‘httpOnly‘: False, ‘name‘: ‘d_c0‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘"AJDm50C_Tg-PTkHkupcfIBQqf8xnPhGsu4M=|1555762665"‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1633522664.358119, ‘httpOnly‘: False, ‘name‘: ‘_xsrf‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘mzatpYVVTALiHdu45yqz9q4yljxCPZ7n‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1618834664, ‘httpOnly‘: False, ‘name‘: ‘_zap‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘ec95407d-3b81-4e43-81d5-277adf4b33b9‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1618834664, ‘httpOnly‘: False, ‘name‘: ‘__utma‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390.2113439272.1555762665.1555762665.1555762665.1‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1555764464, ‘httpOnly‘: False, ‘name‘: ‘__utmb‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390.0.10.1555762665‘}, {‘domain‘: ‘.zhihu.com‘, ‘httpOnly‘: False, ‘name‘: ‘__utmc‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1571530664, ‘httpOnly‘: False, ‘name‘: ‘__utmz‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390.1555762665.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)‘}, {‘domain‘: ‘.zhihu.com‘, ‘expiry‘: 1618834664, ‘httpOnly‘: False, ‘name‘: ‘__utmv‘, ‘path‘: ‘/‘, ‘secure‘: False, ‘value‘: ‘51854390.000--|3=entry_date=20190420=1‘}, {‘domain‘: ‘www.zhihu.com‘, ‘expiry‘: 2186482664, ‘httpOnly‘: False, ‘name‘: ‘name‘, ‘path‘: ‘/‘, ‘secure‘: True, ‘value‘: ‘germey‘}]
[]
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchFrameException
try:
driver = webdriver.Chrome()
driver.get(‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘)
driver.switch_to.frame(‘iframssseResult‘)
except TimeoutException as e:
print(e)
except NoSuchFrameException as e:
print(e)
finally:
driver.close()
超时等待哪里就可以这样写。
phantomJs是一款无界面的浏览器,其自动化操作流程和上面的谷歌浏览器是一致的。
由于是无界面的,为了能够展示自动化操作流程,PhantomJS为用户提供了一个截屏的功能,使用save_screenshot函数实现。
from selenium import webdriver
import time
# exe路径
path = r‘C:\phantomjs-2.1.1-windows\bin\phantomjs.exe‘
driver = webdriver.PhantomJS(path)
driver.get("https://www.baidu.com")
time.sleep(2)
driver.save_screenshot(r‘baidu.png‘)
my_input = driver.find_element_by_id(‘kw‘)
my_input.send_keys(‘nba‘)
driver.save_screenshot(r‘nba.png‘)
# 查找搜索按钮
button = driver.find_elements_by_class_name(‘s_btn‘)[0].click()
time.sleep(3)
driver.save_screenshot(r‘show.png‘)
driver.close()
driver.quit()
使用selenum+phantomJs可以解决某些网页js动态加载问题。
首先来看下这个页面:https://movie.douban.com/typerank?type_name=%E6%81%90%E6%80%96&type=20&interval_id=100:90&action=
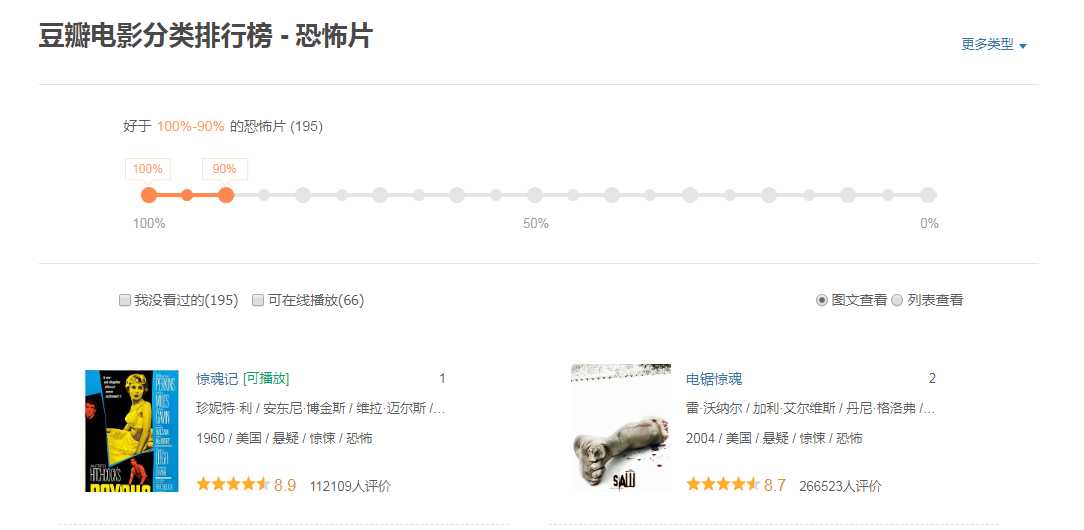
查看他的网页源代码:发现它是js动态加载显示的
from selenium import webdriver
import time
def main():
path = r‘C:\phantomjs-2.1.1-windows\bin\phantomjs.exe‘
driver = webdriver.PhantomJS(path)
driver.get(url)
time.sleep(2)
driver.save_screenshot(r‘1.png‘)
driver.execute_script(‘window.scrollTo(0,document.body.scrollHeight)‘)
time.sleep(2)
driver.save_screenshot(‘2.png‘)
time.sleep(1)
html_source = driver.page_source
with open(‘source.html‘, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html_source)
driver.quit()
if __name__ == "__main__":
url = ‘https://movie.douban.com/typerank?type_name=%E6%81%90%E6%80%96&type=20&interval_id=100:90&action=‘
main()
这样就可以拿到它的源码了:

由于phantomJs已经停止了更新和维护,所以推荐使用谷歌的无头浏览器,这是一款无界面的谷歌浏览器
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
# 创建一个无头浏览器对象
chrome_options = Options()
# 设置它为无框模式
chrome_options.add_argument(‘--headless‘)
# 如果在windows上运行需要加代码
chrome_options.add_argument(‘--disable-gpu‘)
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(‘https://www.baidu.com/‘)
sleep(2)
browser.save_screenshot(‘first_page.png‘)
browser.quit()
单独写了一篇博客:https://www.cnblogs.com/xiaozx/p/10744604.html
标签:正则表达 scripts original input 优化 dir csr 节点 val
原文地址:https://www.cnblogs.com/xiaozx/p/10738129.html