标签:target 个数 parse 适合 相加 基本 之间 本质 ble
| NAME | ID | TRAFFIC |
| YY | 1001 | 204 |
| ID | BOSS |
| 1001 | 若老 |
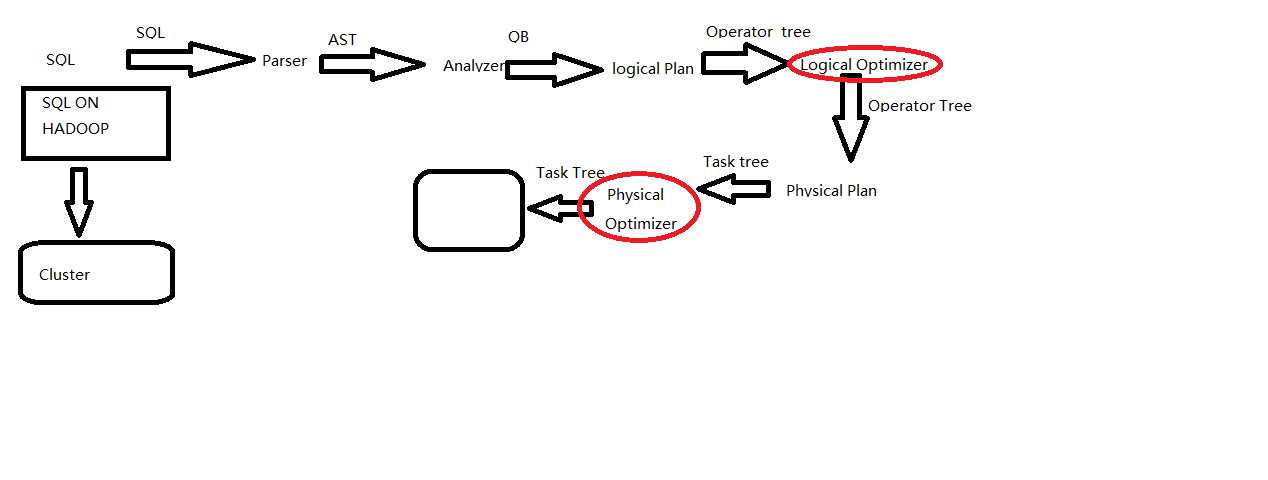
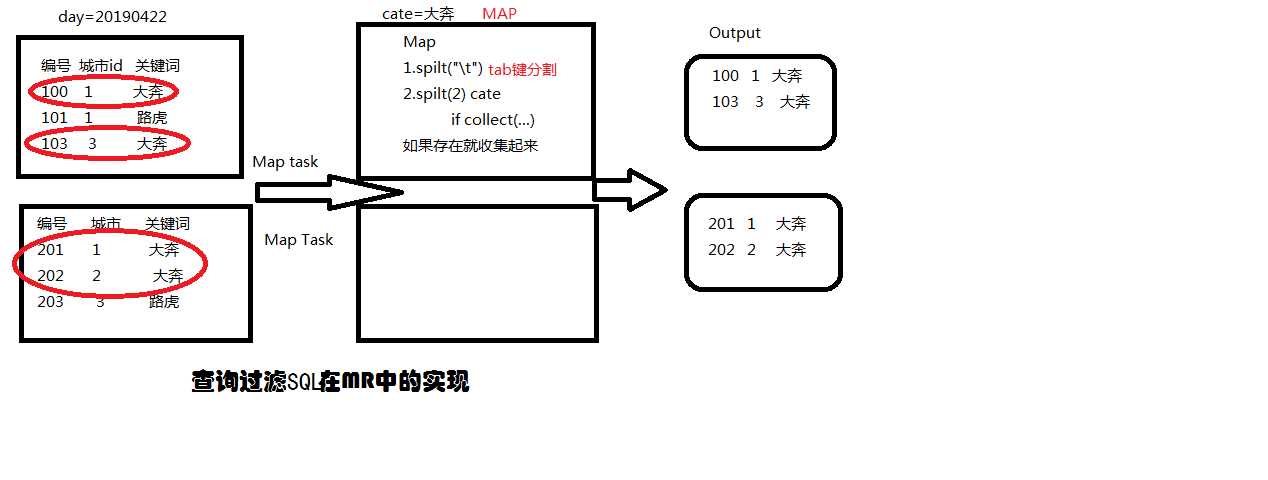
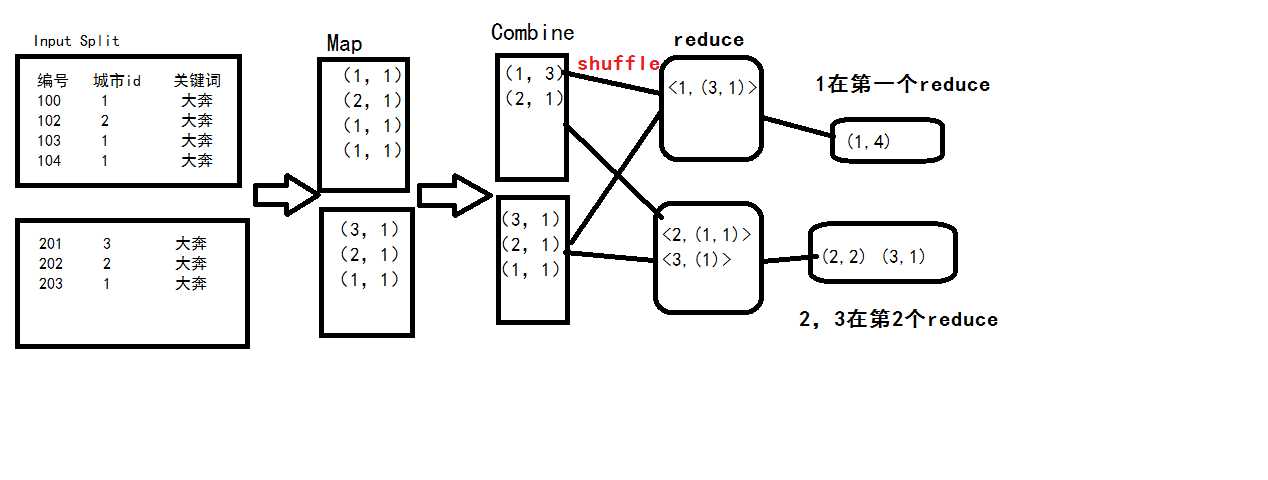 结论:
结论:作者:qq_32641659
来源:CSDN
原文:https://blog.csdn.net/qq_32641659/article/details/89421655
版权声明:本文为博主原创文章,转载请附上博文链接!
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
标签:target 个数 parse 适合 相加 基本 之间 本质 ble
原文地址:https://www.cnblogs.com/xuziyu/p/10750772.html