标签:string 情况 com spl pac eve 方法 flume-ng sources
1.下载Flume源码并导入Idea开发工具
1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压
2)通过idea导入flume源码
打开idea开发工具,选择File——》Open
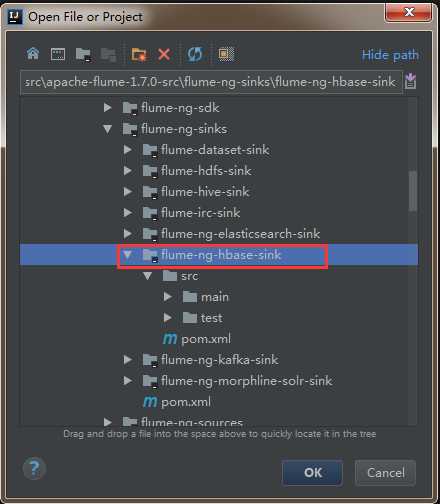
然后找到flume源码解压文件,选中flume-ng-hbase-sink,点击ok加载相应模块的源码。
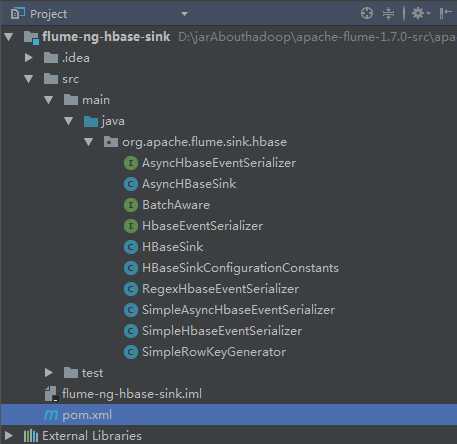
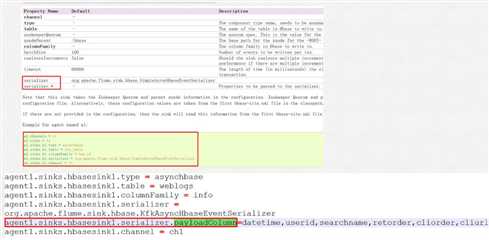
2.官方flume与hbase集成的参数介绍
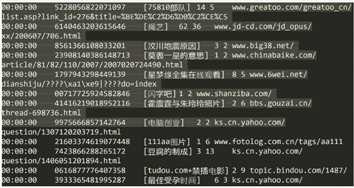
3.下载日志数据并分析
到搜狗实验室下载用户查询日志
1)介绍
搜索引擎查询日志库设计为包括约1个月(2008年6月)Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。为进行中文搜索引擎用户行为分析的研究者提供基准研究语料
2)格式说明
数据格式为:访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL
其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID
4.flume agent-3聚合节点与HBase集成的配置
vi flume-conf.properties
agent1.sources = r1
agent1.channels = kafkaC hbaseC
agent1.sinks = kafkaSink hbaseSink
agent1.sources.r1.type = avro
agent1.sources.r1.channels = hbaseC
agent1.sources.r1.bind = bigdata-pro01.kfk.com
agent1.sources.r1.port = 5555
agent1.sources.r1.threads = 5
agent1.channels.hbaseC.type = memory
agent1.channels.hbaseC.capacity = 100000
agent1.channels.hbaseC.transactionCapacity = 100000
agent1.channels.hbaseC.keep-alive = 20
agent1.sinks.hbaseSink.type = asynchbase
agent1.sinks.hbaseSink.table = weblogs
agent1.sinks.hbaseSink.columnFamily = info
agent1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
agent1.sinks.hbaseSink.channel = hbaseC
agent1.sinks.hbaseSink.serializer.payloadColumn = datatime,userid,searchname,retorder,cliorder,cliurl
5.对日志数据进行格式处理
1)将文件中的tab更换成逗号
cat weblog.log|tr "\t" "," > weblog2.log
2)将文件中的空格更换成逗号
cat weblog2.log|tr " " "," > weblog3.log
6.自定义SinkHBase程序设计与开发
1)模仿SimpleAsyncHbaseEventSerializer自定义KfkAsyncHbaseEventSerializer实现类,修改一下代码即可。
@Override
public List getActions() {
List actions = new ArrayList();
if (payloadColumn != null) {
byte[] rowKey;
try {
/*---------------------------代码修改开始---------------------------------*/
//解析列字段
String[] columns = new String(this.payloadColumn).split(",");
//解析flume采集过来的每行的值
String[] values = new String(this.payload).split(",");
for(int i=0;i < columns.length;i++){
byte[] colColumn = columns[i].getBytes();
byte[] colValue = values[i].getBytes(Charsets.UTF_8);
//数据校验:字段和值是否对应
if(colColumn.length != colValue.length) break;
//时间
String datetime = values[0].toString();
//用户id
String userid = values[1].toString();
//根据业务自定义Rowkey
rowKey = SimpleRowKeyGenerator.getKfkRowKey(userid,datetime);
//插入数据
PutRequest putRequest = new PutRequest(table, rowKey, cf,
colColumn, colValue);
actions.add(putRequest);
/*---------------------------代码修改结束---------------------------------*/
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}
2)在SimpleRowKeyGenerator类中,根据具体业务自定义Rowkey生成方法
/**
* 自定义Rowkey
* @param userid
* @param datetime
* @return
* @throws UnsupportedEncodingException
*/
public static byte[] getKfkRowKey(String userid,String datetime)throws UnsupportedEncodingException {
return (userid + datetime + String.valueOf(System.currentTimeMillis())).getBytes("UTF8");
}
7.自定义编译程序打jar包
1)在idea工具中,选择File——》ProjectStructrue
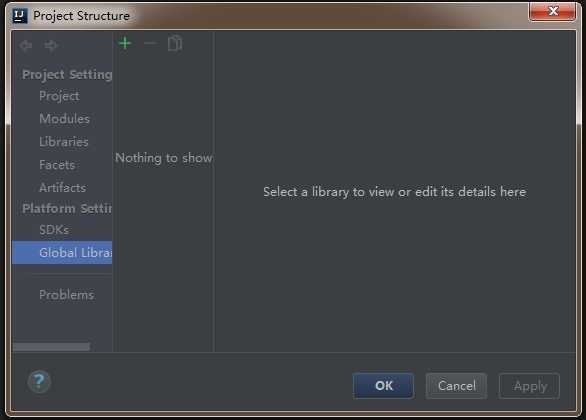
2)左侧选中Artifacts,然后点击右侧的+号,最后选择JAR——》From modules with dependencies
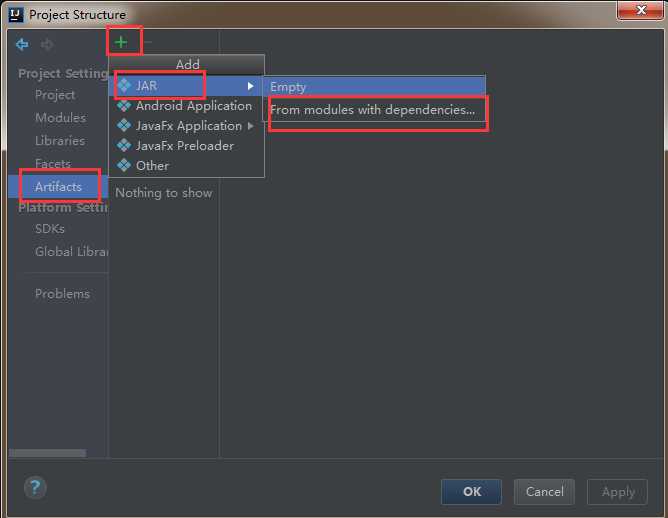
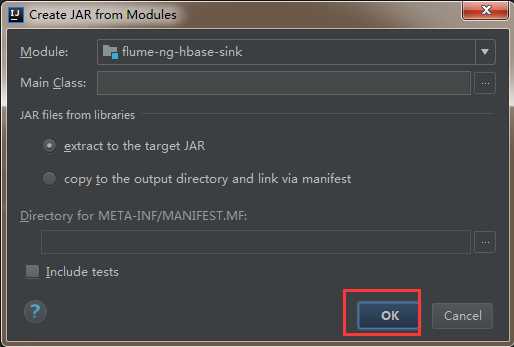
3)然后直接点击ok
4)删除其他依赖包,只把flume-ng-hbase-sink打成jar包就可以了。
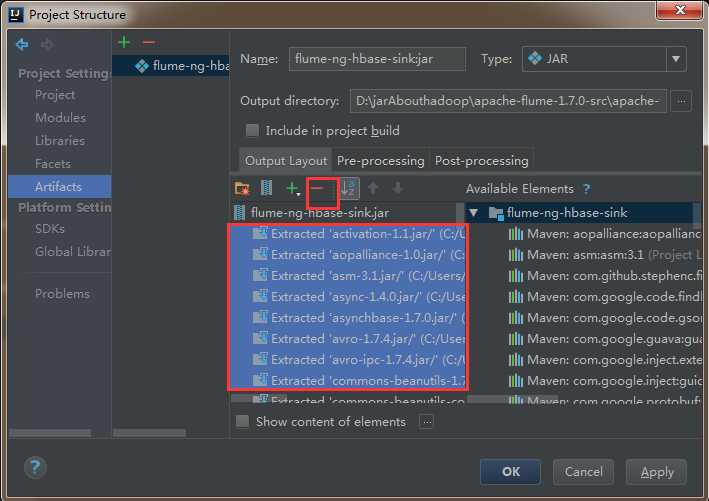
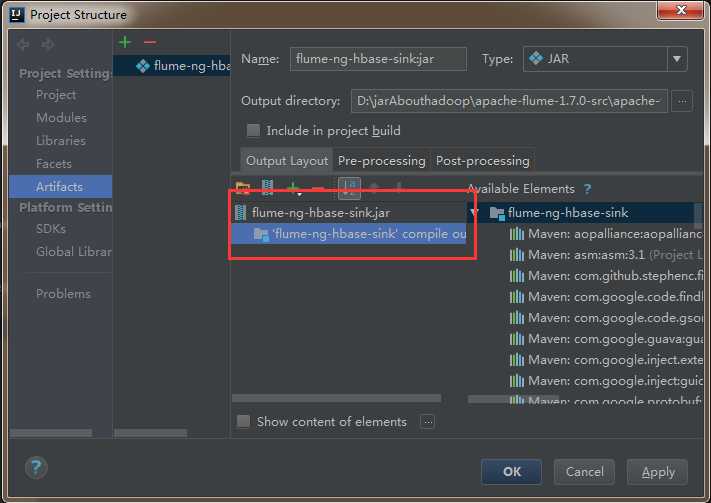
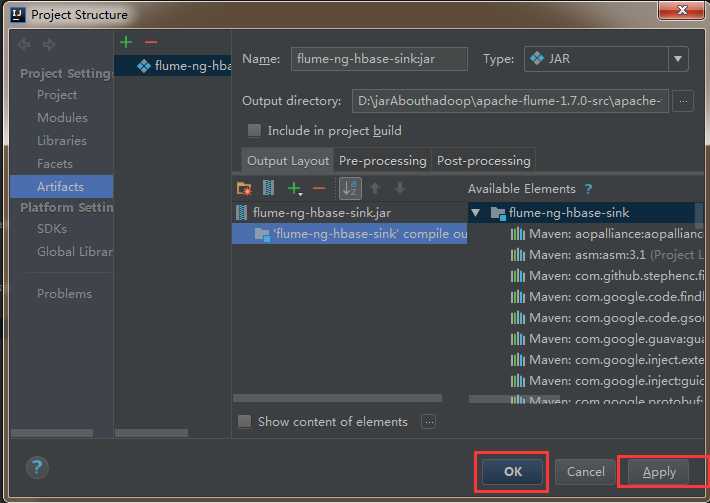
5)然后依次点击apply,ok
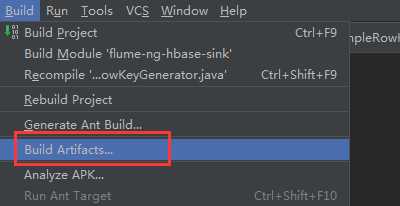
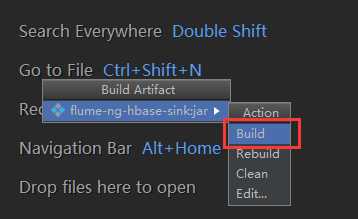
6)点击build进行编译,会自动打成jar包
7)到项目的apache-flume-1.7.0-src\flume-ng-sinks\flume-ng-hbase-sink\classes\artifacts\flume_ng_hbase_sink_jar目录下找到刚刚打的jar包
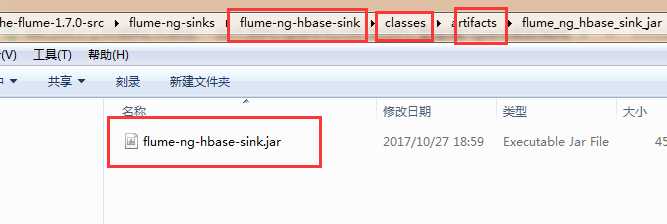
8)将打包名字替换为flume自带的包名flume-ng-hbase-sink-1.7.0.jar ,然后上传至flume/lib目录下,覆盖原有的jar包即可。
8.flume聚合节点与Kafka集成的配置
vi flume-conf.properties
agent1.sources = r1
agent1.channels = kafkaC hbaseC
agent1.sinks = kafkaSink hbaseSink
agent1.sources.r1.type = avro
agent1.sources.r1.channels = hbaseC kafkaC
agent1.sources.r1.bind = bigdata-pro01.kfk.com
agent1.sources.r1.port = 5555
agent1.sources.r1.threads = 5
agent1.channels.hbaseC.type = memory
agent1.channels.hbaseC.capacity = 100000
agent1.channels.hbaseC.transactionCapacity = 100000
agent1.channels.hbaseC.keep-alive = 20
agent1.sinks.hbaseSink.type = asynchbase
agent1.sinks.hbaseSink.table = weblogs
agent1.sinks.hbaseSink.columnFamily = info
agent1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
agent1.sinks.hbaseSink.channel = hbaseC
agent1.sinks.hbaseSink.serializer.payloadColumn = datatime,userid,searchname,retorder,cliorder,cliurl
#*****************flume+Kafka***********************
agent1.channels.kafkaC.type = memory
agent1.channels.kafkaC.capacity = 100000
agent1.channels.kafkaC.transactionCapacity = 100000
agent1.channels.kafkaC.keep-alive = 20
agent1.sinks.kafkaSink.channel = kafkaC
agent1.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafkaSink.brokerList = bigdata-pro01.kfk.com:9092,bigdata-pro02.kfk.com:9092,bigdata-pro03.kfk.com:9092
agent1.sinks.kafkaSink.topic = test
agent1.sinks.kafkaSink.zookeeperConnect = bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181
agent1.sinks.kafkaSink.requiredAcks = 1
agent1.sinks.kafkaSink.batchSize = 1
agent1.sinks.kafkaSink.serializer.class = kafka.serializer.StringEncoder
新闻网大数据实时分析可视化系统项目——9、Flume+HBase+Kafka集成与开发
标签:string 情况 com spl pac eve 方法 flume-ng sources
原文地址:https://www.cnblogs.com/ratels/p/10844847.html