标签:pass 必须 stp legend decode page last on() marker
在爬虫下载过程中,执行一段时间后都会异常终止,下次必须kill掉进程重新运行 ,看能否优化并减少手动操作
收集了nohup.out文件,发现主要错误是的数组下标越界,推测可能的问题为:
1)网络不稳定,http请求不通。
2)网络请求成功,但是html表单解析失败。
3)登录的cookie过期
在所有有网络请求的地方,都加上了返回码是不是200的判断,然后html表单解析的地方加上数组长度判断,异常处理等
import socket
import time
import os
from datetime import datetime
import re
import yaml
import requests
from bs4 import BeautifulSoup
# 设置超时时间为10s
socket.setdefaulttimeout(10)
s = requests.Session()
# 登录
def login():
url = host_url + "j_spring_security_check"
data = {
"username": bzh_host_usr,
"password": bzh_host_pwd
}
try:
response = s.post(url, data=data, headers=headers)
if response.status_code == 200:
cookie = response.cookies.get_dict()
print("login success")
return cookie
except Exception as e:
print("login fail:", e)
# 页码
def get_pages():
try:
response = s.get(noticeListUrl, data=paramsNotice, headers=headers, cookies=cookie)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
pageCount = int(soup.find('span', id='PP_countPage').get_text())
pageCount = pageCount if pageCount > 1 else 1
return pageCount
except Exception as e:
print("get page_count fail:", e)
# 文档ids
def get_ids(pageCount):
ids = []
for p in range(int(pageCount)):
paramsNotice['pageIndex'] = p + 1
try:
response = s.get(noticeListUrl, data=paramsNotice, headers=headers, cookies=cookie)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
trs = soup.find("table", class_='ObjectListPage').tbody.find_all("tr")
regex = re.compile(r"noticeId=(\d+)")
for tr in trs:
if (tr.text.find("标准化文档更新") > 0):
id = regex.findall(str(tr))[0]
ids.append(id)
print("bzh id:" + id)
last_update = tr.find_all("td")[1].get_text().strip()
date_format = time.strftime("%Y%m%d", time.strptime(last_update, "%Y-%m-%d %H:%M:%S"))
file_name = "标准化文档-" + date_format + ".rar"
crawlFile(id, file_name)
except Exception as e:
print("get ids fail:", e)
return ids
# 下载
def crawlFile(id, file_name):
down_url = noticeURL + id
metaFile = "./bzh/" + file_name
response = s.get(down_url, headers=headers, cookies=cookie)
content = response.headers.get('Content-Disposition')
filename = content[content.find('=') + 1:]
filename = filename.encode('iso-8859-1').decode('GBK')
print("remote:" + filename)
try:
f = open(metaFile, 'wb')
f.write(response.content)
f.close()
print(file_name + " first download success")
exit(0)
except Exception as e:
print(file_name + " download fail", e)
if __name__ == "__main__":
yaml_path = os.path.join('../', 'config.yaml')
with open(yaml_path, 'r') as f:
config = yaml.load(f, Loader=yaml.FullLoader)
host_url = config['host_url']
noticeListUrl = host_url + config['noticeListUrl']
noticeDetailUrl = host_url + config['noticeDetailUrl']
noticeURL = host_url + config['noticeURL']
bzh_host_usr = config['bzh_host_usr']
bzh_host_pwd = config['bzh_host_pwd']
table_meta_bg_date = config['table_meta_bg_date']
# header头信息
headers = {
"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
"Referer": host_url + "login.jsp"
}
paramsNotice = {
"queryStartTime": table_meta_bg_date
}
task_begin = datetime.now()
print("Crawler begin time:" + str(task_begin))
cookie = login()
if cookie == "":
print("cookie is null")
exit(0)
pageCount = get_pages()
pageCount = 2
if pageCount < 1:
print("page < 1")
exit(0)
ids = get_ids(pageCount)
task_end = datetime.now()
print("Crawler end time:" + str(task_end))
优化后的爬虫运行正常,之前的异常已被捕获,输出在error日志里。
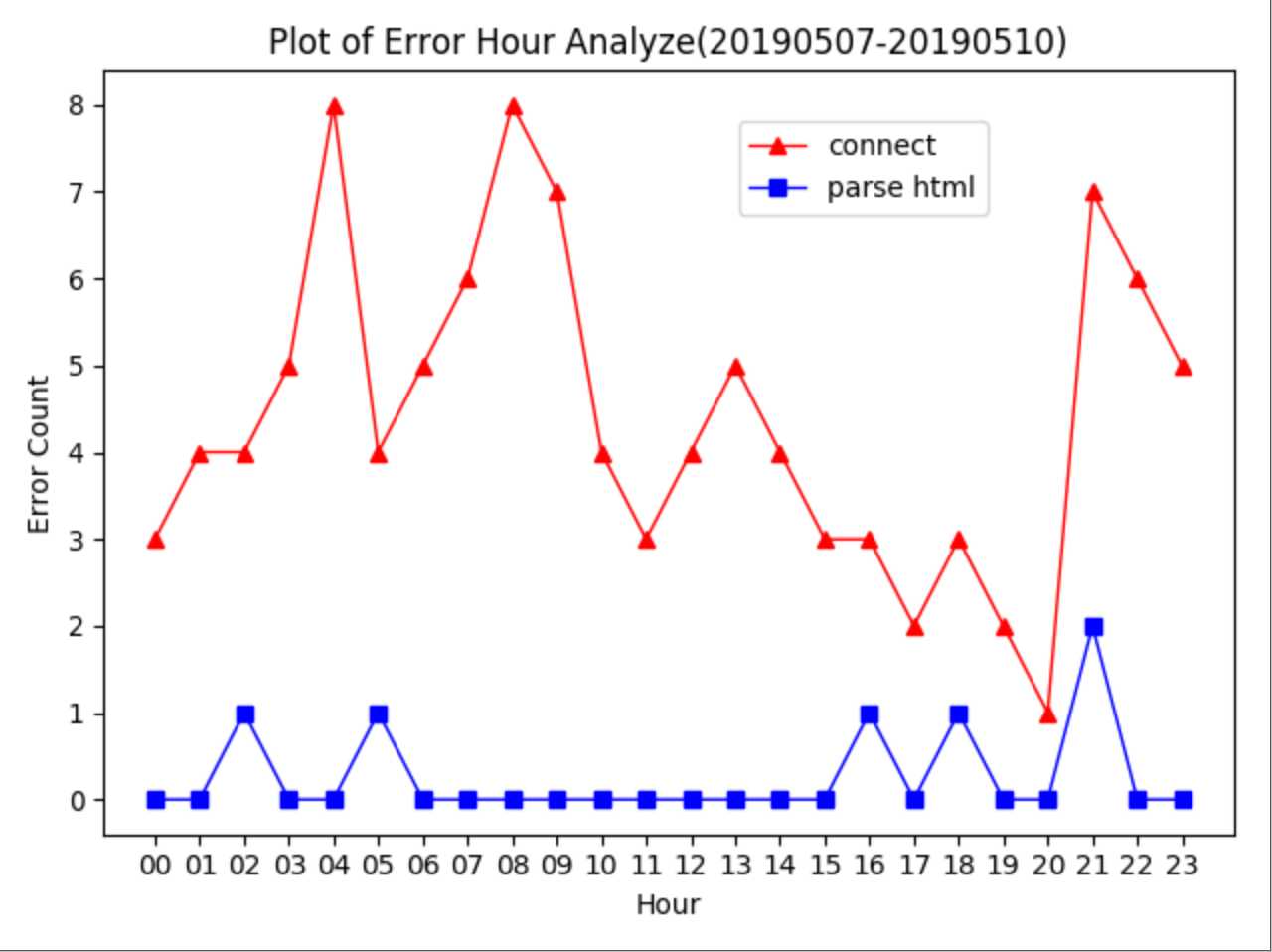
更新过的代码在线上环境跑了4天,收集了4天的错误日志,想从时间点上观察,看能否继续优化。
import os
import matplotlib.pyplot as plt
if __name__ == "__main__":
print("analyze error of bzh crawler")
error_con = {}
error_html = {}
for i in range(0, 24):
key = "0" + str(i) if i < 10 else str(i)
error_con[key] = 0
error_html[key] = 0
error_file = os.popen('ls ' + "./input").read().split()
for i in range(0, len(error_file)):
input = open('./input/' + error_file[i], 'r')
for line in input:
lines = line.split()
error_msg = line[line.find("-", 50) + 2:]
hour = lines[2][0:2]
if error_msg.find("get html failed") > -1:
error_con[hour] += 1
elif error_msg.find("parse detail html failed") > -1:
error_html[hour] += 1 / 2
# 折线图
plt.title("Plot of Error Hour Analyze(20190507-20190510)")
plt.xlabel("Hour")
plt.ylabel("Error Count")
plt.plot(error_con.keys(), error_con.values(), color="r", linestyle="-", marker="^", linewidth=1, label="connect")
plt.plot(error_html.keys(), error_html.values(), color="b", linestyle="-", marker="s", linewidth=1,
label="parse html")
plt.legend(loc='upper left', bbox_to_anchor=(0.55, 0.95))
plt.show()
标签:pass 必须 stp legend decode page last on() marker
原文地址:https://www.cnblogs.com/wanli002/p/10850384.html