标签:dde 遍历 count org 可变长参数 seq 大于 冒号 查询
https://www.anaconda.com/distribution/#download-section
安装完毕后,在开始找到spyder即可。
变量的命名规则,可以用a-z,A-Z,数字,下划线组成,首字母不能是数字或者下划线,变量名不能是python的保留字,大小写的赋值是不一样的。
布尔型(与&、或|、非not)、数值型、字符型

1 x = 1; 2 y = 2; 3 4 x + y 5 x - y 6 x * y 7 x / y 8 9 #取整 10 7 // 4 11 #求余 12 10 % 4 13 14 #乘方 15 2 ** 3 16 17 #一个关于浮点数运算需要注意的地方 18 a = 4.2 19 b = 2.1 20 a + b 21 22 (a + b) == 6.3 23 24 from decimal import Decimal 25 a = Decimal(‘4.2‘) 26 b = Decimal(‘2.1‘) 27 a + b 28 29 print(a + b) 30 31 (a + b) == Decimal(‘6.3‘)
1 x = ‘我是一个字符串‘; 2 y = "我也是一个字符串"; 3 4 5 #字符串str用单引号(‘ ‘)或双引号(" ")括起来 6 7 #使用反斜杠(\)转义特殊字符。 8 s = ‘Yes,he doesn\‘t‘ 9 print(s, type(s), len(s)) 10 11 #如果你不想让反斜杠发生转义, 12 #可以在字符串前面添加一个r,表示原始字符串 13 print(‘C:\some\name‘) 14 15 print(r‘C:\some\name‘) 16 17 #反斜杠可以作为续行符,表示下一行是上一行的延续。 18 #还可以使用"""..."""或者‘‘‘...‘‘‘跨越多行 19 s = "abcd 20 efg" 21 print(s); 22 23 s = """ 24 Hello I am fine! 25 Thinks. 26 """ 27 print(s); 28 29 #字符串可以使用 + 运算符串连接在一起,或者用 * 运算符重复: 30 print(‘str‘+‘ing‘, ‘my‘*3) 31 32 #Python中的字符串有两种索引方式 33 #第一种是从左往右,从0开始依次增加 34 #第二种是从右往左,从-1开始依次减少 35 #注意,没有单独的字符类型,一个字符就是长度为1的字符串 36 word = ‘Python‘ 37 print(word[0], word[5]) 38 print(word[-1], word[-6]) 39 40 #还可以对字符串进行切片,获取一段子串 41 #用冒号分隔两个索引,形式为变量[头下标:尾下标] 42 #截取的范围是前闭后开的,并且两个索引都可以省略 43 word = ‘ilovepython‘ 44 word[1:5] 45 #‘love‘ 46 word[:] 47 #‘ilovepython‘ 48 word[5:] 49 #‘python‘ 50 word[-10:-6] 51 #‘love‘ 52 #Python字符串不能被改变 53 #向一个索引位置赋值,比如word[0] = ‘m‘会导致错误。 54 word[0] = ‘m‘ 55 56 57 #检测开头和结尾 58 filename = ‘spam.txt‘ 59 filename.endswith(‘.txt‘) 60 61 filename.startswith(‘file:‘) 62 63 url = ‘http://www.python.org‘ 64 url.startswith(‘http:‘) 65 66 choices = (‘http:‘, ‘https‘) 67 url = ‘https://www.python.org‘ 68 url.startswith(choices) 69 70 choices = [‘http:‘, ‘https‘] 71 url = ‘https://www.python.org‘ 72 url.startswith(choices) 73 74 75 #查找某个字符串 76 string = "I am KEN" 77 string.find("am") 78 string.find("boy") 79 #忽略大小写的搜索 80 81 import re 82 text = ‘UPPER PYTHON, lower python, Mixed Python‘ 83 re.findall(‘python‘, text, flags=re.IGNORECASE) 84 85 #搜索和替换 86 text = ‘yeah, but no, but yeah, but no, but yeah‘ 87 text.replace(‘yeah‘, ‘yep‘) 88 89 #忽略大小写的替换 90 text = ‘UPPER PYTHON, lower python, Mixed Python‘ 91 re.sub(‘python‘, ‘snake‘, text, flags=re.IGNORECASE) 92 93 #合并拼接字符串 94 parts = [‘Is‘, ‘Chicago‘, ‘Not‘, ‘Chicago?‘] 95 ‘ ‘.join(parts) 96 ‘Is Chicago Not Chicago?‘ 97 ‘,‘.join(parts) 98 ‘Is,Chicago,Not,Chicago?‘ 99 ‘‘.join(parts) 100 ‘IsChicagoNotChicago?‘ 101 102 #接下来几节课中,我们还会有一些常用的字符串使用方法
1 #列表中,可以有不同的数据类型,以及相同的值 2 a = [‘him‘, 25, 100, ‘her‘, 100, 25] 3 print(a) 4 5 #和字符串一样,列表同样可以被索引和切片, 6 #列表被切片后返回一个包含所需元素的新列表 7 a[1:3] 8 9 #列表还支持串联操作,使用+操作符 10 a = [1, 2, 3, 4, 5] 11 a + [6, 7, 8] 12 #[1, 2, 3, 4, 5, 6, 7, 8] 13 14 #列表中的元素是可以改变的: 15 a = [1, 2, 3, 4, 5, 6] 16 a[0] = 9 17 a[2:5] = [13, 14, 15] 18 a 19 #[9, 2, 13, 14, 15, 6] 20 a[2:5] = [] # 删除 21 a 22 #[9, 2, 6] 23 24 #判断值是否存在列表中 25 25 in a 26 27 2 in a 28 29 #判断多个值,那么就要用到set 30 set([2, 100]) <= set(a)
1 a = (1991, 2014, ‘physics‘, ‘math‘) 2 print(a, type(a), len(a)) 3 #(1991, 2014, ‘physics‘, ‘math‘) <class ‘tuple‘> 4 4 #元组与字符串类似,可以被索引且下标索引从0开始, 5 #也可以进行截取/切片 6 7 #其实,可以把字符串看作一种特殊的元组。 8 tup = (1, 2, 3, 4, 5, 6) 9 print(tup[0], tup[1:5]) 10 #1 (2, 3, 4, 5) 11 tup[0] = 11 # 修改元组元素的操作是非法的 12 13 #虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。 14 #构造包含0个或1个元素的tuple是个特殊的问题,所以有一些额外的语法规则: 15 tup1 = () # 空元组 16 tup2 = (20,) 17 tup2 = (20) 18 19 #另外,元组也支持用+操作符: 20 tup1, tup2 = (1, 2, 3), (4, 5, 6) 21 22 print(tup1+tup2) 23 #(1, 2, 3, 4, 5, 6)
1 student = {‘Tom‘, ‘Jim‘, ‘Mary‘, ‘Tom‘, ‘Jack‘, ‘Rose‘} 2 print(student) # 重复的元素被自动去掉 3 #{‘Jim‘, ‘Jack‘, ‘Mary‘, ‘Tom‘, ‘Rose‘} 4 5 ‘Rose‘ in student # membership testing(成员测试) 6 #True 7 8 ‘KEN‘ in student # membership testing(成员测试) 9 10 # set可以进行集合运算 11 a = set(‘abracadabra‘) 12 b = set(‘alacazam‘) 13 a 14 b 15 #{‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘r‘} 16 a - b # a和b的差集 17 #{‘b‘, ‘d‘, ‘r‘} 18 a | b # a和b的并集 19 #{‘l‘, ‘m‘, ‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘z‘, ‘r‘} 20 a & b # a和b的交集 21 #{‘a‘, ‘c‘} 22 a ^ b # a和b中不同时存在的元素 23 #{‘l‘, ‘m‘, ‘b‘, ‘d‘, ‘z‘, ‘r‘} 24 25 a = [‘him‘, 25, 100, ‘her‘, 100, 25] 26 27 #判断多个值,那么就要用到set 28 set([25, 100]) <= set(a)
1 dic = {} # 创建空字典 2 tel = {‘Jack‘:1557, ‘Tom‘:1320, ‘Rose‘:1886} 3 tel 4 #{‘Tom‘: 1320, ‘Jack‘: 1557, ‘Rose‘: 1886} 5 6 tel[‘Jack‘] # 主要的操作:通过key查询 7 #1557 8 9 del tel[‘Rose‘] # 删除一个键值对 10 tel 11 12 tel[‘Mary‘] = 4127 # 添加一个键值对 13 tel 14 #{‘Tom‘: 1320, ‘Jack‘: 1557, ‘Mary‘: 4127} 15 16 list(tel.keys()) # 返回所有key组成的list 17 #[‘Tom‘, ‘Jack‘, ‘Mary‘] 18 19 sorted(tel.keys()) # 按key排序 20 #[‘Jack‘, ‘Mary‘, ‘Tom‘] 21 22 ‘Tom‘ in tel # 成员测试 23 #True 24 25 ‘Mary‘ not in tel # 成员测试 26 #False 27 28 ‘KEN‘ in tel 29 30 #构造函数 dict() 直接从键值对sequence中构建字典,当然也可以进行推导,如下: 31 dict([(‘sape‘, 4139), (‘guido‘, 4127), (‘jack‘, 4098)]) 32 #{‘jack‘: 4098, ‘sape‘: 4139, ‘guido‘: 4127} 33 34 dict(sape=4139, guido=4127, jack=4098) 35 #{‘jack‘: 4098, ‘sape‘: 4139, ‘guido‘: 4127}
pandas数据结构:包含Series(系列)和DataFrame(数据框)
系列是用于存储一行或者一列的数据,以及与之相关的索引集合
1 from pandas import Series; 2 3 #定义,可以混合定义 4 x = Series([‘a‘, True, 1], index=[‘first‘, ‘second‘, ‘third‘]); 5 x = Series([‘a‘, True, 1]); 6 7 #访问 8 x[1]; 9 #根据index访问 10 x[‘second‘]; 11 12 #不能越界访问 13 x[3] 14 15 #不能追加单个元素 16 x.append(‘2‘) 17 #追加一个序列 18 n = Series([‘2‘]) 19 x.append(n) 20 21 #需要使用一个变量来承载变化 22 x = x.append(n) 23 24 ‘2‘ in x 25 26 #判断值是否存在 27 ‘2‘ in x.values 28 29 #切片 30 x[1:3] 31 32 #定位获取,这个方法经常用于随机抽样 33 x[[0, 2, 1]] 34 35 #根据index删除 36 x.drop(0) 37 x.drop(‘first‘) 38 39 #根据位置删除 40 x.drop(x.index[3]) 41 42 #根据值删除 43 x[‘2‘!=x.values]
数据框是用于存储多行和多列的数据集合
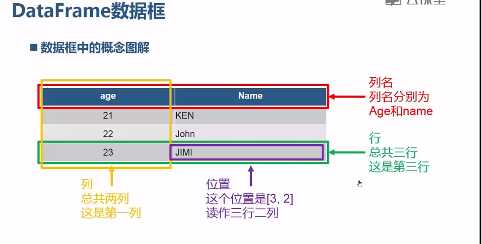
1 from pandas import DataFrame; 2 3 df = DataFrame({ 4 ‘age‘: [21, 22, 23], 5 ‘name‘: [‘KEN‘, ‘John‘, ‘JIMI‘] 6 }); 7 8 df = DataFrame(data={ 9 ‘age‘: [21, 22, 23], 10 ‘name‘: [‘KEN‘, ‘John‘, ‘JIMI‘] 11 }, index=[‘first‘, ‘second‘, ‘third‘]); 12 13 df 14 15 #按列访问 16 df[‘age‘] 17 #按行访问 18 df[1:2] 19 20 #按行列号访问 21 df.iloc[0:1, 0:1] 22 23 #按行索引,列名访问 24 df.at[0, ‘name‘] 25 26 #修改列名 27 df.columns 28 df.columns=[‘age2‘, ‘name2‘] 29 30 #修改行索引 31 df.index 32 df.index = range(1,4) 33 df.index 34 35 #根据行索引删除 36 df.drop(1, axis=0) 37 #默认参数axis=0 38 #根据列名进行删除 39 df.drop(‘age2‘, axis=1) 40 41 #第二种删除列的方法 42 del df[‘age2‘] 43 44 #增加行,注意,这种方法,效率非常低,不应该用于遍历中 45 df.loc[len(df)] = [24, "KENKEN"]; 46 47 #增加列 48 df[‘newColumn‘] = [2, 4, 6, 8];
顺序结构,从上到下执行代码
选择结构:if....else....
1 """ 2 if 判断条件: 3 执行语句…… 4 else: 5 执行语句…… 6 """ 7 8 flag = False 9 name = ‘luren‘ 10 if name == ‘python‘: # 判断变量否为‘python‘ 11 flag = True # 条件成立时设置标志为真 12 print(‘welcome boss‘) # 并输出欢迎信息 13 else: 14 print(name) # 条件不成立时输出变量名称 15 16 17 18 num = 5 19 if num == 3: # 判断num的值 20 print(‘boss‘) 21 elif num == 2: 22 print(‘user‘) 23 elif num == 1: 24 print(‘worker‘) 25 elif num < 0: # 值小于零时输出 26 print(‘error‘) 27 else: 28 print(‘roadman‘) # 条件均不成立时输出
循环结构:while、for
1 from pandas import Series; 2 from pandas import DataFrame; 3 4 for i in range(10): 5 print(‘现在是: ‘, i) 6 7 for i in range(3, 10): 8 print(i) 9 10 #遍历字符串 11 for letter in ‘Python‘: 12 print (‘现在是 :‘, letter) 13 14 #遍历数组 15 fruits = [‘banana‘, ‘apple‘, ‘mango‘] 16 17 for fruit in fruits: 18 print (‘现在是 :‘, fruit) 19 20 #遍历序列 21 x = Series([‘a‘, True, 1], index=[‘first‘, ‘second‘, ‘third‘]); 22 x[0]; 23 x[‘second‘]; 24 x[2]; 25 26 for v in x: 27 print("x中的值 :", v); 28 29 for index in x.index: 30 print("x中的索引 :", index); 31 print("x中的值 :", x[index]); 32 print("---------------------") 33 34 #遍历数据框 35 df = DataFrame({ 36 ‘age‘: Series([21, 22, 23]), 37 ‘name‘: Series([‘KEN‘, ‘John‘, ‘JIMI‘]) 38 }); 39 40 #遍历列名 41 for r in df: 42 print(r); 43 44 #遍历列 45 for cName in df: 46 print(‘df中的列 :\n‘, cName) 47 print(‘df中的值 :\n‘, df[cName]); 48 print("---------------------") 49 50 #遍历行,方法一 51 for rIndex in df.index: 52 print(‘现在是第 ‘, rIndex, ‘ 行‘) 53 print(df.irow(rIndex)) 54 55 #遍历行,方法二 56 for r in df.values: 57 print(r) 58 print(r[0]) 59 print(r[1]) 60 print("---------------------") 61 62 #遍历行,方法三 63 for index, row in df.iterrows(): 64 print(‘第 ‘, index, ‘ 行:‘) 65 print(row) 66 print("---------------------") 67
1 from pandas import Series; 2 from pandas import DataFrame; 3 4 #最普通的while循环 5 i = 0 6 while i <= 9: 7 print(‘遍历到 :‘, i); 8 i = i+1; 9 10 #整合if判断语句,使用continue 11 i = 1 12 while i < 10: 13 i += 1 # i = i + 1 14 if i%2 != 0: # 非双数时跳过输出 15 continue 16 print(i) # 输出双数2、4、6、8、10 17 18 #整合if判断语句,使用break 19 i = 1 20 while True: # 循环条件为1必定成立 21 print(i) # 输出1~10 22 i += 1 23 if i > 10: # 当i大于10时跳出循环 24 break 25 26 #当然,我们也可以使用while语句来访问DataFrame等数据结构 27 df = DataFrame({ 28 ‘age‘: Series([21, 22, 23]), 29 ‘name‘: Series([‘KEN‘, ‘John‘, ‘JIMI‘]) 30 }); 31 32 rowCount = len(df); 33 34 i = 0; 35 36 while i<rowCount: 37 print(df.irow(i)); 38 i = i+1; 39 print("-------------------------")
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 4 # 不带参数的函数 5 def printLine(): 6 #输出一条横线 7 print("--------------------------------------------"); 8 #没有返回值 9 #return; 10 11 printLine(); 12 13 # 带参数的函数 14 def printInfo(name, age): 15 print("name is: ", name, "; age is: ", age); 16 #没有返回值 17 return; 18 19 # 正确调用 20 printInfo("KEN", 18); 21 printInfo(age=18, name="KEN"); 22 23 #错误调用 24 printInfo("KEN"); 25 26 # 默认参数的函数 27 def printInfo(name, age=20): 28 print("name is: ", name, "; age is: ", age); 29 #没有返回值 30 return; 31 32 #正确调用 33 printInfo("KEN"); 34 35 36 # 可变长参数的函数--数组形式 37 def printInfo(name, *args): 38 #打印任何传入的字符串 39 print("name is: ", name); 40 printLine(); 41 for arg in args: 42 print(arg); 43 #没有返回值 44 return; 45 46 #正确调用 47 printInfo("KEN", 20, "男", 178, "70KG", ‘abc‘); 48 49 50 # 可变长参数的函数--kv方式 51 def printInfo(name, **kvArgs): 52 #打印任何传入的字符串 53 print("name is: ", name); 54 printLine(); 55 for k in kvArgs: 56 print(k, "is: ", kvArgs[k]); 57 #没有返回值 58 return; 59 60 #正确调用 61 printInfo("KEN", age=20, sex="男", height="178", weight="70KG"); 62 63 #错误调用 64 printInfo("KEN", 20, "男"); 65 66 67 #有返回值的函数 68 def maxValue(*args): 69 rValue = args[0]; 70 for var in args: 71 if rValue < var : 72 rValue = var; 73 return rValue; 74 75 r = maxValue(4, 5, 2, 6, 7, 1); 76 print(r); 77 78 sumValue = lambda arg1, arg2: arg1+arg2; 79 r = sumValue(1, 5) 80 print(r) 81 82 import numpy; 83 from pandas import DataFrame; 84 85 df = DataFrame({ 86 ‘key1‘: [‘a‘,‘a‘,‘b‘,‘b‘,‘a‘], 87 ‘key2‘: [‘one‘,‘two‘,‘one‘,‘two‘,‘one‘], 88 ‘data1‘: numpy.random.randn(5), 89 ‘data2‘: numpy.random.randn(5) 90 }); 91 92 df.groupby(‘key1‘)[‘data1‘,‘data2‘].agg(lambda arr:arr.max()-arr.min())
向量化计算是一种特殊的并行计算的方式,相比于一般程序在同一时间只能执行一个操作的方式,它可以在同一时间执行多次操作,通常是对不同的数据执行同样的一个或者一批指令,或者说把指令应用与一个数组/向量。
生成等差数列、四则运算
1 #生成一个整数的等差序列 2 #局限,只能用于遍历 3 r1_10 = range(1, 10, 2) 4 5 for i in r1_10: 6 print(i) 7 8 r1_10 = range(0.1, 10, 2) 9 10 11 #生成一个小数的等差序列 12 import numpy 13 numpy.arange(0.1, 0.5, 0.01) 14 15 r = numpy.arange(0.1, 0.5, 0.01) 16 17 #向量化计算,四则运算 18 r + r 19 r - r 20 r * r 21 r / r 22 23 #长短不一时 24 r + 1 25 26 #函数式的向量化计算 27 numpy.power(r, 5) 28 29 #向量化运算,比较运算 30 r>0.3 31 #结合过滤进行使用 32 r[r>0.3] 33 34 #矩阵运算 35 numpy.dot(r, r.T) 36 37 sum(r*r) 38 39 from pandas import DataFrame 40 df = DataFrame({ 41 ‘data1‘: numpy.random.randn(5), 42 ‘data2‘: numpy.random.randn(5) 43 }) 44 45 df.apply(lambda x: min(x)) 46 47 df.apply(lambda x: min(x), axis=1) 48 49 #判断每个列,值是否都大于0 50 df.apply(lambda x: numpy.all(x>0), axis=1) 51 #结合过滤 52 df[df.apply(lambda x: numpy.all(x>0), axis=1)]
标签:dde 遍历 count org 可变长参数 seq 大于 冒号 查询
原文地址:https://www.cnblogs.com/garrett0220/p/10856679.html
