标签:style blog http color io ar 使用 for sp
★进程,就是运行中的程序。一个可执行程序是一具机器指令及其数据的序列。一个进程是程序运行时的内存空间和设置。
★shell 是一个管理进程和运行程序的程序。Shell主要有三个功能:(1)运行程序(2)管理输入和输出(3)可编程。
(1) grep ls echo都是一些用C编写并被编译成机器语言的程序。Shell将它们载入内存并运行它们。Shell可以看成一个程序的启动器。
(2) Shell不仅仅是运行程序。 使用 < > 和 | 符号可以将输入、输出重定向。
(3) Shell同时也是带有变量和流量控制的编程语言。
★shell程序的运行步骤:
(1)用户键入a.out(程序名)
(2)Shell建立一个新的进程来运行这个程序
(3)Shell将程序从磁盘载入
(4)程序在它的进程中运行直到结束
(5)shell主循环如下:
While(! End_of_input) Get command Execute command Wait for command to finish
(6)事件发生次序:
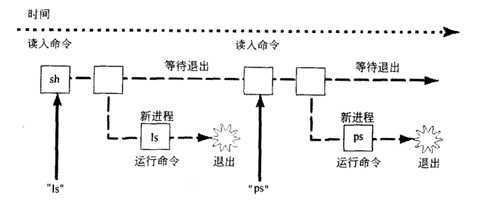
(7)shell主要做了三件事:(1)创建子进程(2)运行进程(3)等待子进程退出
每个进程都有一个非负整型表示的唯一进程ID,ID具有唯一性。大多数UNIX系统实现延迟重用算法,使得赋予新进程的ID不同最近终止进程所使用的ID。ID为0是进程通常是调试进程,常常被称为交换进程,也常用系统进程。进程ID为1的通常是init进程, init通常读与系统有亲的初始化文件(/etc/rc*文件或/etc/inittab文件,以及/etc/init.d中文件),并将系统引导到一个状态(例如多用户)。进程ID为2是页守护进程(pagedaemon)。
父进程ID为0的各进程通常是内核进程,它们作为自举进程的一部分而启动。
下列函数和进程ID有关:
#include <unistd.h> pid_t getpid(void); /* 返回值:调用进程的进程ID */ pid_t getppid(void); /* 返回值:调用进程的父进程ID */ uid_t getuid(void); /* 返回值:调用进程的实际用户ID */ gid_t getgid(void); /* 返回值:调用进程的有效用户ID */ gid_t getegit(void) /* 返回值:调用进程的实际组ID */
★ strlen计算不包含终止null字节的字符串长度,而sizeof则计算包括终止null字节的缓冲区长度。两者之间的另一个差别是,使用strlen需进行一次函数调用,而对sizeof而言,因为缓冲区已经用已知字符串进行了初始化,其长度是固定的,所以sizeof在编译缓冲区长度。
★ 用一个fork把自己复制出来。当fork运行后,将会有两个一模一样的进程,接下来它们将跑自己的逻辑,fork就是“分叉”的意思。进程调用fork,内核做了几件事:
(1)分配新的内存和内核数据结构
(2)复制原来的进程到新的进程
(3)向运行进程添加新的进程
(4)将控制返回给两个进程。
#include <stdio.h> main() { int ret_from_fork, mypid; mypid = getpid(); /* who am i? */ printf("Before: my pid is %d\n", mypid); /* tell the world */ ret_from_fork = fork(); sleep(1); printf("After: my pid is %d, fork() said %d\n",getpid(), ret_from_fork); }
结果:
Before: my pid is 22959
After: my pid is 22959, fork() said 22960
After: my pid is 22960, fork() said 0
★ 从fork的返回值可以判断出父子进程,fork返回0的是是子进程,fork返回大于0的是父进程,而这个返回值是子进程的ID。另外,返回-1说明fork出错。
★ fork函数被调用一次,但返回两次。两次返回的唯一区别是子进程的返回值是0,而父进程的返回值则是新子进程的进程ID。将子进程ID返回给父进程的理由是:因为一个进程的子进程可以有多个,并且没有一个函数使一个进程可以获得其所有子进程的进程ID。fork使子进程得到返回值0的理由是:一个进程只会有一个父进程,所以子进程总是可以调用getppid以获得父进程的进程ID(进程ID 0总是由内核交换进程使用,所以一个子进程的进程ID不可能为0)。
★ 子进程所拥有的父进程的副本,如:数据空间、堆、和栈的副本。注意,这是子进程所拥有的副本。父、子进程并不共享这些存储空间的部分。父子进程共享正文段。
★ 运行一个进程用exec函数族。exec系统调用从当前进程中把当前的程序机器指令清除,然后在空的进程中载入调用时指定的程序代码,最后运行这个新的程序。exec函数族的函数执行成功后不会返回,因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代,只留下进程 ID等一些表面上的信息仍保持原样。在Linux中,并不存在一个exec()的函数形式,exec指的是一组函数,一共有6个,分别是:
int execl(const char *path, const char *arg, ...); int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg, ..., char *const envp[]); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execve(const char *path, char *const argv[], char *const envp[]);
(1) 这6个函数可以发现,前3个函数都是以execl开头的,后3个都是以execv开头的,它们的区别在于,execv开头的函数是 以"char*argv[]"这样的形式传递命令行参数,而execl开头的函数采用了我们更容易习惯的方式,把参数一个一个列出来,然后以一个NULL 表示结束。这里的NULL的作用和argv数组里的NULL作用是一样的。
(2) 在全部6个函数中,只有execle和execve使用了char*envp[]传递环境变量,其它的4个函数都没有这个参数,这并不意味着它 们不传递环境变量,这4个函数将把默认的环境变量不做任何修改地传给被执行的应用程序。而execle和execve会用指定的环境变量去替代默认的那 些。
(3)还有2个以p结尾的函数execlp和execvp,咋看起来,它们和execl与execv的差别很小,事实也确是如此,除execlp和 execvp之外的4个函数都要求,它们的第1个参数path必须是一个完整的路径,如"/bin/ls";而execlp和execvp的第1个参数 file可以简单到仅仅是一个文件名,如"ls",这两个函数可以自动到环境变量PATH制定的目录里去寻找。
★ main()函数的形参
程序入口函数的main其实有三个参数,形式如下:
int main(int argc, char *argv[], char *envp[])
参数argc指出了运行该程序时命令行参数的个数,
数组argv存放了所有的命令行参数,
数组envp存放了所有的环境变量。
int main(int argc, char *argv[], char *envp[]) { printf("\n### ARGC ###\n%d\n", argc); printf("\n### ARGV ###\n"); while(*argv) printf("%s\n", *(argv++)); printf("\n### ENVP ###\n"); while(*envp) printf("%s\n", *(envp++)); return 0; }
★ 可调用wait等待子进程的退出。pid = wait(&status);
系统调用wait做了两件事,(1)wait暂停调用它的进程直到子进程结束(2)wait取得子进程结束时传给exit的值。wait的返回值是子进程的ID。
时间轴如图:
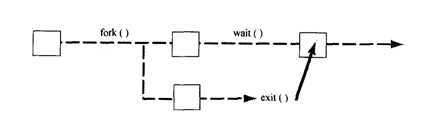
★ wait的目的之一是通知父进程子进程结束运行了,第二个目的是告诉父进程子进程是如何结束的。
一个进程结束的三种方式:
(1)顺利完成任务。按Unix惯例,成功的程序调用exit(0)或者从main函数return 0。
(2)进程失败。按Unix惯例,遇到问题要退出调用exit()时传它一个非零的值。
(3)被信号杀死。信号可能来源于键盘、间隔计时器,内核或其他进程。通信的情况下,一个既没有被忽略又没有被捕获信号会杀死进程的。
★ 父进程是通过wait的参数知道子进程是如何退出的。父进程调用wait时传一个整形变量地址给它,内核将子进程的退出保存在这个变量中,如果子进程调用exit退出,那么内核把exit的返回值存放到时穿上整数变量中。这个整数由3部分组成(8个bit是记录退出值,7个bit是记录信号序号,另一个bit用来指明发生错误并产生了内核映像(core dump))。
★ exit()和_exit()的差异
a) exit和_exit函数都是用来终止进程的。
b) 当程序执行到exit或_exit时,系统无条件的停止剩下所有操作,清除包括PCB在内的各种数据结构,并终止本进程的运行。
c) exit在头文件stdlib.h中声明,而_exit()声明在头文件unistd.h中声明。exit中的参数exit_code为0代表进程正常终止,若为其他值表示程序执行过程中有错误发生。
d) _exit()执行后立即返回给内核,而exit()要先执行一些清除操作,然后将控制权交给内核。
e) 调用_exit函数时,其会关闭进程所有的文件描述符,清理内存以及其他一些内核清理函数,但不会刷新流(stdin, stdout, stderr ...). exit函数是在_exit函数之上的一个封装,其会调用_exit,并在调用之前先刷新流。
f) exit()函数与_exit()函数最大区别就在于exit()函数在调用exit系统之前要检查文件的打开情况,把文
件缓冲区的内容写回文件。
由于Linux的标准函数库中,有一种被称作“缓冲I/O”的操作,其特征就是对应每一个打开的文件,在内存中都有一片缓冲区。每次读文件时,会连续的读出若干条记录,这样在下次读文件时就可以直接从内存的缓冲区读取;同样,每次写文件的时候也仅仅是写入内存的缓冲区,等满足了一定的条件(如达到了一定数量或遇到特定字符等),再将缓冲区中的内容一次性写入文件。这种技术大大增加了文件读写的速度,但也给编程代来了一点儿麻烦。比如有一些数据,认为已经写入了文件,实际上因为没有满足特定的条件,它们还只是保存在缓冲区内,这时用_exit()函数直接将进程关闭,缓冲区的数据就会丢失。因此,要想保证数据的完整性,就一定要使用exit()函数。
★ 父子进程终止的先后顺序
a) 父进程先于子进程终止:
此种情况就是我们前面所用的孤儿进程。当父进程先退出时,系统会让init进程接管子进程 。
b) 子进程先于父进程终止,而父进程又没有调用wait函数
此种情况子进程进入僵死状态,并且会一直保持下去直到系统重启。子进程处于僵死状态时,内核只保存
进程的一些必要信息以备父进程所需。此时子进程始终占有着资源,同时也减少了系统可以创建的最大进
程数。
★ 僵死状态
一个已经终止、但是其父进程尚未对其进行善后处理(获取终止子进程的有关信息,释放它仍占有的资源)的进程被称为僵死进程(zombie)。ps命令将僵死进程的状态打印为Z
子进程先于父进程终止,而父进程调用了wait函数此时父进程会等待子进程结束。
★ ps命令列出来的线程, 如果被"[]"括起来了, 这就是内核线程。
★ 子进程和父进程共享的数据:所有 read-only 的东西都不用复制, 父子进程共享, 包括:正文段和字符串常量。
★ 子进程不会从父进程继承:进程id, 各种锁(内存锁,文件锁), 定时器, 未决信号。
标签:style blog http color io ar 使用 for sp
原文地址:http://www.cnblogs.com/fangshenghui/p/4039768.html