标签:java语言 java mda 汇总 分布式数据库 utc 总结 rds 完整
1.安装MySql
2.windows 与 虚拟机互传文件
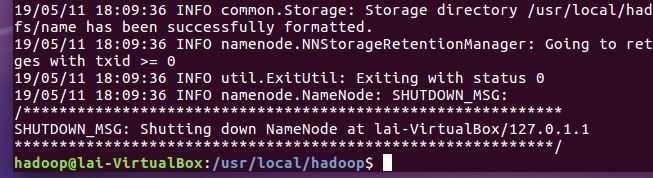
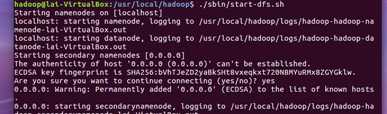
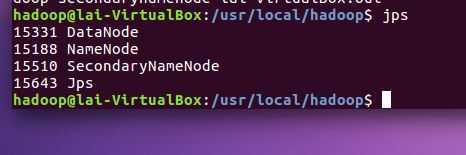
3.安装Hadoop
还不能从windows复制文件的,可在虚拟机里用浏览器下载安装文件,课件:
提取文件:hadoop-2.7.1.tar.gz
链接: https://pan.baidu.com/s/1HIVd9JCZstWm0k7sAbXQCg
提取码: 2thj

4. 简述Hadoop平台的起源、发展历史与应用现状。
列举发展过程中重要的事件、主要版本、主要厂商;
国内外Hadoop应用的典型案例。
Hadoop不是指具体一个框架或者组件,它是Apache软件基金会下用Java语言开发的一个开源分布式计算平台。实现在大量计算机组成的集群中对海量数据进行分布式计算。适合大数据的分布式存储和计算平台。
Hadoop1.x中包括两个核心组件:MapReduce和Hadoop Distributed File System(HDFS)
其中HDFS负责将海量数据进行分布式存储,而MapReduce负责提供对数据的计算结果的汇总
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop的成长过程
Lucene–>Nutch—>Hadoop
总结起来,Hadoop起源于Google的三大论文
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
演变关系
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
2009年9月— 亚联BI团队开始跟踪研究Hadoop
2009年12月—亚联提出橘云战略,开始研究Hadoop
2010年5月— Avro脱离Hadoop项目,成为Apache顶级项目。
2010年5月— HBase脱离Hadoop项目,成为Apache顶级项目。
2010年5月— IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
2010年9月— Hive( Facebook) 脱离Hadoop,成为Apache顶级项目。
2010年9月— Pig脱离Hadoop,成为Apache顶级项目。
2011年1月— ZooKeeper 脱离Hadoop,成为Apache顶级项目。
2011年3月— Apache Hadoop获得Media Guardian Innovation Awards 。
标签:java语言 java mda 汇总 分布式数据库 utc 总结 rds 完整
原文地址:https://www.cnblogs.com/zzzj/p/10852763.html