标签:work src code ram coder 性能 ash enter connected
发表于2016年,作者 Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla, Senior Member
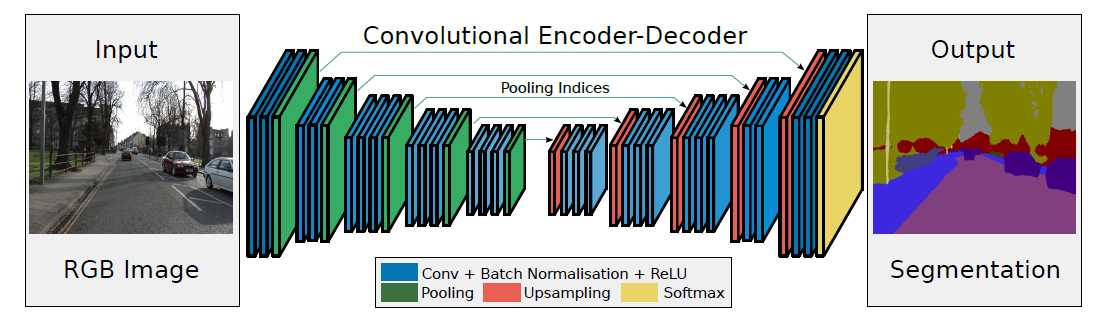
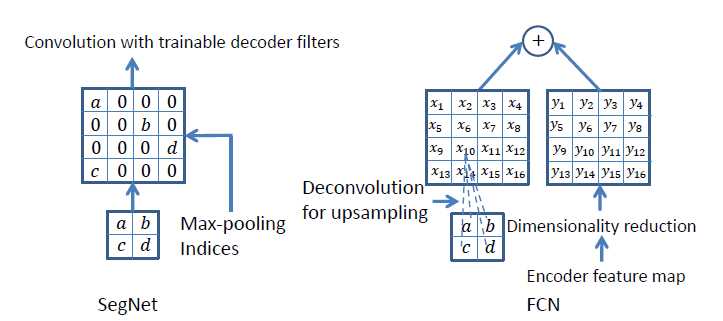
在 encoder 部分的最大池化操作时记录了最大值所在位置(索引),然后在 decoder 时通过对应的池化索引实现非线性上采样,这样在上采样阶段就无需学习。上采样后得到的是一个稀疏特征图,再通过普通的卷积得到稠密特征图,再重复上采样。最后再用激活函数得到onehot 分类结果。SegNet 主要比较的是 FCN,FCN解码时用反卷积操作来获得特征图,再和对应 encoder 的特征图相加得到输出。SegNet 的优势就在于不用保存整个 encoder 部分的特征图,只需保存池化索引,节省内存空间;第二个是不用反卷积,上采样阶段无需学习,尽管上采样完以后还要卷积学习。
对RGB的输入图像做 local contrast normalization,参数初始化用了 he_normal。
参数量,运行时间,内存消耗。
全局精度,分类平均精度,miou,边界精度(semantic contour score,图像对角线0.75%个像素的边界误差计算F1-score)[57,58,59]。这些指标都在权重根据类别调整和未调整两个状态下进行了评估
1、不同 decoder 变体性能比较,主要是 SegNet 和 FCN 的变体,来说明 SegNet 的内存节省和 encoder 部分特征图的重要性

2、用了两个数据集(道路景象分割,室内景象分割),来比较 SegNet 和传统方法,以及 SegNet 和其余的深度学习方法(不同迭代次数下比较)
SegNet 虽然在精确度上没有提升,但是考虑到实际操作时的内存和时间消耗,SegNet 表现很好。未来希望设计效率更高的网络,实现实时分割。同时也对深度学习分割结构的预测不确定性感兴趣[69,70]。
最大池化为了实现平移不变性,在图片有微小平移时依然可以鲁棒。同时最大值一定程度上反映的是边界信息
[2] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in CVPR, pp. 3431–3440, 2015.
[3] C. Liang-Chieh, G. Papandreou, I. Kokkinos, K. Murphy, and A. Yuille, “Semantic image segmentation with deep convolutional nets and fully connected crfs,” in ICLR, 2015.
[4] H. Noh, S. Hong, and B. Han, “Learning deconvolution network for semantic segmentation,” in ICCV, pp. 1520–1528, 2015.
[57] G. Csurka, D. Larlus, F. Perronnin, and F. Meylan, “What is a good evaluation measure for semantic segmentation?.,” in BMVC, 2013.
[58] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in https://arxiv.org/pdf/1605.06211v1.pdf, 2016.
[59] D. R. Martin, C. C. Fowlkes, and J. Malik, “Learning to detect natural image boundaries using local brightness, color, and texture cues,” IEEE transactions on pattern analysis and machine intelligence, vol. 26, no. 5,pp. 530–549, 2004.
[69] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Insights and applications,” in Deep Learning Workshop, ICML, 2015.
[70] A. Kendall, V. Badrinarayanan, and R. Cipolla, “Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding,” arXiv preprint arXiv:1511.02680, 2015.
编辑于 2019-04-21 19:36:13
标签:work src code ram coder 性能 ash enter connected
原文地址:https://www.cnblogs.com/tccbj/p/10746406.html