标签:一个 比较 www tle logs height img idt 目标
原文: http://www.cnblogs.com/AdamLee/p/5054674.html
在网上看到很多关于sql中使用in效率低的问题,于是自己做了测试来验证是否是众人说的那样。
群众:
对于in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。
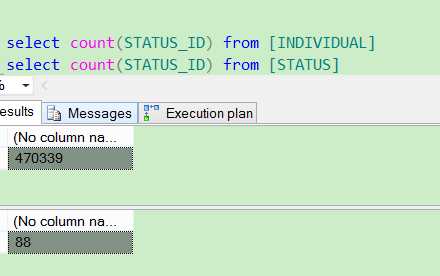
这里我找到两张表,一个是用户信息表[INDIVIDUAL] 47万条数据,一个状态类型表[STATUS] 88条数据,对应上面所述的一多一少
然后进行两种查询 (not exists 和 not in一组)(exists 和 in一组)
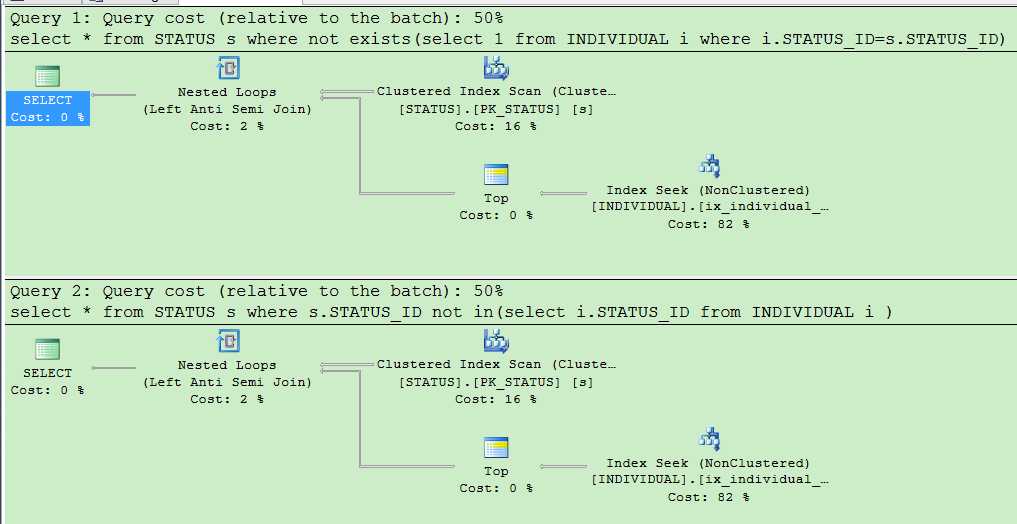
select * from STATUS s where not exists(select 1 from INDIVIDUAL i where i.STATUS_ID=s.STATUS_ID)
select * from STATUS s where s.STATUS_ID not in(select i.STATUS_ID from INDIVIDUAL i )
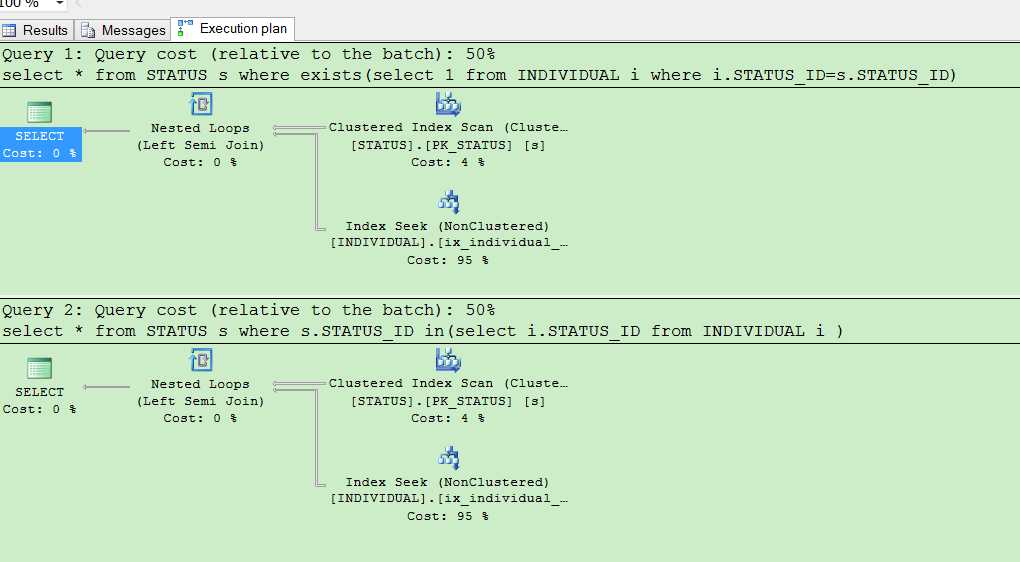
select * from STATUS s where exists(select 1 from INDIVIDUAL i where i.STATUS_ID=s.STATUS_ID)
select * from STATUS s where s.STATUS_ID in(select i.STATUS_ID from INDIVIDUAL i )
查看执行计划后发现,结果貌似是一样的,令人意外,可能大家认为in 比较慢的原因就是 IN先执行子查询 ,但是事实并不是这样的。
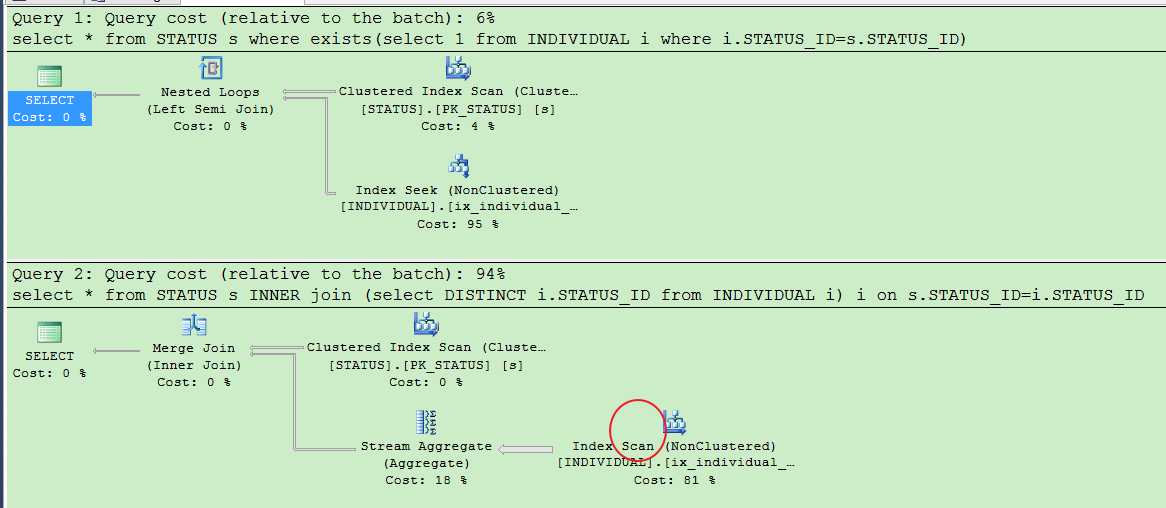
但是如果你使用join,就会发现真的对用户表全盘扫描了.....
关于sql中in 和 exists 的效率问题,in真的效率低吗
标签:一个 比较 www tle logs height img idt 目标
原文地址:https://www.cnblogs.com/xiaoshen666/p/10777597.html