标签:bsp 集群部署 orm 数据 htm beautiful tor 计算 数据处理
强烈建议:请在电脑的陪同下,阅读本文。本文以实战为主,阅读过程如稍有不适,还望多加练习。
本文的实战内容有:
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。比如:https://www.baidu.com/,它就是一个URL。
在讲解爬虫内容之前,我们需要先学习一项写爬虫的必备技能:审查元素(如果已掌握,可跳过此部分内容)。
在浏览器的地址栏输入URL地址,在网页处右键单击,找到检查。(不同浏览器的叫法不同,Chrome浏览器叫做检查,Firefox浏览器叫做查看元素,但是功能都是相同的)
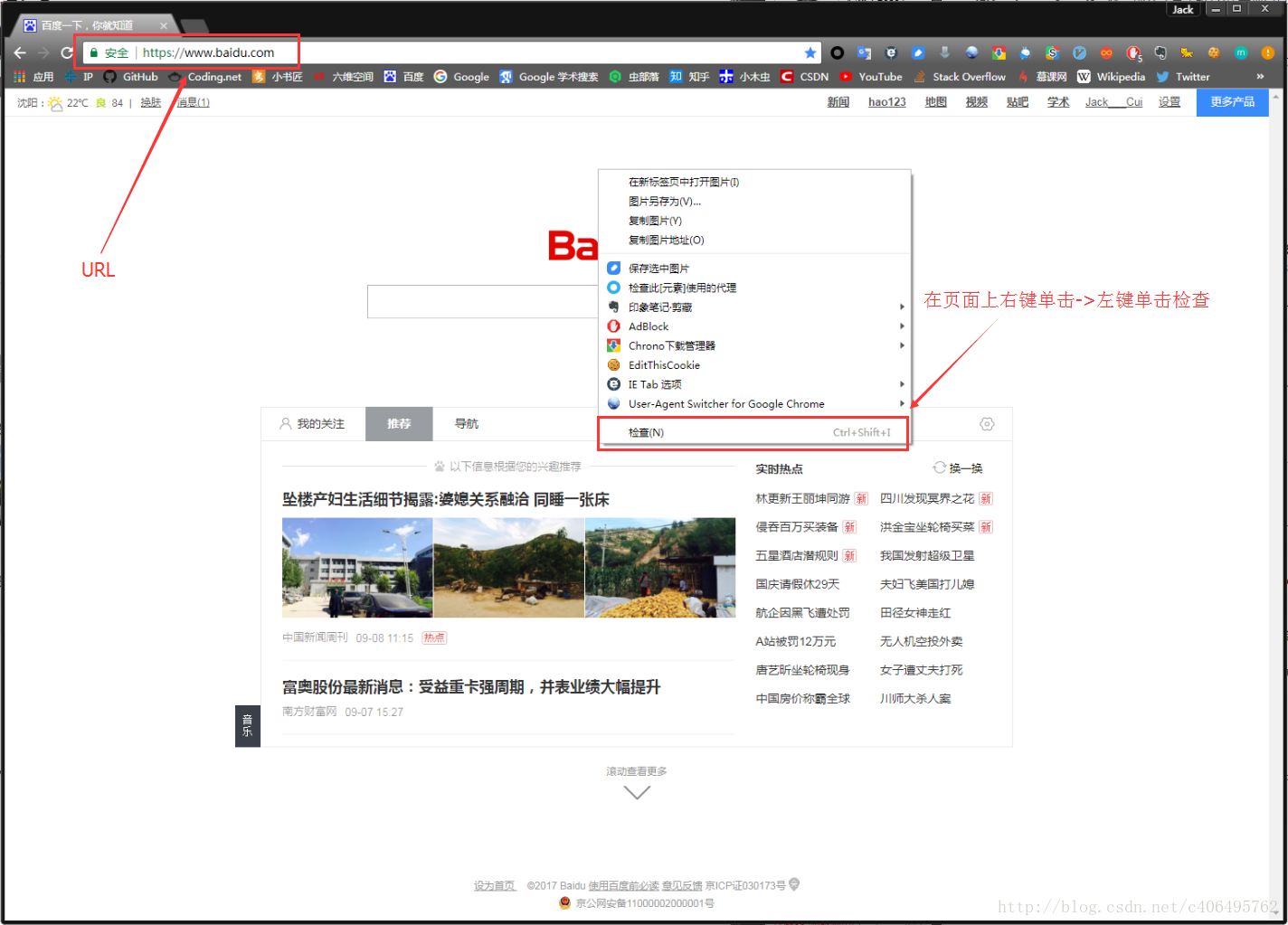
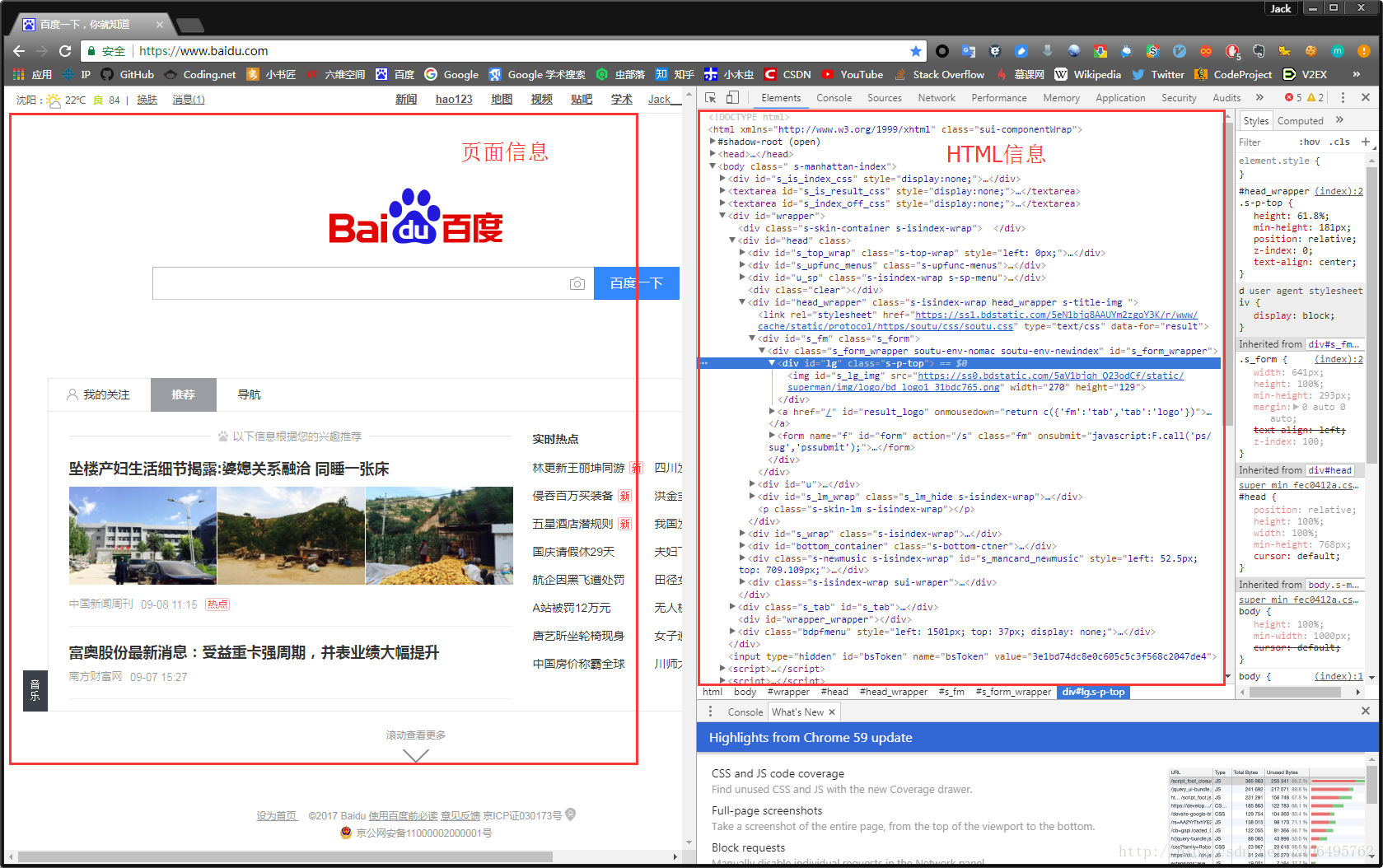
我们可以看到,右侧出现了一大推代码,这些代码就叫做HTML。什么是HTML?举个容易理解的例子:我们的基因决定了我们的原始容貌,服务器返回的HTML决定了网站的原始容貌。
为啥说是原始容貌呢?因为人可以整容啊!扎心了,有木有?那网站也可以”整容”吗?可以!请看下图:大数据精英课程,云计算,数据分析,数据仓库,数据爬虫,项目实战,用户画像,日志分析,全文检索,项目监控,性能调优,系统架构,电商数据分析,电商行为日志分析,电商实时分析系统,分布式计算平台,分布式集群部署,实时流计算,全端数据统计分析系统,堵车预测系统实战,共享单车实战,电信级海量数据处理,分布式消息系统,日志传输实战,大型电商项目与数据应用实战,Hadoop,Flink,Spark,Kafka,Storm,Docker,Kubernetes(K8s),ElaticStack,HBase,SparkSQL,Hive,Flume,ETL,DMP等高端视频课程......
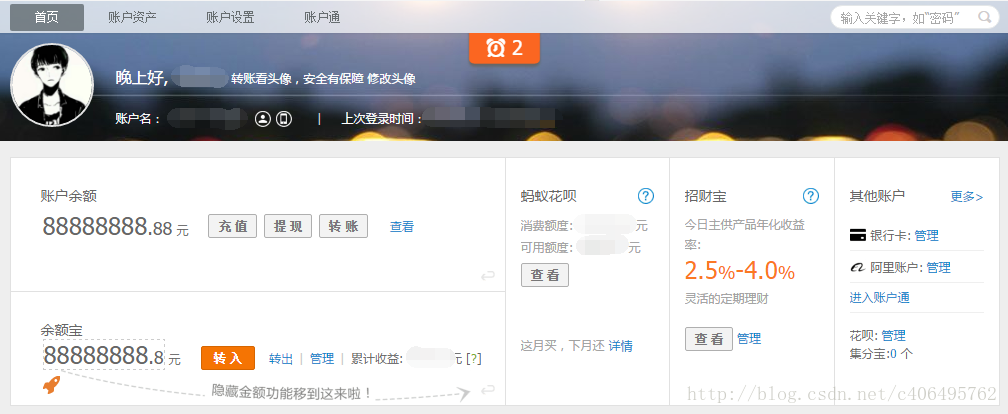
我能有这么多钱吗?显然不可能。我是怎么给网站”整容”的呢?就是通过修改服务器返回的HTML信息。我们每个人都是”整容大师”,可以修改页面信息。我们在页面的哪个位置点击审查元素,浏览器就会为我们定位到相应的HTML位置,进而就可以在本地更改HTML信息。
再举个小例子:我们都知道,使用浏览器”记住密码”的功能,密码会变成一堆小黑点,是不可见的。可以让密码显示出来吗?可以,只需给页面”动个小手术”!以淘宝为例,在输入密码框处右键,点击检查。
python网络爬虫实战-Scrapy,深入理解scrapy框架,解决数据抓取过程
标签:bsp 集群部署 orm 数据 htm beautiful tor 计算 数据处理
原文地址:https://www.cnblogs.com/cjmn1166/p/10851930.html