标签:整数 shell name padding 分组 限制 计算 16px 选择
本博客写是装好Mysql并配好环境变量后的基本操作(windows10系统下)且都是黑框内的操作。
一、登陆MySQL
首先启动服务,在桌面左下角图标处点击右键Windows PowerShell(管理员)(A),然后会出来个蓝框,在蓝框内输入net start mysql80(80是对应的MySQL版本如果是其他版本则输入对应的版本号,如5.7版本输入net start mysql57),然后按回车键,若显示服务已启动,则服务启动成功。
在搜索框内输入cmd则会弹出命令提示符点击进去,所谓的黑框就弹了出来,黑框不一定是黑的,可以通过右键点击左上角改变其属性,接着在黑眶内输入mysql -u root -p,按回车键,输入你的密码,敲回车,登陆成功进入MYSQL。
二、对数据库的操作
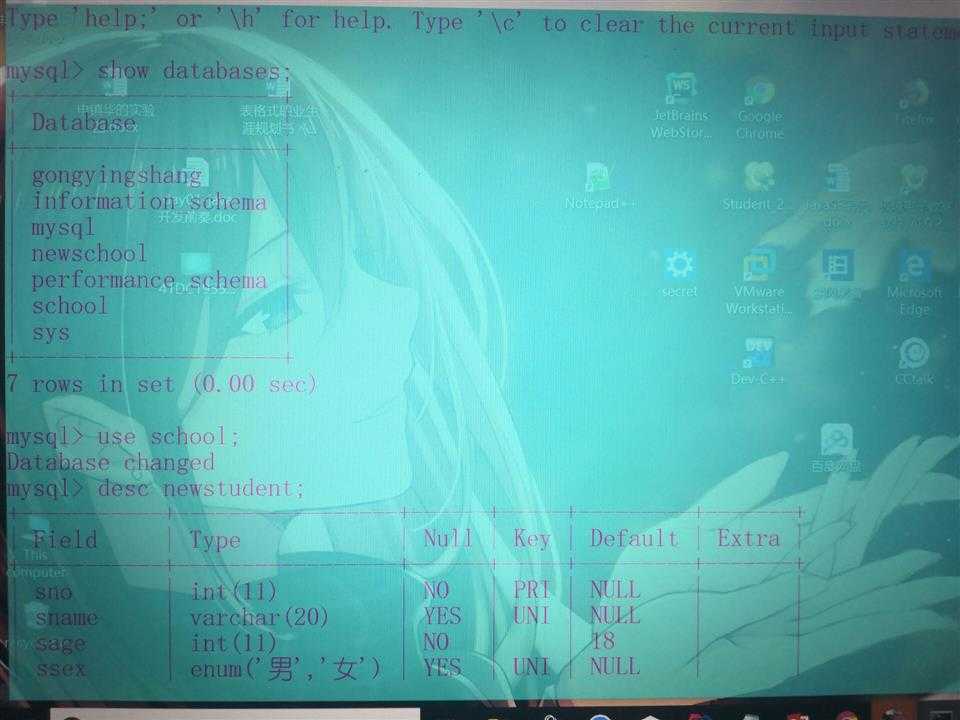
(1)查看数据库:show databases;
(2)创建数据库:create database 数据库名;
(3)使用数据库:use 数据库名;
(4)删除数据库:drop database 数据库名;
部分实例
三、对表的操作
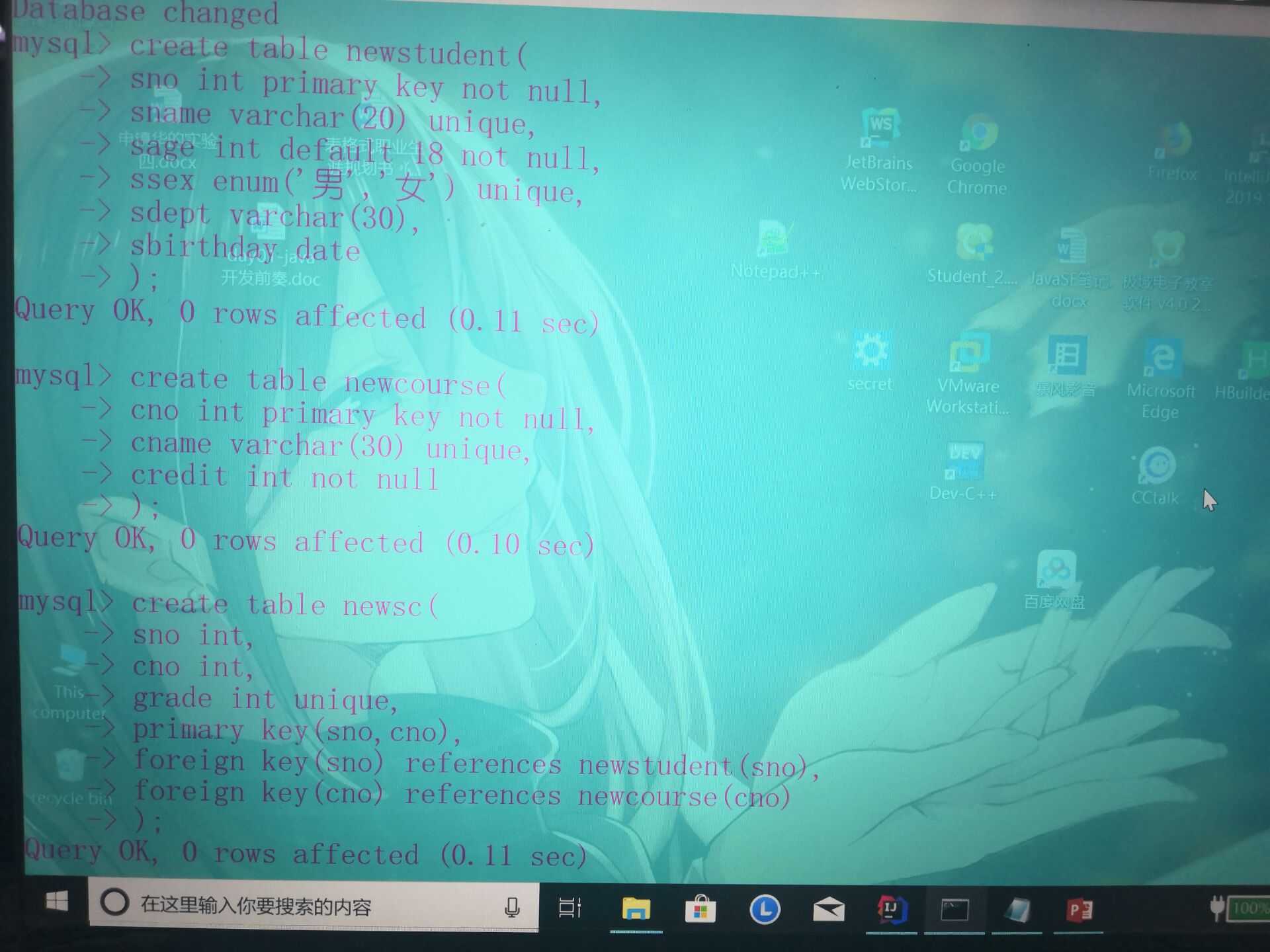
(1)创建数据表:create table 数据表名 (
属性1 类型, 属性2 类型,);
类型后边可以加限定条件:primary key(主键)、not null(不能为空)、unique(唯一的)、foreign key(外键)、default(定义初值)、
primary key:主键是一个表的特殊字段,可以唯一标识表的每条信息,主键的目的是为了快速查找表中的某条信息,主键必须是唯一的,主键值是非空的,主键可以是单一字段也可以是多个字段组合。
foreign key(外键):外键表是一个特殊的字段,设置外键原则,必须依赖于数据库已存在的父表的主键,外键可以为空值,建立改表与其父表的关联关系。foreign key(父表主键属性) references 外键名(同父表相同的属性)
not null:字段不能有空值,保证所有记录该字段都有值
unique:所有记录该字段的值不能重复出现
auto_increment:用于为表插入的新纪录自动生成唯一的id,一个表只能有一个字段使用该约束,必须为主键的一部分,约束字段可以是任何整数类型,默认值从一开始自增
default:创建表时指定该字段的默认值,当插入一条型记录没有为该字段赋值时,系统会自动为该字段插入默认值
创建表newstudent、newcourse、newsc实例
(2)删除数据表:drop table 数据表名;
(3)查询数据表
1.查看表结构:desc 数据表名;
2.查看表的详细定义:show create table 数据表名;
(4)修改基本表
alter table 修改表名,修改字段数据类型,条件约束...等等
1.修改表名:alter table 旧表名 rename 新表名;
2.修改字段的数据类型:alter table 表名 modify 属性名 数据类型;
3.修改字段名:alter table 表名 change 旧属性名 新属性名 新数据类型;
4.增加字段:alter table 表名 add 属性1 数据类型 (完整约束)first | after 属性名2; 若不设置位置,默认加到最后的位置
5.删除字段:alter table 表名 drop 属性名;
6.修改字段排列位置:alter table 表名 modify 属性1 数据类型 first | after 属性名2;
7.修改数据引擎:alter table 表名 engine = 储备引擎名;
8.删除表的外键约束:alter table 表名 drop foreign key 外键别名;
9.删除表的主键约束:alter table 表名 drop primary key;
10.删除表:drop table (if exists) 表名;
(5)索引
索引是由数据表中一列或多列组合而成,作用提高对表中数据的查询速度。优点:提高检索数据的速度,对于有依赖关系的父表和子表之间的联合查询,可以提高查询速度使用分组和排序子句进行查询时,节省查询中分组和排序时间。缺点:创建和维护索引需要浪费时间,耗费时间数量随数据量增加而增加,索引需要占用物理空间,增加,删除,修改数据时,要动态维护索引
索引的创建方式:
create table 表名 (属性名 数据类型 [完整约束],属性名 数据类型 [完整约束],[unique] index 索引名(属性名 [(长度)] [asc | desc]);
1.普通索引:这是最基本的索引,它没有任何限制。
2.唯一性索引:它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式
3.全文索引:全文索引只设置在char、varchar、text类型字段上,查询数据量较大的字符串时可以提高查找效率
4.单列索引:在表中单个字段上创建索引
5.多列索引:在表中多个字段上创建一个索引
6.空间索引
在存在的表上创建索引
create [unique | fulltext | spatial] index 索引名 on 表名 (属性名 [(长度)] [asc | desc]);
alter table 创建索引
alter table 表名 add [unique | fulltext | spatial] index 索引名 (属性名 [(长度)] [asc | desc]);
四、数据查询
1.单表查询
select [all | distinct] 属性名1,属性名2 | * from 表名1,表名2 [where 条件表达式 ] [group by 属性名 [having 条件表达式]] [order by 属性名 asc | desc ] [limit n];
distinct:去除重复
|
查 询 条 件 |
谓 词 |
|
比 较 |
=,>,<,>=,<=,!=,<>,!>,!<;NOT+上述比较运算符 |
|
确定范围 |
BETWEEN AND,NOT BETWEEN AND |
|
确定集合 |
IN,NOT IN |
|
字符匹配 |
LIKE,NOT LIKE |
|
空 值 |
IS NULL,IS NOT NULL |
|
多重条件(逻辑运算) |
AND,OR,NOT |
order by:可以按一个或多个属性列排序 asc升序 desc降序 排序时空值默认排最后
聚集函数:计数count([all | distinct] *) count([all | distinct] 列名) 计算总和sum([all | distinct] 列名) 计算平均值avg([all | distinct] 列名) 最大值max([all | distinct] 列名) 最小值min([all | distinct] 列名)
where与having差别:where用于基表或视图,从中选择满足条件的元组,having短句用于组,从中选择满足条件的组
limit(MySQL独有)两种使用方式:limit 记录数 limit 初始位置 记录数
2.连接查询
[表名1.] 列名 <比较运算符> [表名2.] 列名
[表名1.] 列名 betwee [表名2.] 列名 and [表名2.] 列名2
自身连接
复合条件连接
3.嵌套查询
一个select-from-where语句称为一个查询块
将一个查询块嵌套在另一个查询块的where子句或having语句条件中的查询成为嵌套查询
带有in关键字的子查询
带有比较运算符的子查询 (<,>,=,!=,<=,>=,<>) 与any或all谓词配合使用 any任意一个值 all所有值
带有exists谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”
合并查询 union / union all 参加集合操作的各查询结果的列数必须相同,对应项的数据类型也必须相同
标签:整数 shell name padding 分组 限制 计算 16px 选择
原文地址:https://www.cnblogs.com/shenzhenhuaya/p/15226181250_shenzhenhua02.html