标签:摘要 自然语言 space 最优二叉树 词向量 man 自然语言处理 lsa bow
??使用索引的方式无法表达词之间的相似性,n元模型在很多场合难以取得明显的进步和表现
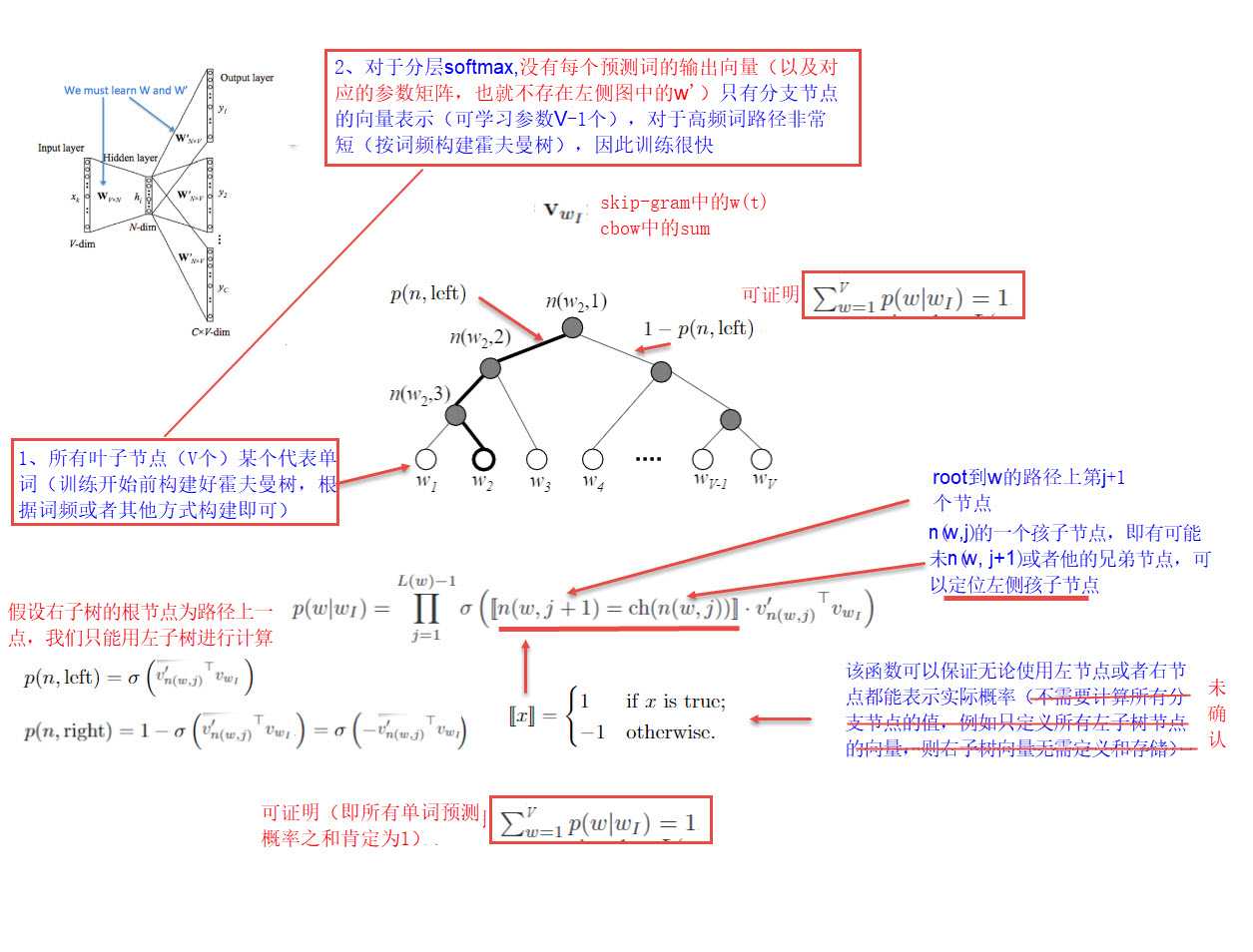
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)
设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
负采样
阅读摘要:
阅读摘要:
标签:摘要 自然语言 space 最优二叉树 词向量 man 自然语言处理 lsa bow
原文地址:https://www.cnblogs.com/xingzhelin/p/10915562.html