标签:线程安全 str node 索引 就会 并发控制 部分 href segment
又开新坑o(*≧▽≦)ツ讲讲几个Java版本的特性,先开始Java8,

HashMap采用哈希算法,先使用hashCode()判断哈希值是否相同,如果相同,再使用equals(),如果再相同,则会替换掉原先的值,如不同则形成链表,后来的放前,原先的被挤到后面去,这种情况叫碰撞,我们应该要尽量避免这种情况,所以我们要通过改进hashCode()和equals(),当然我们无法完全避免这种情况。
为了不让链表太长,HashMap提供了加载因子,0.75,当元素到达哈希表的75%时,进行扩容,如果设定到100%扩容,也许算出的哈希值就只有那几个,比如长度为16的哈希表,一直只存3,5,7,8,其他的哈希值所在的位置无人问津,这样就会产生很长的链影响性能。那么哈希值可以取很小吗?也不可以,这样会频繁扩容,浪费空间。
一旦扩容,会将链表里的元素,每个重新计算新的位置,这样碰撞概率就会变低。
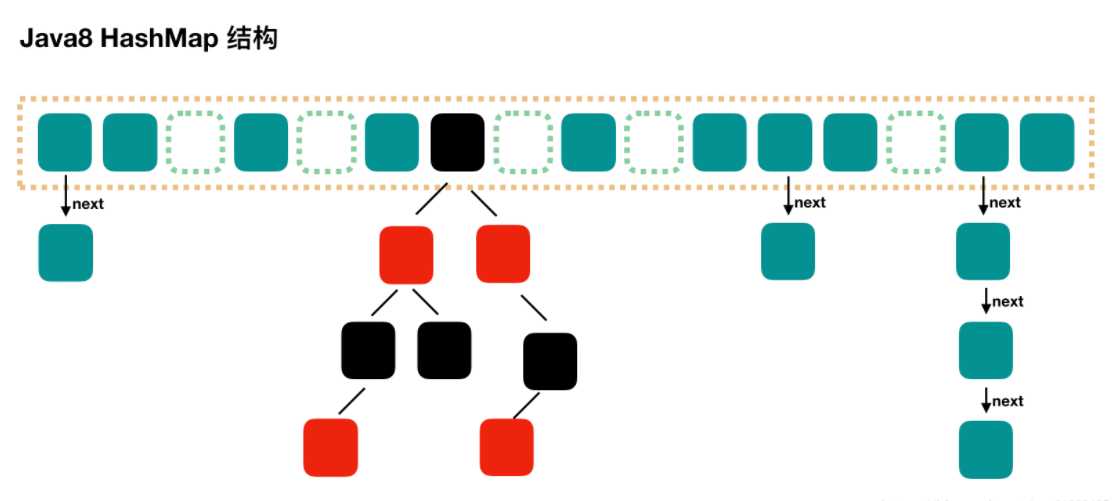
即使有这种扩容机制,但是碰撞依旧避免不了,所以意味着效率变低,打个比方,在1.8之前Java采用数组+链表方式,如果产生了冲突情况,比如我找哈希值为3的值,就要从数组索引值为3的链表头开始找,最糟糕的情况是找到这个链表的尾部,因此1.8将这种结构改进,变成数组+链表+红黑树 。
当链表上碰撞的个数大于8,总容量大于64,就会将链表转换成红黑树,这样的好处,除了添加,其他操作都要比链表快。
1.7之前,并发级别默认为16,concurrentLevel=16;现在来介绍一下ConcurrentHashMap:
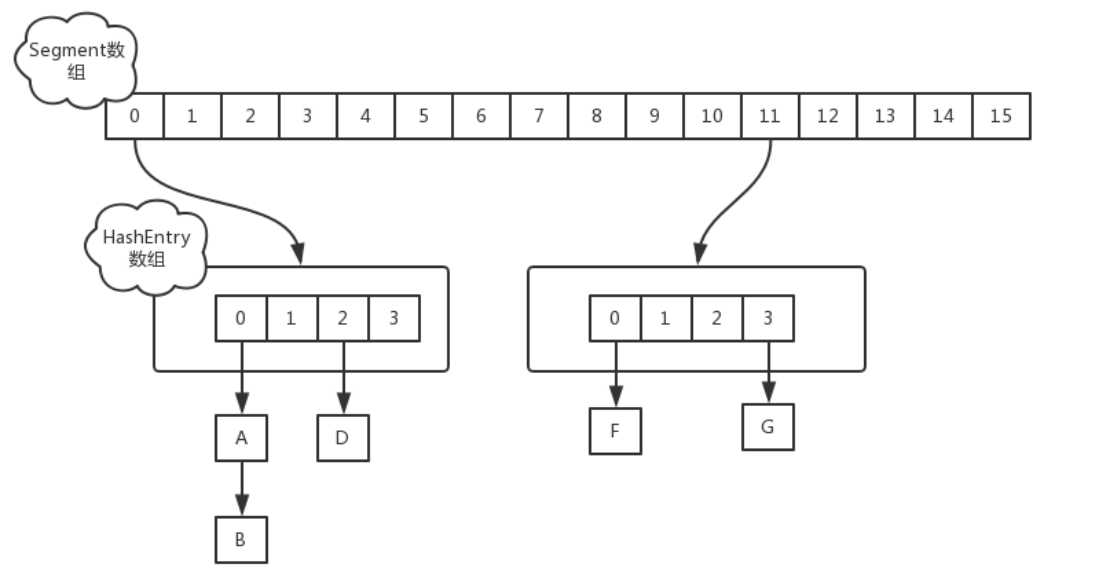
ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,主要实现原理是实现了锁分离的思路解决了多线程的安全问题,如下图所示:
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表。
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
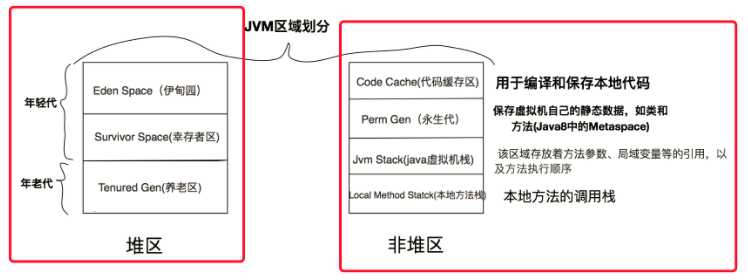
内存分为三大块,栈、堆、方法区,之前方法区其实属于堆的永久区的一部分,可是我们平常都把它分开画,因为JDK1.8取消这块方法区,取而代之的是MetaSpace(元空间),最大特色是它直接使用物理内存,而不是使用分配内存,这说明垃圾回收机制运行机制概率变低,效率提升。也就是说OutOfMemoryError,几乎不会发生。
既然如此,一些调优条件就无效了,比如PremGenSize、MaxPremGenSize,取而代之的是MetaspaceSize MaxMetaspaceSize
参考博文:
https://www.cnblogs.com/duanxz/p/3520829.html
https://www.jianshu.com/p/a7767e6ff2a2
标签:线程安全 str node 索引 就会 并发控制 部分 href segment
原文地址:https://www.cnblogs.com/figsprite/p/10758637.html