标签:pil .so imp inpu 举例 ccf 替代 tor 配置
Python 安装
centos 6
Linux 系统自带 python 2.6
centos 7
Linux 系统自带 python 2.7
python -V #查看版本
windowns 需要手动安装,和一般软件安装没有区别,一直下一步下一步。
默认在C盘下的python2.X目录下。需要手动加入系统环境变量里
下载地址 : https://www.python.org/downloads/windows/
Python 有2.X 和3.X 的版本,版本不同,语法也有所变化,个人而言相对来讲,python3必定是未来的趋势也比Python2的语法简化了,但python2 使用的也有多,也是有Linux的自带的软件,所以两者都需要去学习
python 作为一种解析性语言,运行速度和编译性语言相比是非常慢的,但它简洁的语法使其广受欢迎
linux 上安装自定义版本python2
命令行内,直接Python 就可以进入命令行的交互模式

为了更友好的显示和补全代码,我们可以使用 ipython 这个软件
python 会自带pip命令
使用pip 命令去下载 ipython
命令如下:
ipython pip install ipython
pip : 需要配置yum 的epel 源(centos )
yum install -y python-pip
默认会去安装最新的
pip是去这个网站找包下载的 : pypi.python.org/pypi/ipython

因为默认回去下载最新版本的ipython
但它不适用于我们需要用到python2.6这个版本的软件
所以需要指定安装其适用版本
centos 6
命令: pip install ipython==1.2.1
适用于 python2.6
centos 7
命令: pip install ipython==1.2.2
适用于 python2.7
Python 自带一个虚拟环境,和真实环境一样,切互不干扰
ENV 虚拟环境打开与关闭 activate / deactivate
Python 后缀名的简介
简介Python 源代码以及字节代码,优化编译
这是1.py 文件的开头,即源代码#!/usr/bin/pythonprint "hello world"‘
执行 python 1.py 即可运行
1.源代码
python源代码文件以"py"为扩展名,由python程序解析,不需要编译
直接运行 /usr/bin/python 1.py 即可
2.字节代码
python源码文件经编译后生成的扩展名为"pyc"文件
编译方法:import py_compilepy_compile.compile("1.py")
使其编译后生成pyc的后缀名文件,为二进制文件
优化编译
python -O -m py_compile 1.py
-O : 代表优化编译
-m : 指定模块mode
使其源码文件优化编译成"pyo"后缀名的二进制文件
因为是二进制文件,所以查看出来的是都是乱码
总结:
Python解释器,字节码文件只能被Python识别
字节码文件
.pyc .pyo
转换成 .pycpython -m py_compile hello.py
.pyc提高 加载速度 运行效率是一样
转换成 .pyopython -O -m py_compile hello.py
.pyo优化 优化编译
变量
变量是计算机内存的一块区域,变量可以存储规定范围内的值,而且值可以改变
python下变量是对一个数据的引用
变量的命名
变量名由字母,数字,下划线组成
变量不能用数字开头
不可以使用关键字
变量的赋值
是变量的申明和定义的过程
a = 1 #整型
a = ‘1‘ #字符型
id(a)
type(a) #可以查看变量的类型
赋值运算符
= : x = 3, y = ‘abcd‘
+=: x += 2
-=: x -= 2
*=: x *= 2
/=: x /= 2
%=: x %= 2
算术运算符
+ : 加
- : 减
* : 乘
/ : 除
// : 整除,只取整数部分
% : 取余,取余数
** : 乘方
字符串的+ 相当于连接两个字符串
关系运算符,返回结果为布尔值,即true和false (0和1)
> : 大于
< : 小于
>= : 大于等于
<= : 小于等于
== : 等于
!= : 不等于
逻辑运算符 优先级最高
and 逻辑 与
or 逻辑 或
not 逻辑 非
读取键盘输入函数input()
会区别数字和字符串,如果是不加引号字符串即为变量,如果加,即为输出
raw_input()
无论是什么都当成字符串输出
#!/usr/bin/python
a = 8
b = 4
num1 = input("first number: ")
num2 = input("last number: ")
print "%s + %s = %s" % (num1,num2,num1+num2)
print "%s - %s = %s" % (num1,num2,num1-num2)
print "%s *%s = %s" % (num1,num2,num1*num2)
print "%s / %s = %s" % (num1,num2,num1/num2)
"%s" % (sum1,sum2,sum1+sum2)
格式化字符串,也可当占位符,后面括号内的变量一一对应
数值和字符串
python 数据类型
数值,字符串,列表,元组,字典
Python 数值类型
整型,长整型,浮点型(float),复数型,
用 type(a) 来查看数值类型
2的32次方 一共有这么多值 4294967296
In [1]: 2 ** 32
Out[1]: 4294967296
范围在 -2147483648 ~ 2147483647 (中间包涵0)
除数与被除数 只要有浮点数,结果就有浮点型
字符串类型
在shell 里,单引号全部引用,双引号部分引用
三种方法定义字符串 类型
str = ‘this is a string‘
str = "this is a string"
str = ‘‘‘this is a string‘‘‘ 或者 “““ this is a string ”””
自动带入换行符,更友好的显示
三重引号: 除了能定义字符串还可以用作注释
字符串它也是个序列
我们可以对它进行 索引 和 切片 操作
索引用 a[1]
切片是 步进值。相隔多少取多少
a = ‘ABCDEFG‘
a[0:5:2]
0:0和空都是从头开始,即从A开始。比如1,即从‘B’开始。比如2,即从C开始。
5:5看成个数,5个数,即为‘ABCDE’,3个数,即为‘ABC’。
2:步进值,即切片。即相隔1个数,为‘ACE’。比如3,即相隔3个数,中间相隔2位数‘AD‘,相隔BC两位数。以此类推。
总结:
Python中数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可
以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类
型有以下几种:
一、整数
Python可以处理任意大小的整数,当然包括负整数,在Python程序中,整数的表示方法和数学上的写法一模一样,例如:1,100,-8080
,0,等等。
计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2
,等等。
二、浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x10^9和
12.3x10^8是相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示
,把10用e替代,1.23x10^9就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四
舍五入的误差。
三、字符串
字符串是以‘‘或""括起来的任意文本,比如‘abc‘,"xyz"等等。请注意,‘‘或""本身只是一种表示方式,不是字符串的一部分,因此,字
符串‘abc‘只有a,b,c这3个字符。
四、布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、
False表示布尔值(请注意大小写),也可以通过布尔运算计算出来。
布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为 True,and运算结果才是 True。
or运算是或运算,只要其中有一个为 True,or 运算结果就是 True。
not运算是非运算,它是一个单目运算符,把 True 变成 False,False 变成 True。
五、空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
python 元组
序列
1. len() : 求序列的长度
2. + : 连接2个序列
3. * : 重复序列元素
4. in : 判断元素是否在序列中
5. man() : 返回最大值,可以判断字符
6. min() : 返回最小值
7. cmp(x,y) : 比较两个序列是否相等
x > y 返回 1
x = y 返回 0
x < y 返回 -1
元组(tuple) 和列表相似
1.元组合字符串一样是 不可变 的
2.通常用于接收函数的返回值
3.元组可以存储一系列的值
4.元组通常用在用户定义的函数能够安全地采用一组值的时候,即被使用的元组的值不会被改变
元组 里面要有逗号,元组内还可存多个元组t = ( a, 1, (1, c ) )
元组操作
元组和字符串一样属于序列类型,可以通过索引和切片操作
元组值不可变
元组拆分
t = (1,2,3)
a, b, b = t
b = (a, ‘b‘, ‘c‘)
输出 b
得 (‘abcde‘, ‘b‘, ‘c‘)
python 面向对象, 里面一切都是对象(变量,元组,字符串,数值)
t = (‘a‘,a,‘c‘)
t. 这样看他可用的方法
t.count t.index 两种方法
通过help(t.count) 查看用法
count(...)
T.count(value) -> integer -- return number of occurrences of value
这个value 在当前的元组里,则返回一个整数,
即判断这个值是不是在元组里,如果是在返回 1 ,不在返回 0
通过help(t.index) 查看用法
index(...)
T.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
这个值返回的索引
[start, [stop]] 是它的可选选项
列表用 [ ] 元组用 ( )
列表 可变类型的数据结构
列表(list) 是处理一组有序项目的数据结构,即可以在列表中存储一个序列的项目
列表是可变类型的数据
创建列表
list = []
list1 = list()
list2 = [‘a‘,1,2]
列表操作
取值
切片和索引
添加list.append( )
删除del list[ ]list.remove(list[ ])
remove(...)
L.remove(value) -- remove first occurrence of value.
Raises ValueError if the value is not present.
修改list[ ] = x
查找var in list || var not in list
方法list.append : 在最后加入
list.count : 统计指定元素个数
list.extend : 可迭代,列表追加,字符串,元组,列表,都是可迭代的,这样都是可以for循环
list.index : 索引
list.insert : 指定索引,插入
list.pop : 删除并返回删除的值,不指定索引位置,即为从最后一个剪切
In : list
Out: [‘1‘, ‘2‘, ‘3‘]
In : list.pop()
Out: ‘3‘
In : list.pop()
Out: ‘2‘
In : list
Out: [‘1‘]
list.remove : 删除一个元素
删除list中的某个元素,一般有三种方法:remove、pop、del
1.remove: 删除单个元素,删除首个符合条件的元素,按值删除
举例说明:
str=[1,2,3,4,5,2,6]
str.remove(2)
str
[1, 3, 4, 5, 2, 6]
2.pop: 删除单个或多个元素,按位删除(根据索引删除)
str=[0,1,2,3,4,5,6]
str.pop(1) #pop删除时会返回被删除的元素
1
str
[0, 2, 3, 4, 5, 6]
str2=[‘abc‘,‘bcd‘,‘dce‘]
str2.pop(2)
‘dce‘
str2
[‘abc‘, ‘bcd‘]
3.del:它是根据索引(元素所在位置)来删除
举例说明:
str=[1,2,3,4,5,2,6]
del str[1]
str
[1, 3, 4, 5, 2, 6]
str2=[‘abc‘,‘bcd‘,‘dce‘]
del str2[1]
str2
[‘abc‘, ‘dce‘]
除此之外,del还可以删除指定范围内的值。
str=[0,1,2,3,4,5,6]
del str[2:4] #删除从第2个元素开始,到第4个为止的元素(但是不包括尾部元素)
str
[0, 1, 4, 5, 6]
del 也可以删除整个数据对象(列表、集合等)
str=[0,1,2,3,4,5,6]
del str
str #删除后,找不到对象
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
str
NameError: name ‘str‘ is not defined
注意:del是删除引用(变量)而不是删除对象(数据),对象由自动垃圾回收机制(GC)删除。
补充: 删除元素的变相方法
s1=(1,2,3,4,5,6)
s2=(2,3,5)
s3=[]
for i in s1:
if i not in s2:
s3.append(i)
print ‘s1-1:‘,s1
s1=s3
print ‘s2:‘,s2
print ‘s3:‘,s3
print ‘s1-2:‘,s1
list.reverse : 将列表内的元素,反转
In : list
Out: [‘g‘, ‘f‘, ‘e‘, ‘d‘, ‘c‘, ‘b‘, ‘a‘]
In : list.reverse()
In : list
Out: [‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘f‘, ‘g‘]
list.sort : 排序 ,升序
In : list.reverse()
In : list
Out: [‘6‘, ‘5‘, ‘4‘, ‘3‘, ‘2‘, ‘1‘]
In : list.sort()
In : list
Out: [‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘]
字典(dict) { }
字典方法
keys( ) : 返回所有的keys ,列表显示
values( ) : 返回所有的values, 列表显示
items( ) : 返回一个列表
In : dic
Out: {‘a‘: ‘1‘, ‘b‘: ‘abcsss‘, ‘c‘: ‘123aaa‘}
In : dic.items()
Out: [(‘a‘, ‘1‘), (‘c‘, ‘123aaa‘), (‘b‘, ‘abcsss‘)]
dic.get(k) 返回K对应的values值,如果key不存在,则返回空
D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.
dic.has_key(‘k‘) : 查看有没有这个Key
dic.copy : 复制字典
dic.clear : 清除
dic.pop(k) : 弹出k,并返回弹出的values
pop(...)
D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
If key is not found, d is returned if given, otherwise KeyError is raised
dic.update() : 更新字典
字典(Dictionary) update() 函数把字典dict2的键/值对更新到dict里。
update()方法语法:
dict.update(dict2)
dict2 -- 添加到指定字典dict里的字典。
help(dic.update()) #查看方法
update(...)
D.update([E, ]**F) -> None. Update D from dict/iterable E and F.
If E present and has a .keys() method, does: for k in E: D[k] = E[k]
If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v
In either case, this is followed by: for k in F: D[k] = F[k]
实例
以下实例展示了 update()函数的使用方法:
#!/usr/bin/python
dict = {‘Name‘: ‘Zara‘, ‘Age‘: 7}
dict2 = {‘Sex‘: ‘female‘ }
dict.update(dict2)
print "Value : %s" % dict
以上实例输出结果为:
Value : {‘Age‘: 7, ‘Name‘: ‘Zara‘, ‘Sex‘: ‘female‘}
创建字典
dic = {}
dic = dict()
dict(([‘a‘,1],[‘b‘,2]))
In : dict(x=1,y=2)
Out: {‘x‘: 1, ‘y‘: 2}
fromkeys() 字典元素有相同的值,默认为None.ddict = {}.fromkeys((‘x‘,‘y‘),100)
fromkeys(...)
dict.fromkeys(S[,v]) -> New dict with keys from S and values equal to v.
v defaults to None.
S 是序列,这序列有key
In : dic.fromkeys(‘abc‘)
Out: {‘a‘: None, ‘b‘: None, ‘c‘: None}
In : dic.fromkeys(‘abc‘,10)
Out: {‘a‘: 10, ‘b‘: 10, ‘c‘: 10}
In : dic.fromkeys(range(5),10)
Out: {0: 10, 1: 10, 2: 10, 3: 10, 4: 10}
dic.items : 显示为,列表+元组 [()] 这样的组合
In : dit = {‘a‘:a,‘b‘:‘b‘}
In : dit.items()
Out: [(‘a‘, ‘abcsss‘), (‘b‘, ‘b‘)]
range() 函数 : 是从0开始 指定到的数。
range(5) 即为 0到4 5个数
In : range(5)
Out: [0, 1, 2, 3, 4]
字典练习
raw_input 读取的为字符串
info = {}
name = raw_input("input name: ")
age = raw_input("input age:")
存入字典info[ ‘name‘] = nameinfo [‘age‘] = age
print info.items() 变成列表+元组
for k, v in info.items() :
print k + ":" +, v
print "%s : %s" % (k, v)
print "END"
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
语法
zip 语法:
zip([iterable, ...])
参数说明:
iterabl -- 一个或多个迭代器;
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
合并字典
【方法一】借助dict(d1.items() + d2.items())的方法

备注:
d1.items()获取字典的键值对的列表
d1.items() + d2.items()拼成一个新的列表
dict(d1.items()+d2.items())将合并成的列表转变成新的字典
【方法二】借助字典的update()方法
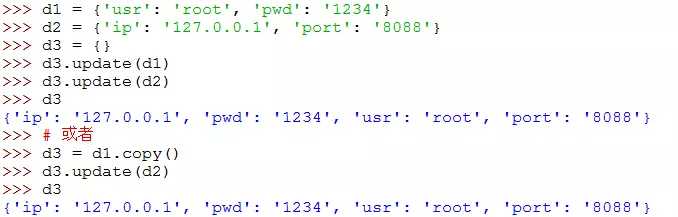
【方法三】借助字典的dict(d1, **d2)方法

【方法四】借助字典的常规处理方法

标签:pil .so imp inpu 举例 ccf 替代 tor 配置
原文地址:https://www.cnblogs.com/huidou/p/10758062.html