标签:接口 hashset 创建 off htm 方式 支持 默认 原来
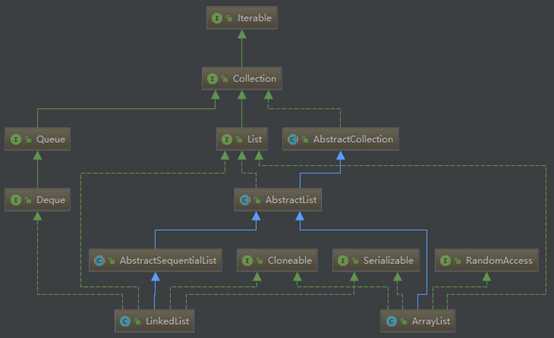
List和Set继承自Collection接口。
Set无序不允许元素重复。HashSet和TreeSet是两个主要的实现类。
List有序且允许元素重复,支持null对象。ArrayList、LinkedList和Vector是三个主要的实现类。
Map也属于集合系统,但和Collection接口没关系。Map是key对value的映射集合,其中key列就是一个集合。key不能重复,但是value可以重复。HashMap、TreeMap和Hashtable是三个主要的实现类。
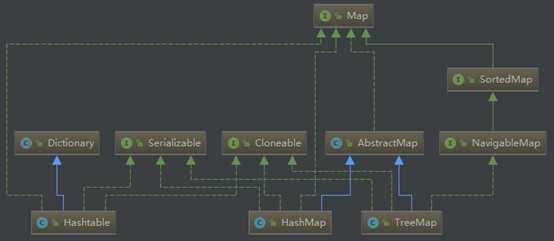
SortedSet和SortedMap接口对元素按指定规则排序,SortedMap是对key列进行排序。
ArrayList和vector区别
ArrayList和Vector都实现了List接口,都是通过数组实现的。
Vector是线程安全的,而ArrayList是非线程安全的。
List第一次创建的时候,会有一个初始大小,随着不断向List中增加元素,当List 认为容量不够的时候就会进行扩容。Vector缺省情况下自动增长原来一倍的数组长度,ArrayList增长原来的50%。
ArrayList和LinkedList区别及使用场景
ArrayList底层是用数组实现的,第一次add操作将数组的长度初始化为10,可以认为ArrayList是一个可改变大小的数组。随着越来越多的元素被添加到ArrayList中,其规模是动态增加的,原理数组大小的1.5倍。
LinkedList底层是通过双向链表实现的,每个节点Node对象包括指向上一个Node对象和指向下一个Node对象,同时LinkedList还实现了Queue接口,所以他还提供了offer(),peek(), poll()等方法。
LinkedList和ArrayList相比,增删的速度较快。但是查询和修改值的速度较慢。同时,
2.使用场景
LinkedList更适合从中间插入或者删除(链表的特性)。
ArrayList更适合检索和在末尾插入或删除(数组的特性)。
HashTable实现原理
(1)是一个线程安全的散列表,存储内容是键值对映射,不支持和null键值对
(2)继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口
(3)线程安全,默认数组长度为11,负载因子为0.75,扩容方式是old*2+1;
具体原理参考文章:http://www.cnblogs.com/skywang12345/p/3310887.html
HashMap和HashTable区别
1).HashTable的方法前面都有synchronized来同步,是线程安全的;HashMap未经同步,是非线程安全的。
2).HashTable不允许null值(key和value都不可以) ;HashMap允许null值(key和value都可以)。
3).HashTable有一个contains(Object value)功能和containsValue(Object value)功能一样。
4).HashTable使用Enumeration进行遍历;HashMap使用Iterator进行遍历。
5).HashTable中hash数组默认大小是11,增加的方式是old*2+1;HashMap中hash数组的默认大小是16,而且一定是2的指数。
6).哈希值的使用不同,HashTable直接使用对象的hashCode; HashMap重新计算hash值,而且用与代替求模。
HashMap实现原理
(1)基于Hash的map接口非同步实现, 无序且允许null的键值对。
(2)初始大小为16,默认负载因子0.75。当一个map填满了75%的bucket时候,将会创建原来HashMap大小的2倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中
(3) put(K key, V value)
根据key的hashCode值重新计算出hash值(高位计算一次散列,防止低位不变高位变化造成冲突),既而得到这个元素在数组中的位置(下标)如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
(4) get(Object key)
计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
(5) 重新调整HashMap大小存在什么问题吗?
重新调整hashMap大小,确实存在竞争,多线程环境,调整大小的过程中,存储在LinkedList中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在LinkedList的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
标签:接口 hashset 创建 off htm 方式 支持 默认 原来
原文地址:https://www.cnblogs.com/zupengliu/p/10804426.html