标签:grafana Fix replicat apple 定时任务 进程 sts 定向 item
8.资源对象对pod的调度??在kubernetes集群中,pod基本上都是容器的载体,通常需要通过相应的资源对象来完成一组pod的调度和自动控制功能,比如:deployment、daemonSet、RC、Job等等。接下来小编将一一介绍这些资源对象如何调度pod。
??Deployment/RC的主要功能之一就是自动部署一个容器应用的多个副本,以及持续监控副本数量,在集群内始终维持用户指定的副本数量。
举例:(这里以deployment为例)
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.io/nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80[root@zy yaml_file]# kubectl create -f nginx-deployment.yaml #创建deployment
[root@zy yaml_file]# kubectl get pod #查看创建的pod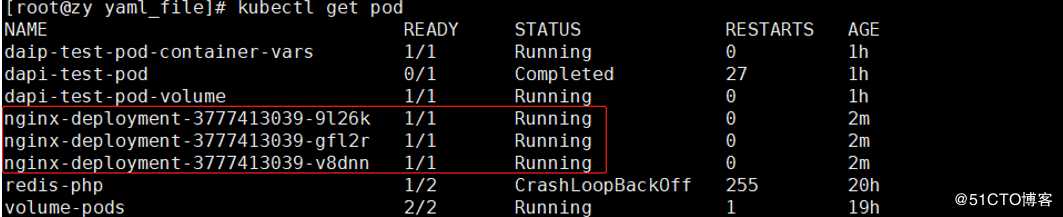
[root@zy yaml_file]# kubectl get deploy #查看deploy 状态
[root@zy yaml_file]# kubectl get rs #查看RS状态
注意:如果想删除pod,不能直接kubectl delete pod,因为这些pod归deployment管理,如果想删除pod,只需要将replicas设置为0,并删除该deployment即可。
从调度上来说,如果在集群模式下,刚刚创建的3个pod完全是由系统全自动的完成调度,他们最终在哪些节点运行,完全是由master的scheduler经过一系列的复杂算法计算得出的,用户无法干预。
??Deployment/RC对pod的调度用户是无法干预的,如果我们想将一个pod定向的在某个特定的节点上运行,那该怎么做呢?还记得之前说过的标签吗,如此强大的功能不用就浪费了,这里我们可以使用node的标签,和pod的nodeSelector属性相匹配,来达到上述的目的。
举例:
#为node创建标签:
[root@zy yaml_file]# kubectl get node #查看集群node
[root@zy yaml_file]# kubectl label nodes 127.0.0.1 zone=north #给node打标签
#定义pod:redis-master-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: node-pod
labels:
name: node-pod
spec:
containers:
- name: node-pod
image: docker.io/kubeguide/redis-master
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
nodeSelector:
zone: north[root@zy yaml_file]# kubectl create -f redis-master-pod.yaml这样,pod就会被定向到有zone: north 标签的node上去运行,当然这里如果定义的deployment/RC的话,会根据副本数,在相应的具有标签的node上运行。
??DaemonSet是kubernetes在v1.2版本更新的时候新增的一种资源对象,用于管理在集群汇总每一个node上仅运行一份pod的副本实例。(如下图)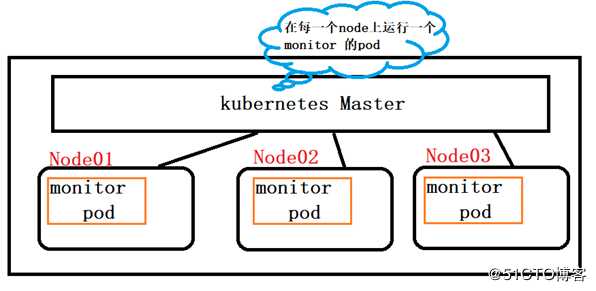
DaemonSet的应用场景有:
?? 在每一个node上运行一个GlusterFS存储或者Ceph存储的Daeson进程
?? 在每个node上运行一个日志采集程序,例如:Fluentd或者Logstach
?? 在每台node上运行一个性能监控程序,采集node的运行性能数据,如:Prometheus、collectd、New Relic agent
?接下来小编就给出一个例子定义为在每台node上启动一个fluentd容器,配置文件fluentd-ds.yaml的内容如下,其挂载了物理机的两个目录“/var/log”和“/var/lib/docker/containers”:
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: fluentd-cloud-logging
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
template:
metadata:
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
containers:
- name: fluentd-cloud-logging
image: docker.io/forkdelta/fluentd-elasticsearch
resrouces:
limits:
cpu: 100m
memory: 200Mi
env:
- name: FLUENTD_ARGS
value: -q
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: false
- name: containers
mountPath: /var/lib/dpcker/containers
readOnly: false
volumes:
- name: containers
hostPath:
path: /var/lib/dpcker/containers
- name: varlog
hostPath:
path: /var/log??Kubernetes在v1.2版本开始支持批处理类型的应用,可以通过kubernetes Job资源对象来定义并启动一个批处理任务。批处理任务提高通常并行(或者串行)启动多个计算进程去处理一批工作项(work items),处理完成之后,整个批处理任务结束。
?批处理任务可以分为以下几种模式:
??? Job Template Expansion模式:一个Job对象对应一个待处理的work item,有几个work items就会产生几个独立的job(通常适合work items较少,但是处理的数据量比较大的场景)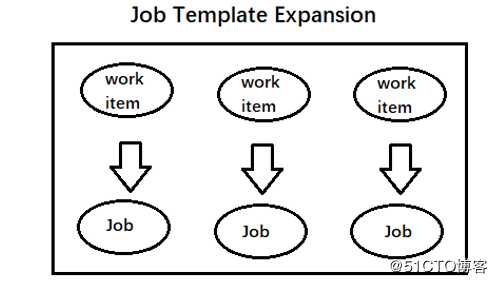
??? Queue with Pod Work Item模式:采用一个任务队列存放Work Items,一个job对象作为消费者去完成这些Work Items,这种模式下会启动一个Job和N个Pod,每一个Pod对应一个Work Item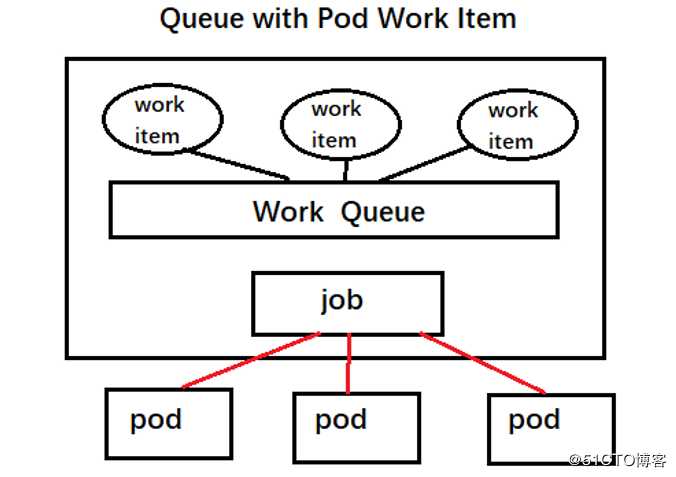
??? Queue with Varibale Pod Conut模式:这也是采用的Work Items的方式,但是不同的是,一个Job启动的pod的数量是可以改变的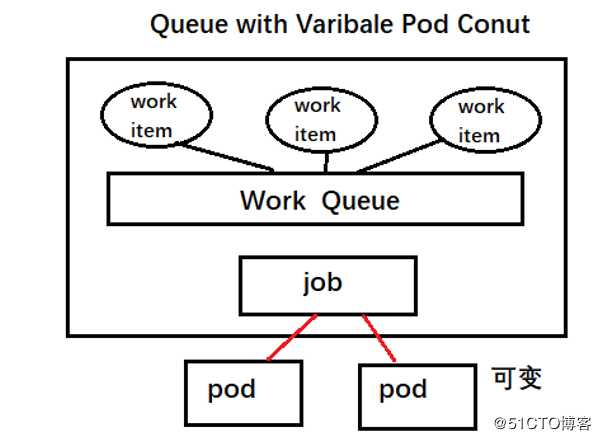
??? Single Job with Static Work Assignment模式:也是一个job产生多个pod完成任务,但是它采用的静态方式分配任务,而并非任务队列的方式动态分配
几种批处理任务的模式对比
考虑到批处理的并行问题,kubernetes将job分为以下三种类型:
?? Non-parallel Jobs:通常一个job只启动一个pod,只有pod异常才会重启pod,pod正常结束,Job也结束
?? Parallel Jobs with a fixed completion count:并行Job会启动多个pod,正常的pod结束的数量达到设定的值后,Job结束。其中有两个参数
???? Spec.completions:预期的pod正常退出的个数
????Spec.parallelism:启动的Job数
?? Parallel Jobs with a work queue:所有的work item都在一个queue中,Job启动的pod能判断是否queue中还有任务需要处理,如果某个pod正常结束,job不会启动新的pod,如果有一个pod结束,那么job下其他pod将不存在干活的情况,至少有一个pod正常结束时,job算成功结束。
接下来小编介绍一下上面三种常见的批处理模型在kubernetes中的实例:
Job Template Expansion模式:
apiVersion: batch/v1
kind: Job
medata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: docker.io/busybox
imagePullPolicy: IfNotPresent
command: ["sh","-c","echo Processing item $ITEM && sleep 5"]
restartPolicy: Never#以上面的yaml内容为模板,创建三个job的定义文件:
[root@zy yaml_file]# for i in apple banana cherry ;do cat job.yaml |sed "s/\$ITEM/$i/" > job-$i.yaml ;done
[root@zy yaml_file]#mkdir jobs && mv job-* jobs #将job的定义文件统一放入jobs目录下
[root@zy yaml_file]# kubectl create -f jobs #创建job
[root@zy yaml_file]# kubectl get jobs 查看job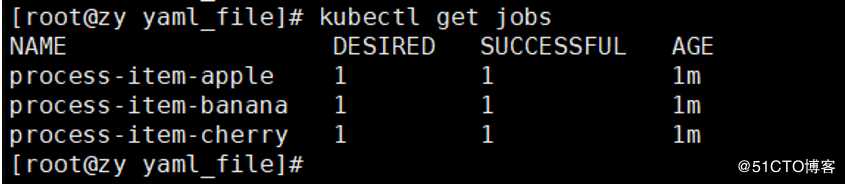
[root@zy yaml_file]# docker ps -a #通过查看创建container,查看任务打印的内容
[root@zy yaml_file]# kubectl get pod --show-all #查看pod Queue with Pod Work Item模式:
??在这种模式下需要一个任务队列存放work items,比如kafka、RabbitMQ,客户端将需要处理的任务放入队列中,然后编写worker程序并打包成为镜像并定义成为Job中的work Pod,worker程序的实现逻辑就是从任务队列中拉取一个work item并处理,处理完结束进程。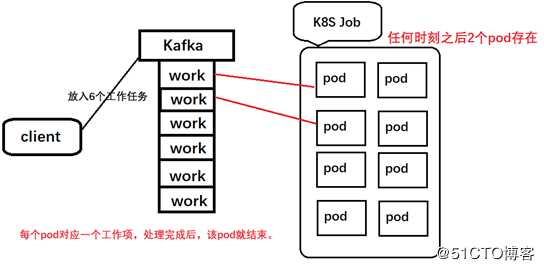
Queue with Varibale Pod Conut模式:
??这种模式下worker程序需要知道队列中是否还有等待处理的work item,如果有就取出来并处理,否则认为所有的工作完成,job结束。此处的任务队列通常用Redis来实现。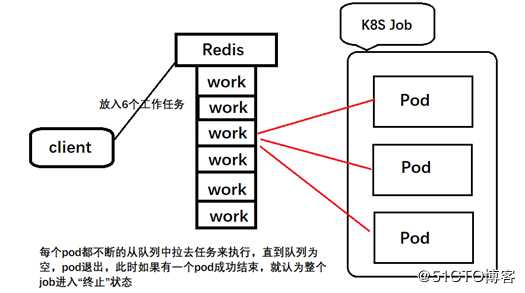
??Kubernetes从v1.5版本开始增加了一个新类型的Job,类似于Linux crond的定时任务,Crond Job,下面,小编向大家介绍一下这个类型的Job如何使用。
??先想使用这个类型的Job,必须是kubernetes1.5版本以上,并且在启动API server是加入参数:--runtime-config=batch/v2alpha1=true(在apiserver 的配置文件中加入/etc/kubernetes/apiserver)
然后重启:[root@zy yaml_file]# systemctl restart kube-apiserver#编写crond Job的定义:
apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: docker.io/busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- date; echo Hell from the Kubernetes cluster
restartPolicy: OnFailure[root@zy yaml_file]# kubectl create -f cron.yaml #创建CronJob
[root@zy yaml_file]# kubectl get cronjob #查看CronJob任务
[root@zy yaml_file]# kubectl get jobs --watch #查看job,可以发现有每分钟都会有一个job执行注意:这里的任务执行的周期与linux crond相同(分 时 日 月 周)
??在很多场景下,我们在启动应用之前需要进行一些列的初始化,在kubernetes1.5版本之后,init Container被应用于启动应用容器之前启动一个或者多个“初始化”容器,完成应用容器所需要的预置条件。它们仅仅运行一次就结束,当所有定义的init Container都正常启动之后,才会启动应用容器。
下面小编演示一个案例:在启动nginx服务之前,通过初始化buxybox为nginx创建一个index.html主页:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
initContainers:
- name: install
image: docker.io/busybox
imagePullPolicy: IfNotPresent
command:
- wget
- "-O"
- "/work-dir/index.html"
- http://kubernetes.io
volumeMounts:
- name: workdir
mountPath: "/work-dir"
containers:
- name: ngxin
image: docker.io/nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
dnsPolicy: Default
volumes:
- name: workdir
emptyDir: {}这里注意如果是k8s的版本比较低的话,这里的initContainers 不会被识别,可能会报错:
使用init container的注意事项:
??? 如果定义多个init container,必须上一个运行完成才能运行下一个
??? 多个init container定义资源请求,取最大的那个为有效请求
??? Pod重启时,init container会跟着重启
??当我们新应用部署的时候,需要将pod中image换成新打包的image,但是由于在生产环境,又不能让服务较长时间的不可用,这时kubernetes提供了滚动升级功能来解决这个难题。
小编这里以deployment为例,用三个nginx的服务,进行image的替换,查看究竟kubernetes如何实现滚动升级的:
#nginx-deplyment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.io/nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80[root@zy yaml_file]# kubectl create -f nginx-deployment.yaml
[root@zy yaml_file]# kubectl get pod #查看pod
[root@zy yaml_file]# kubectl get rs #查看由deployment创建的RS
#此时我们将pod中的image设置为docker.io/linuxserver/nginx
[root@zy yaml_file]# kubectl set image deployment/nginx-deployment nginx=docker.io/linuxserver/nginx
或者:
[root@zy yaml_file]# kubectl edit deployment/nginx-deployment
[root@zy yaml_file]# kubectl rollout status deployment/nginx-deployment #可以查看滚动升级的过程
#我们查看具体的更新细节
[root@zy yaml_file]# kubectl describe deployment/nginx-deployment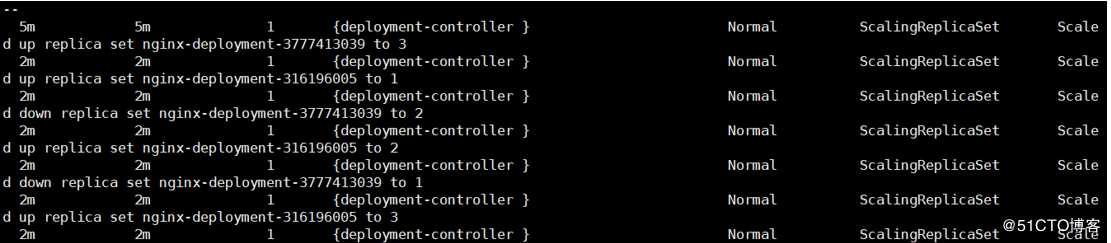
[root@zy yaml_file]# kubectl get rs #查看RS
那到底是怎么更新的呢?由上面的截图我们可以看出:
初始创建deployment时,系统创建了一个RS并按照配置的replicas创建了3个Pod,当deployment更新时,系统又创建了一个新的RS,逐渐的将旧的RS的副本数从3缩小到0,而将新的RS的副本数从0逐渐增加到3,最后就是以这样的方式,在服务不停止的情况下巧妙的完成了更新。
更新策略:
?? Recereate(重构):设置:spec.strategy.type=Recreate,表示deployment更新过程中会先杀死所有正在运行的pod,然后在重新创建。(会造成服务中断)
?? RollingUpdate(滚动更新):设置:spec.strategy.type=RollingUpdate,表示deployment以滚动更新的方式来逐渐更新pod,滚动更新有两个重要的参数
????spec.strategy.type.rollingUpdate.maxUnavailabe:用于指定deployment在更新过程中不可用pod的数量的上限(v1.6之后默认将1改为25%):也就是说,当这个值设置为2的时候,并且replicas是5的话,在更新时至少要有3个pod能正常提供对外服务。
????spec.strategy.type.rollingUpdate.maxSurge:表示指定deployment更新Pod过程中Pod总数不能超过Pod期望副本数部分的最大值(v1.6之后默认将1改为25%),也就是说,当这个值设置为2的时候,并且replicas是5的话,正在运行的Pod不能超过7个。
更新的注意点:
?? deployment会为每一次更新都创建一个RS,如果当deployment本次更新未完成,用户又发起了下一次更新,此时deployment不会等本次更新完成之后再进行下一次更新,它会将本次更新的所有的Pod全部杀死,直接进入下一次更新
?? 关于更新label和label selector的问题
???? 更新时deployment的标签选择器时,必须同时更新deployment中定义的pod的label,否则deployment更新会报错
???? 添加或者修改deployment的标签选择器时会导致新的标签选择器不会匹配就选择器创建的RS和Pod,则这些RS和Pod处于孤立状态,不会被系统自动删除
???? 在deployment的selector中删除一个或者多个标签,deployment的RS和Pod不会受到影响,但是被删除的label仍然会留在已有的RS和Pod中
??有时,因为新版本不稳定时,我们可能将deployment回滚到旧的版本,默认情况下deployment发布的所有历史记录都会留在系统中,这里小编向大家展示如何回退版本:
#查看deployment历史
[root@zy yaml_file]# kubectl rollout history deployment/nginx-deployment 
这里我们看不见deployment创建的命令,如果在创建deployment加入--record参数,这里就能看见deployment的创建命令
#查看某个特定版本的deployment的详细信息
[root@zy yaml_file]# kubectl rollout history deployment/nginx-deployment --revision=1 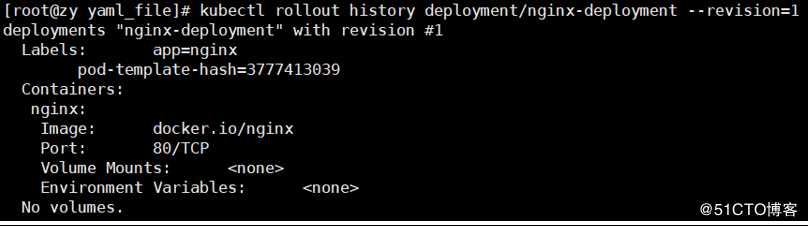
#撤销本次发布并回退上一个部署版本
[root@zy yaml_file]# kubectl rollout undo deployment/nginx-deployment
#回滚到特定的版本
[root@zy yaml_file]# kubectl rollout undo deployment/nginx-deployment --to-revision=2
① 暂停或恢复deployment的部署操作
??对于一次复杂的deployment的配置修改,为了避免频繁的更新deployment,我们可以先暂停deployment的更新操作,然后进行配置,再恢复更新,一次性触发完整的更新操作。
#暂停deployment的更新
[root@zy yaml_file]# kubectl rollout pause deployment/nginx-deployment
之后我们可以做一系列的操作,更新image,设置资源。(这里修改之后不会触发更新)
#恢复更新
[root@zy yaml_file]# kubectl rollout resume deployment/nginx-deployment
恢复之后,该deployment会一次性更新所有操作。
② 使用kubeclt rolling-update命令完成RC的更新
??对于RC的更新我们可以通过命令kubeclt rolling-update实现。但是该命令会创建一个新的RC,并将旧的RC的pod逐渐降低到0,新的RC的pod逐渐增加到replicas设置的值,并且新的RC必须和旧的RC在同一namespace下。
这里小编以一个例子演示:
#redis-mater-controller-v2.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master-v2
labels:
name: redis-master-v3
new-version: v3
spec:
replicas: 1
selector:
name: redis-master-v3
new-version: v3
template:
metadata:
labels:
name: redis-master-v3
new-version: v3
spec:
containers:
- name: master
image: docker.io/kubeguide/redis-master:v3.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379[root@zy yaml_file]# kubectl create -f redis-mater-controller-v2.yaml #创建这个RC此时我们想将image替换成v3.0,这是就需要对RC滚动升级,这里注意两点:
?? RC的名字不能与旧的RC的名字相同
?? 在selector中应至少有一个Label与旧的RC的label不同
#更新
[root@zy yaml_file]# kubectl rolling-update redis-master-v2 -f redis-mater-controller-v3.yaml
#回滚
[root@zy yaml_file]# kubectl rolling-update redis-master-v3 --image=docker.io/kubeguide/redis-master --rollback
注意:RC的滚动升级不具有deployment在应用版本升级过程中的历史记录、新旧版本数量的精细控制。
③ 其他管理对象的更新策略
?? DaemonSet的更新:OnDelete 和 RollingUpdate两种方式
?? StatefulSet的更新:kubernetes1.6之后,开始逐渐对StatefulSet的更新向deployment看齐,目前了解较少
??在实际的生产中,我们经常会遇到某个服务因为压力过大,需要扩容,有可能遇到当集群资源过度紧张的时候,减少一部分服务的副本。在kubernetes中我们可以利用deployment的Scale实现。
??Kubernetes对pod的扩容和缩容提供了手动和自动的两种方式。手动则是执行命令,而自动测试更具某个性能指标,并指定pod的副本数量范围,由系统自动的在这个范围内根据性能指标进行调整。
① 手动扩容
#这里以一个简单的nginx为例:
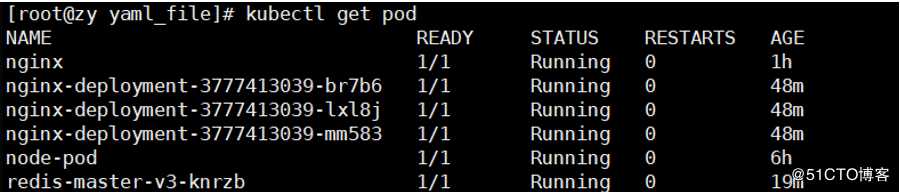
这里deployment管理3个pod的副本,我们将其设置为5个
[root@zy yaml_file]# kubectl scale deployment nginx-deployment --replicas=5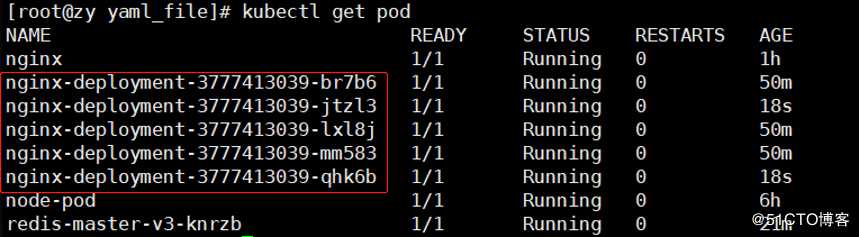
#在缩容到1个
[root@zy yaml_file]# kubectl scale deployment nginx-deployment --replicas=1
② 自动扩容
??从kubernetes1.1开始,新增了一个名为Horizontal Pod Autoscaler(HPA)的控制器,用于实现CPU使用率进行自动Pod扩容和缩容。(这里必须先安装Heapster)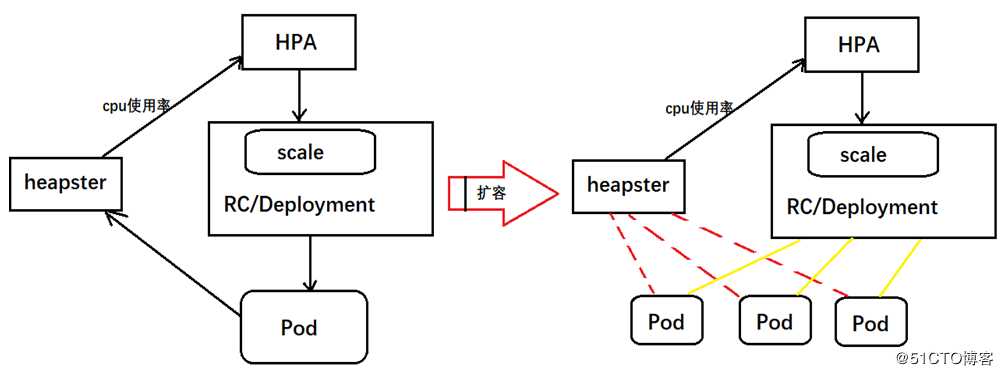
??这里小编也是一个案例说明,我们创建一个Tomcat的pod由deployment管理,并且提供一个service供外部访问,同时设置HPA实时监控deploy的CPU使用率,自动pod扩容,最后使用一个循环压力测试这个服务(不断地访问Tomcat),查看deploy的扩容与缩容情况:
#tomcat-apache-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: tocamt-apache
spec:
replicas: 1
template:
metadata:
name: tocamt-apache
labels:
app: tocamt-apache
spec:
containers:
- name: tocamt-apache
image: tomcat
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 20m #注意这里一定要设置cpu的请求,不然Heapster无法采集
ports:
- containerPort: 80#tomcat-apache-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: tomcat-apache
spec:
ports:
- port: 80
selector:
app: tocamt-apache#定义或者创建HPA:
[root@zy yaml_file]# kubectl autoscale deployment tomcat-apache --min=1 --max=10 --cpu-percent=50 命令解释:表示pod的数量在1~10之间,以使得平均podCPU使用率维持在50%
或者yaml文件:
#hpa-tomcat-apache.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: tomcat-apache
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: tocamt-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50最后我们在创建一个busybox 的pod,然后进入容器,执行
while true;do wget -q -O- http:ClusterIP >dev/null ;done对这个deployment进行压力测试,最后可以看到deploy管理的这个pod的数量数变化的,但始终保持pod平均的CPU使用率在50%左右,当将这个压力测试的容器关闭时,pod的数量又会变成原先定义的1个。
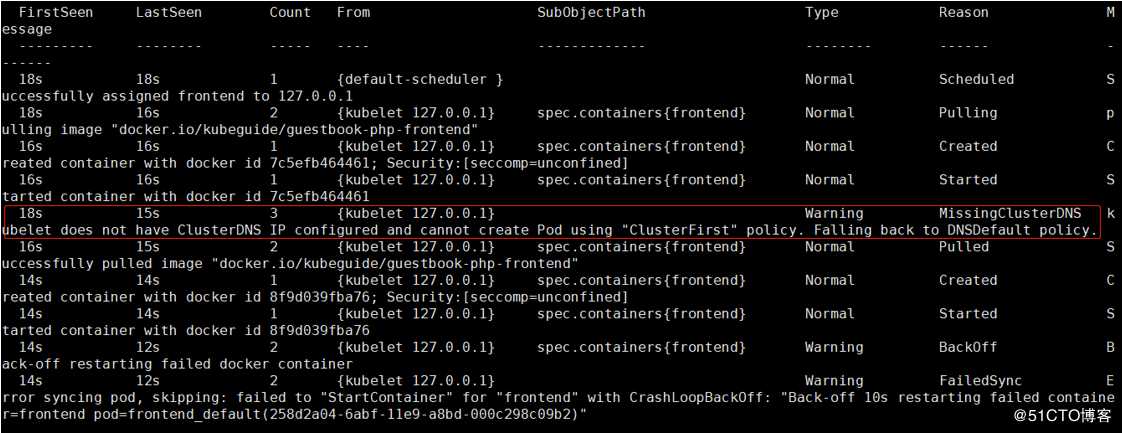
原因:根据报错信息,pod启动需要registry.access.redhat.com/rhel7/pod-infrastructure:latest镜像,需要去红帽仓库里下载,但是没有证书,安装证书之后就可以了。
解决:
① 确认docker是否正常启动
[root@zy ~]# systemctl status docker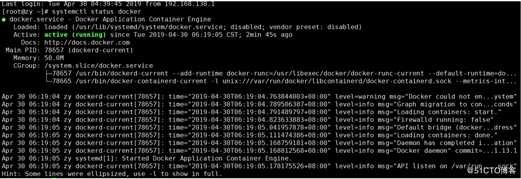
② 下载相应的镜像
[root@zy ~]# docker pull registry.access.redhat.com/rhel7/pod-infrastructure:latest不出意外会报错:
这是因为:
/etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt: no such file or directory
此时我们下载相应的rpm包:
[root@zy ~]#wget http://mirror.centos.org/centos/7/os/x86_64/Packages/python-rhsm-certificates-1.19.10-1.el7_4.x86_64.rpm
[root@zy ~]#rpm -ivh python-rhsm-certificates-1.19.10-1.el7_4.x86_64.rpm然后执行以下命令:
[root@zy ~]#rpm2cpio python-rhsm-certificates-1.19.10-1.el7_4.x86_64.rpm | cpio -iv --to-stdout ./etc/rhsm/ca/redhat-uep.pem | tee /etc/rhsm/ca/redhat-uep.pem此时/etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt文件中就会有内容,再次下载镜像即可。
当在创建deployment时,用的apiVersion时:使用的是apps / v1beta1发现报错:
原因:应用程序API组将是v1部署类型所在的位置。 apps / v1beta1版本已在1.6.0中添加,因此如果您有1.5.x客户端或服务器,则仍应使用extensions / v1beta1版本。
查看kubernetes的版本:
[root@zy yaml_file]# kubelet –version
解决:apiVersion:extensions / v1beta1 即可
#下载相应的镜像:
[root@zy yaml_file]# docker pull docker.io/forestgun007/heapster_grafana:v3.1.1
[root@zy yaml_file]# docker pull docker.io/sailsxu/heapster_influxdb:v0.6
[root@zy yaml_file]# docker pull docker.io/mxpan/heapster:canary编写相应的yaml文件:
#grafana-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
volumes:
- name: grafana-storage
emptyDir: {}
containers:
- name: grafana
image: docker.io/forestgun007/heapster_grafana:v3.1.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GRAFANA_PORT
value: "3000"
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /#grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
kubernetes.io/cluster-service: ‘true‘
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
type: NodePort
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana#influxdb-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: monitoring-influxdb
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: influxdb
spec:
volumes:
- name: influxdb-storage
emptyDir: {}
containers:
- name: influxdb
image: docker.io/sailsxu/heapster_influxdb:v0.6
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /data
name: influxdb-storage#influxdb-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
kubernetes.io/cluster-service: ‘true‘
kubernetes.io/name: monitoring-influxdb
name: monitoring-influxdb
namespace: kube-system
spec:
# type: NodePort
ports:
- name: api
port: 8086
targetPort: 8086
selector:
k8s-app: influxdb#heapster-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: heapster
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
version: v6
spec:
containers:
- name: heapster
image: docker.io/mxpan/heapster:canary
imagePullPolicy: IfNotPresent
command:
- /heapster
- --source=kubernetes:https://kubernetes.default
- --sink=influxdb:influxdb:http://monitoring-influxdb.kube-system.svc:8086#heapster-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
kubernetes.io/cluster-service: ‘true‘
kubernetes.io/name: Heapster
name: heapster
namespace: kube-system
spec:
ports:
- port: 80
targetPort: 8082
selector:
k8s-app: heapster最后将这六个文件移动到一个目录下,比如:heapster
[root@zy ~]# kubectl create -f heapster #创建标签:grafana Fix replicat apple 定时任务 进程 sts 定向 item
原文地址:https://blog.51cto.com/14048416/2396850