标签:一个人 splay 重要性 .com 介绍 时间 也有 缺点 gre
PageRank算法是1998年由斯坦福大学的学生Larry page和Sergrey Brin发明的,是Google搜索引擎的重要算法。目的是基于网络的互联性来客观地计算网页受欢迎程度或重要性。其背后有两个主要依据:
(1)具有更多的传入链接的页面比具有较少的传入链接的页面重要。
(2)一个页面有一个高度重要性的页面链入,则这个页面也很重要。
在PageRank算法中,通常会将所有的页面看成一个个点,将网页中指向其他网页的链接关系看成有向边,然后将这些点和有向边组成网络关系并利用网络关系进行计算。PageRank算法中为所有点赋予PR值来表示这个点的大小关系或重要程度,而这个值的大小是根据这个点的链入数量和链出数量来决定的。PageRank算法从理论上讲是一个人在点击任意次链接后到达某一个页面概率的大小,如果其中一个页面被一个高质量的页面链接到,则这个页面会有较大的概率被访问到。所以被越重要的网页链入的页面,这个页面也会背变得重要。
设网络中的一个页面为A,则A页面的PR值等于所有链入A页面的PR值之和:
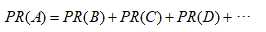
如下图,若一个页面只有链入,则PR(A)=0.25+0.25+0.25=0.75.
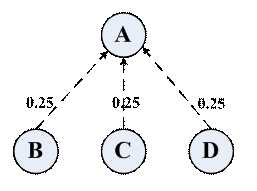
但由于每一个网页有可能有链出的关系,所以A页面的PR值等于所有链入A页面的PR值比上每个页面的链出的数量的比值之和:
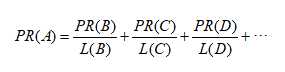
如下图,若一个页面有链入也有链出:
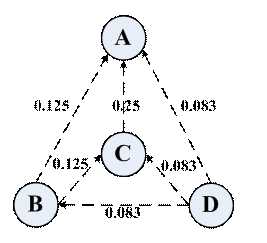
其中,B,C,D都是指链入A页面的页面,而L(v)是指页面v所包含的链出个数,PR(v)则表示页面v的PageRank值。
PR(A)=PR(B)/2+PR(C)+PR(D)/3
由此可以看出,如果页面A被很多PR值低的页面链接,页面A的PR值并不会一定高。一个PR值高但有许多链出的页面对页面A 的贡献也并不一定比本身PR值不高,但仅仅指向页面A的贡献值大。
我们知道人们浏览网页时,不会永无止境的浏览下去,所以在公式中给每一个网页的PR值乘以一个阻尼系数d,每个网页最小的PR值为1-d。下列是完整的PageRank算法的计算公式:
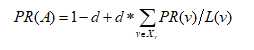
其中,X为链入页面A所有的页面。
优点:
(1)与查询无关的静态算法,所有网页的PageRank值都是离线计算好的;
(2)有效的减少了在线查询时的计算量,减少了查询响应时间;
缺点:过分的相信链接关系
(1)一些权威网站往往都是互不链接的,因为存在竞争关系;
(2)人们的查询具有主题特征,PageRank忽略了主题相关性,导致结果的相关性和主题相关性降低;
(3)旧的页面等级比新的页面等级高。
标签:一个人 splay 重要性 .com 介绍 时间 也有 缺点 gre
原文地址:https://www.cnblogs.com/r0825/p/10858366.html