标签:update 之间 清除 alt 这一 插入 tin from result
| 引擎 | 事务 | 锁 | 主键 | 索引 | 外键 | 数据结构 | 适用场景 |
| InnoDB | 支持 | 行锁、表锁 | 必须有主键,没有设置会自动创建 | 主键索引和数据在一起,其他索引执行主角索引 | 支持 | 2个文件,一个是表结构,一个是索引和数据 | 事务、增删改频繁 |
| MyISAM | 不支持 | 只支持表锁 | 可以没有主键 | 索引存放数据的地址 | 不支持 | 3个文件,一个是表结构,一个是索引文件,一个是数据 | 只适合查询 |
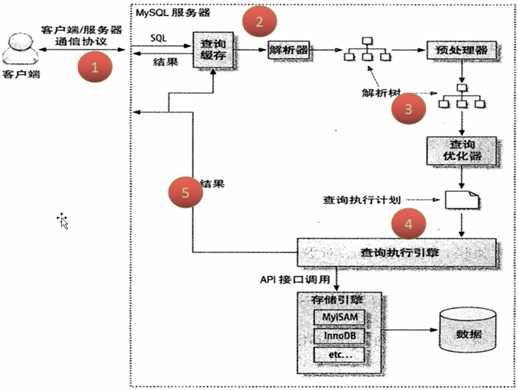
1.客户端和mysql创建连接,是半双工通信模式,即同一时间客户端和mysql只有一方在发送数据
2.查询缓存
3.查询优化,包含sql解析,sql预处理(检验sql的合法性),查询优化器进行sql优化
4.调用存储引擎的API执行sql语句
5.返回结果给客户端,如果设置了缓存则存放缓存
mysql可以设置查询缓存,可用性不高,一是因为缓存一般设置的内存不大,难以存放大数据量的缓存;二是因为缓存实际相当于map形式,key是sql语句,value是结果,只有当sql语句完全一样才能命中缓存,多一个空格都不行;三三因为一旦数据库执行update、insert或delete操作,缓存都将会被清除。
sleep:线程等待客户端发送数据(等待客户端发送sql语句,最常见的状态)
query:线程正在执行客户端的sql语句
Locked:线程正在等待锁的释放
sorting result:线程正在对结果进行排序
sending data:线程正在给客户端返回数据结果
通过explain语句,可以查询sql语句的执行计划
mysql的事务表示一组sql语句要么全部被执行要么全部不执行
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务的隔离性是为了解决数据库在并发操作时的一些问题,那么再了解事务隔离级别时先分析下事务在并发情况下都有哪些问题?
1.脏读
事务A执行更新操作但是还没有提交或回滚,事务B就查询到了事务A更新过后的数据
2.不可重复读
事务B先执行查询语句,事务A执行更新操作并且提交了,事务B再执行和之前相同的查询语句,发现和第一次查询的结果不一样
3.幻读
当事务B执行了两次相同查询操作之间,事务A执行了插入操作,虽然事物B没有发现不可重复读问题,但是发现多了新的数据
针对这三种问题,mysql提供了四种事务隔离级别来解决这一问题
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 未提交读(read-uncommitted) | 没解决 | 没解决 | 没解决 |
| 已提交读(read-committed) | 解决 | 没解决 | 没解决 |
| 可重读读(repeatable-read) | 解决 | 解决 | 没解决(innodb通过锁机制解决) |
| 串行化(serializable) | 解决 | 解决 | 解决 |
innoDB未提交读:对更新操作的事务添加排他锁,则在提交之前,其他事务无法读取
innoDB已提交读:对查询操作的事物添加共享锁,则在事务完成之前,其他事务无法更新
innoDB可重复读:对范围查询时无数据的间隙中添加gap锁,则数据锁无法插入的,如select * from XX where id > 10,则大于10的空间添加gap锁即可
innoDB串行化:所有sql语句按顺序执行,不存在并发问题,锁的是整个表
| 锁 | 简称 | 级别 | 作用 | 用法 |
| 共享锁 | S锁、读锁 | 行锁 | 当前事务加读锁,其他事务只可读不能修改 | sql语句加
LOCK IN SHARE MODE
|
| 排他锁 | X锁、写锁 | 行锁 | 当前事务加写锁,其他事务不可获取任何锁,包括读锁和写锁 | sql语句加 for update以及update、insert和delete语句自动加X锁 |
| 意向共享锁 | IS锁 | 表锁 | 有任一事务添加共享锁时,数据库自动维护意向共享锁 | 并非真正的锁,而是相当于当前表的锁的状态 |
| 意向排他锁 | IX锁 | 表锁 | 有任一事务添加排他锁时,数据库自动维护意向排他锁 | 并非真正的锁,而是相当于当前表的锁的状态 |
锁的本质是对索引进行加锁,如果锁的数据是按主键锁的,就直接锁住主键索引;如果是非主键索引,那么就通过非主键索引找到主键索引进行加锁;如果没有通过索引加锁,那么就会遍历表的聚集索引(默认的主键索引),也就相当于锁住了整个表
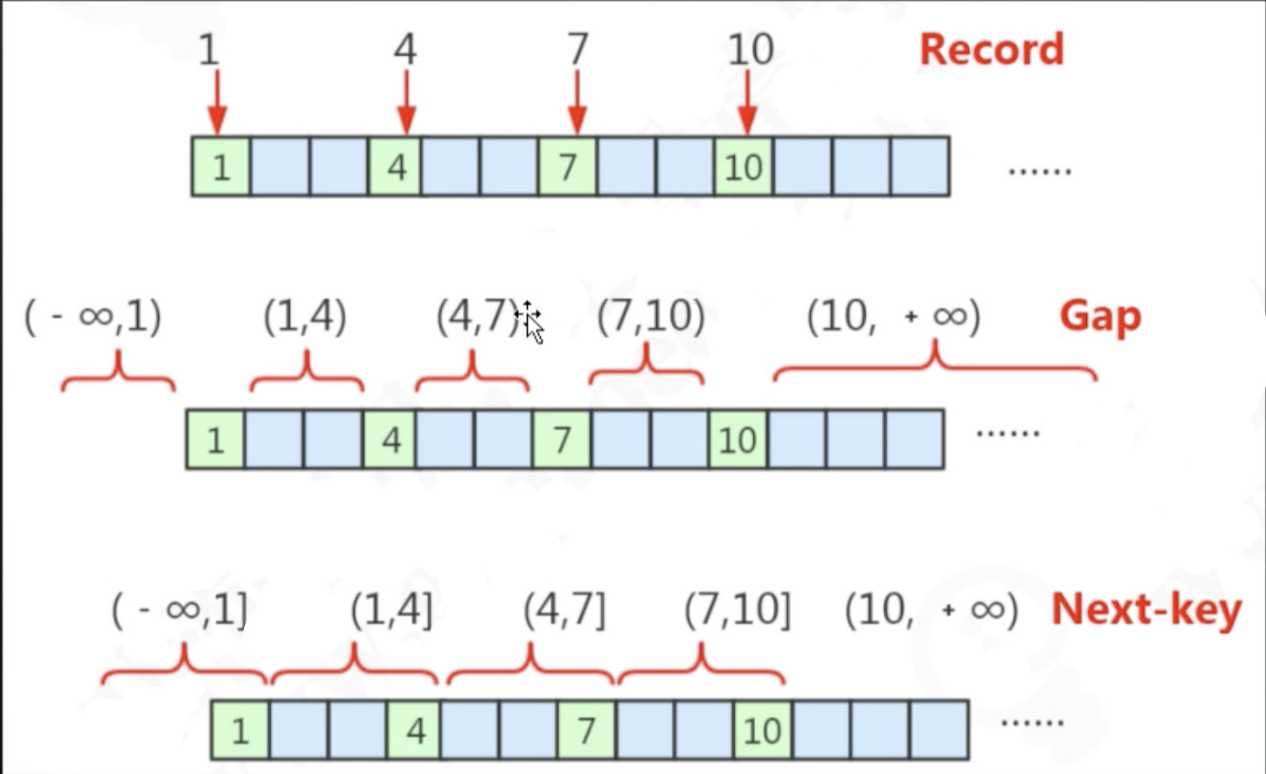
Record Lock:行锁,通过主键索引或唯一索引等值查询,精准匹配之后锁住的数据行
Gap Lock:间隙锁,数据不存在的连续区间)如当id>30时,id=11也会被锁,因为连续的是从10开始的,范围查询或等值查询记录都不存在时使用,相同 间隙锁之间不冲突,退化成Gap Lock
Next-Key Lock:临键锁,相当于Gap+Record的集合,采取左开右闭原则,innodb的默认锁,没有成功就会退化成gap,或者由gap再退化成record
1、from,第一步是找到查询的表
2、on,如果是关联查询,需要用on关联两个表
3、where 找到了需要查询的表,就需要采用where来对数据进行过滤
4、group by,对过滤的数据进行分组(返回的是一个游标而不是一个表,所以可以从这之后使用别名,而where就不可)
5、having 对group by的结果进行过滤
6、select 查询需要返回的列
7、order by对返回对数据进行排序
标签:update 之间 清除 alt 这一 插入 tin from result
原文地址:https://www.cnblogs.com/jackion5/p/10854020.html