标签:池化 求和 操作 为什么 alt 梳理 出现 问题 直接
这两天回忆起resnet,感觉残差结构还是不怎么理解(可能当时理解了,时间长了忘了吧),重新梳理一下两点,关于resnet结构的思考。
论文的一大贡献就是,证明了即使是深度网络,也可以通过训练达到很好的效果,这跟以往的经验不同,以往由于网络层数的加深,会出现梯度消失的现象。这是因为,在梯度反传的时候,由于层数太深,传递过程又是乘法传递,所以梯度值会越乘越小,梯度消失在所难免。那么怎么才能解决这个问题呢?resnet提供了很好的思路。
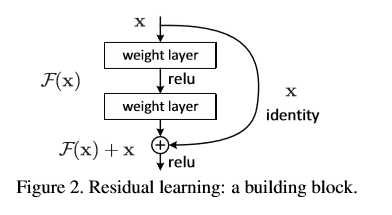
这里一个block的输出变为了常规层的卷积池化加上输入,然后在激活,那么这个结构为什么可以保证深度网络能够收敛呢?
只由这么一个block其实很难看出来,只有在多个block下,才能看出他的优势。看下面的公式。
\[ 对于非残差结构:\y_1 = G(F(x,w_1)) \y_1最为下一层的输入带入有y_2 = G(F(y_1,w_2))\那么我们在对w1求梯度的时候呢,根据链式法则\\frac{dy_2}{dw_1}=\frac{dy_2}{dF}*\frac{dF}{dy_1}*\frac{dy_1}{dF}*\frac{dF}{dw_1}\全是乘法,所以层数过多就很容易越乘越小。\再看看残差结构:\y_1= G(x+F(x,w_1))\y_2 = G(y_1+F(y_1,w_2))\链式求导则得到\frac{dy_2}{dw_1} =\frac{dy_2}{dy_1}*\frac{dy_1}{dF}*\frac{dF}{d_w1} + \frac{dy_2}{dF}*\frac{dF}{dy_1}*\frac{dy_1}{dF}*\frac{dF}{dw_1}\可以看到,残差网络的梯度在原来的基础上加上了当前输入项的梯度\这样梯度的贡献就由两部分组成,一部分是可以直接回传,\另一部分先经过常规操作回传,梯度变为求和项,这样由于在离出层比较近的地方梯度比较大\求和之后可以避免深度乘法对梯度的影响,即尽管后面越乘越小,对总梯度的影响也不大。 \]
从映射角度上来讲,resnet残差结构有助于学习恒等映射,就论文中所说,多层非线性网络是很难逼近恒等映射的,所以网络在学习过程中学习的实际上是残差函数F(x) - x,而当F(x)趋近于0时,那么就可以逼近恒等映射,完成一个skip connection,通俗地讲,就是resnet提供了两种选择,在需要的时候,可以直接跳过一些多余的卷积池化等操作,直接向后传递信息,这就是恒等映射,也可以两路传达信息,传达上一层的原始信息和加工过的信息。
所以我认为,resnet的结构使得网络有了逼近恒等映射的能力,解决了网络传播过程中信息丢失的问题,因此可以表现的这么好。
标签:池化 求和 操作 为什么 alt 梳理 出现 问题 直接
原文地址:https://www.cnblogs.com/aoru45/p/10798027.html