标签:bsp 创新 取字符串 城市 委员会 alt port 教学 优秀
例1:
字符串: ‘湖南省长沙市岳麓区麓山南路麓山门‘
提取:湖南,长沙
在不用正则表达式的情况下:
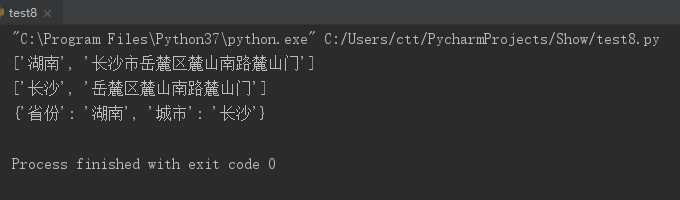
address = ‘湖南省长沙市岳麓区麓山南路麓山门‘ address1 = address.split(‘省‘) # 用“省”字划分字符串,返回一个列表 address2 = address1[1].split(‘市‘) # 用“市”字划分address1列表的第二个元素,返回一个列表 print(address1) # 输出 [‘湖南‘, ‘长沙市岳麓区麓山南路麓山门‘] print(address2) # 输出 [‘长沙‘, ‘岳麓区麓山南路麓山门‘] data = { ‘省份‘: address1[0], ‘城市‘: address2[0] } print(data) # 输出 {‘省份‘: ‘湖南‘, ‘城市‘: ‘长沙‘}
输出结果:
例二:
从一段文字中提取指定两段字符中间的字符
字符串 = ‘’师资力量学校现有教职工近4000余人,其中专任教师1800余人,教授、副教授1100余人,中国科学院院士3名,中国工程院院士3名,双聘两院院士2名,加拿大工程院院士1名,发展中国家科学院院士1名,“千人计划”53人,“万人计划”学者13人、“长江学者”15人,国家杰出青年基金获得者21人,国务院学位委员会学科评议组成员6人,入选国家百千万人才工程(“百千万人才工程”一二层次人选、新世纪百千万人才工程国家级人选)23人、国家创新人才推进计划中青年创新领军人才2人,教育部新世纪优秀人才支持计划入选者134人,湖南省“百人计划”学者64人,湖南省“芙蓉学者奖励计划”特聘教授、讲座教授17人,享受政府特殊津贴专家201人,国家教学名师4人,国家自然科学基金创新研究群体3个,教育部“长江学者与创新团队发展计划”创新团队8个,湖南省自然科学基金创新研究群体11个。(数据截止日期:2017年01月) [31] “
指定两段字符:“长江学者”与“人”,
目标字符:中间的数字“15”
正则式:
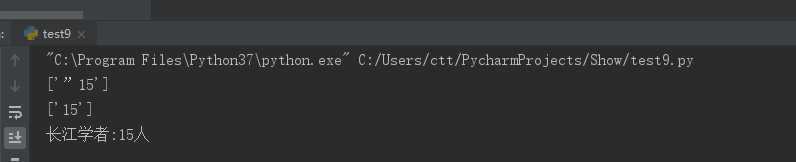
import re s = "师资力量学校现有教职工近4000余人,其中专任教师1800余人,教授、副教授1100余人,中国科学院院士3名,中国工程院院士3名," "双聘两院院士2名,加拿大工程院院士1名,发展中国家科学院院士1名,“千人计划”53人,“万人计划”学者13人、“长江学者”15人," "国家杰出青年基金获得者21人,国务院学位委员会学科评议组成员6人,入选国家百千万人才工程(“百千万人才工程”一二层次人选、" "新世纪百千万人才工程国家级人选)23人、国家创新人才推进计划中青年创新领军人才2人,教育部新世纪优秀人才支持计划入选者134人," "湖南省“百人计划”学者64人,湖南省“芙蓉学者奖励计划”特聘教授、讲座教授17人,享受政府特殊津贴专家201人,国家教学名师4人," "国家自然科学基金创新研究群体3个,教育部“长江学者与创新团队发展计划”创新团队8个,湖南省自然科学基金创新研究群体11个" "。(数据截止日期:2017年01月) [31] " # 由于字符串过长,在编译器中会要求换行,字符“\”为换行后自动添加的,不影响字符串本身 n = re.findall(r"长江学者(.+?)人", s) # 正则表达式匹配长江学者人数 提取“长江学者”和其后的“人”之间的字符,返回一个列表 print(n) num = re.findall(‘\d+‘, str(n)) # 正则表达式提取数字,返回一个列表 print(num) num = ‘长江学者:‘+num[0]+‘人‘ # 重新构建一个字符串 print(num)
运行结果:
标签:bsp 创新 取字符串 城市 委员会 alt port 教学 优秀
原文地址:https://www.cnblogs.com/cttcarrotsgarden/p/10770205.html