标签:关键字 函数 数据对象 base64 默认 sel lookup wpa 结果
Wesnoth之战是一款开源的回合制策略游戏。游戏世界很丰富,有几个派系,地图和数百个可用单位。在本教程中,您将学习如何将中等大小的数据集(如游戏元数据)转换为有用的格式,以便使用R进行进一步分析。
您将了解整洁数据集遵循的关键原则,为什么跟踪它们有用,以及如何清理您给出的数据。整理也是了解新数据集的好方法。
最后,在本教程中,您将学习如何编写一个函数,使您的分析看起来更清晰,并允许您以非常可重复的方式在分析中执行重复元素。该功能允许您将最新版本的数据动态加载到灵活的数据方案中,这意味着在添加新数据时,大部分代码不必更改。
![]() ?
?
图片来源:维基百科
将下载将要下载的csv文件,Wesv15.csv大小为50MB。您设置工作目录并将下载的文件复制到那里。
因为它是一个相对较小的数据集,所以您可以一次加载数据。由于本教程大部分使用了该函数tidyverse,因此使用read_csv函数而不是base R函数是一致的read.csv。
与基本函数read.csv相比,使用tidyverse函数的一个好处是数据立即转换为类似于数据帧的tibble文件格式,但有利于随时打印只有可管理的数据子集到屏幕上。
最好先检查加载数据框的尺寸。dim(data)
## [1] 54591 570
哇,570列,这当然很多!查看一些实际数据总是一个好主意。你只需输入就可以做到这一点data,View(data)或者glimpse(data)感受一下。
opti.由于输出很大,因此通常更容易查看数据的子集。您可以使用head(data)或tail(data)直接使用数字索引进行子集,如下所示。知道当有很多列时,View(data)也不适合查看所有列。相反,最好使用utils::View(data)它,打开一个单独的窗口进行查看。虽然您无法过滤和搜索数据,但您至少可以看到它[ 3]。这是关于仅查看数据的大量信息,但在正确的时间使用正确的工具非常重要。
让我们检查前八列变量的前六行条目。
daathbla ... 2 whatcha ...## 5 3 rby no mi ... on onis blue Drakes Drake Ar ... 1 Xplorer
## 6 3 rby no mi ... on of on red red Loyalists White Ma ... 2 Fanjo
有趣的是,第一列是游戏ID,似乎两行对应同一游戏。这是一个需要在以后获取的问题。下一栏是什么?这些是玩家和单位相关的统计数据。数据集非常稀疏,NA许多列中有很多s。在这些列中,列名称表示正在显示的统计信息,并且通常与游戏中招募或杀死的单位相关。
datan_soothsayer <dbl>,###stats.recruits.drake_burner <dbl>,stats.recruits.drake_clasher <dbl>,
###...
每个游戏中的每个玩家只能从所有可用生物的一小部分中招募。因此,大多数其他单元格将为空。
在现实生活中经常出现这种情况,您很快就会到达需要清理数据集的地方,然后才能进行真正有见地的分析。
即使在编写Tidy Data之前,大多数关系数据库工程师都会考虑遵循RDBMS(关系数据库管理系统)中常见的某些规则的最佳实践,例如使用常规表单,这类似于Tidy Data中规定的规则。作为一名有抱负的数据科学家,您可能还不熟悉数据库,这非常好。请记住,整洁的数据是在数据分析过程中遵循某种标准,最终有助于使您的生活更轻松。坚持整洁的标准意味着您的数据得到有效存储,您的代码不太可能需要太多维护。
由于它最终是一项惯例,并非所有数据存储都遵守它。电子表格应用程序通常不会强制执行特定的整洁标准,并且缺少轻松整理数据的工具 。
这些是使数据整洁的三个规则:
独立意味着人们不能以任何方式猜测相邻行的内容。对于我们的数据,这显然是违反的。的条目map,winner并且loser列一个游戏内的重复。相关行意味着数据看起来比人为大,并且可能得出错误的统计结论。它还可能混淆许多机器学习算法。
这里的变量是可以观察到的任何东西。变量通常具有明确定义的数据类型(例如数字或字符),并且强制执行它具有一些好处。例如,集合的date列data是数据类型character,即使所有观察都是日期。将它们转换为正确的日期时间是有益的。这不仅可以节省内存(日期在内部存储为数字),还可以进行日期计算,例如查找最早/最新的游戏。
独立呢?变量的独立性意味着您无法从另一列计算一列。同样,您的数据违反了此原则,例如data$wday可以从data$date列中完全推断出工作日列。
为什么列的独立性如此珍贵?想象一下,你的date专栏会建议游戏发生在星期五,但工作日专栏是说它是星期二。你信任哪一个?只有一个确定的值将在您的设计方案中建立一致性,从而实现数据完整性 [ 2]。
最后,理解变量和值之间的区别很重要,常见的问题是将值作为列。查看下面的非相关数据示例,其中每年在列方向上展开一个表。
[ 2]:数据完整性并不一定意味着所有数据都是正确的,只是没有明显的欠费出现。
想象一下,您希望将每年新玩家的数量存储在如下表格中:
| 2010 | 2011 | 2012 |
|---|---|---|
| 100 | 120 | 140 |
在可视化过程中,您可能希望根据数据年份添加着色。由于值分布在许多列上,因此您必须对着色规则进行硬编码,这非常耗时且容易出错。
也许更成问题的是,值的数量以及列的数量可能会发生变化。
在上面的例子中,非常清楚的是,在某些时候,2013年的价值将会出现。这意味着表格的总体结构将随着时间的推移不一致,这是一种负担。实际上,您和其他人可能必须记住及时更改代码。表结构中的这种更改很可能会导致某些其他代码无法再运行数据。不整洁的数据集更可能是昂贵,困难和繁琐的维护。
如果表格改为:
| 年 | 值 |
|---|---|
| 2010 | 100 |
| 2011 | 120 |
| 2012 | 140 |
然后将新值作为另一个独立观察附加,就像整洁的格式所暗示的那样。
| 年 | 值 |
|---|---|
| 2010 | 100 |
| 2011 | 120 |
| 2012 | 140 |
| 2013 | 180 |
再看看数据。想象一下,游戏的新版本可以为游戏引入更多的单位,派系或特殊角色。当列开始于stats.kills或stats.recruit以游戏期间杀死或招募的单位类型结束时,此问题尤其普遍。任何使用原始数据中的列位置的代码都将受到改变游戏规则的升级的影响。
改变数据的格式是有意义的,这样你就可以找出在这个游戏中招募/杀死了哪些单位,而不是NA在这个游戏中没有所有派系的所有单位的s。在下一节中,您将看到如何使用工具更改数据结构tidyverse。此过程将消除许多NA在数据框中创建混乱的列,减少分析期间的内存消耗,并使您的数据更易于收集,检查,汇总和绘图。
大多数情况下,并非所有数据都适合一个表,并且希望将数据集拆分为许多较小的表。然后这些表通过项目相互关联。分解表的过程也称为数据规范化。在data,有关一个游戏的所有信息被挤压成两行,特别是每个玩家一个。每个游戏的结果更有意义是单行输入。此单行条目可能在其他表中具有可在必要时展开和查询的引用。
但是,让我们从一个小例子开始。
玩家在游戏中招募的单位可以在每个游戏中具有尽可能多的行的表中找到,因为玩家招募不同的单位。
| game_id | player_id | unit_name | num_recruited |
|---|---|---|---|
| 1 | 1 | A | 2 |
| 1 | 1 | B | 2 |
| 1 | 1 | C | 1 |
| 1 | 2 | A | 2 |
| 1 | 2 | B | 4 |
| 2 | 3 | A | 1 |
| 2 | 3 | B | 4 |
| 2 | 4 | A | 1 |
| 2 | 4 | B | 2 |
| 2 | 4 | C | 1 |
| 2 | 4 | D | 1 |
另一方面,包含关于哪个玩家赢得的信息的表是每个游戏单行的表。
| game_id | first_player_wins |
|---|---|
| 1 | 0 |
| 2 | 1 |
没有冗余数据条目或许多NAs,根本无法将数据组合到一个表中。
将大表拆分成许多较小的表可以使数据自由地适应灵活的结构。这些单独的表中的每一个都可以是整洁的并且没有不必要的NA。计算摘要和派生数量将是直截了当的。这些表的唯一条目可以使用特定标识符(也称为主键)在其他表中引用。虽然有时候被认为是使数据整洁的另一个要点,但是连接不同表的内容的这些关系本身就是数据,因此必须存储。
此时您可能想知道将数据分成许多小表是否不方便,因为您希望一次对所有数据进行分析。这最终取决于您想要进行的分析。请注意,您很少事先知道哪些分析对您或您的受众很重要。在单个表的级别上,您可以获得大量洞察力,制定假设并重新组合/混合来自不同表的数据,并使用相对简单的查询来回答新问题。
将数据分析与烹饪艺术进行比较。当然,将面粉,鸡蛋和牛奶以一定的比例混合(如现成的烘焙混合物)会很方便。然而,伟大的厨师分别为他们的食谱储存最好的食材,只在烹饪前不久混合。这可能看起来有点麻烦,但也允许更多的灵活性和更大的实验自由。
使用这三个整洁的原则作为指导,您可以开始考虑哪些表是必要的,以使您的数据集整洁。
一个好的起点是球员。每个游戏都有两个,每个玩家可以玩几个游戏。这表明您创建了一个玩家查找表,也称为桥接表,其中每个玩家都有一个与他或她相关联的唯一编号。作为一点奖励,更“昂贵”的字符类型数据存储为更便宜的数字。您将用于row_number创建玩家ID。您可能会正确地观察到使用该factor函数还会将字符存储为数字,但使用新ID作为直接引用在这方面稍微有点教育。
在以下部分中,您将大量使用管道操作符%>%。它是一个简单的工具,使您的代码更具可读性。
# You create a 接下来,您希望用各自较短的数字索引替换对玩家的所有引用。这样您就可以利用更高效的内存使用量。要做到这一点,你将使用所谓的left join。A left_join将尝试匹配左侧的每个值的匹配以及右侧的新数据帧的所有可能匹配。它不仅匹配第一个值,这就是为什么在player表中包含唯一值非常重要的原因。如果未找到匹配项,则仍保留左表中的条目。这样,原始表中的数据就不会丢失,这就是为什么这种连接操作有时被标记为非过滤连接的原因。
data 数据中还有其他列引用了播放器名称。您也将删除这些名称。
data <-## 10 10 9 10
###...包含5.458e + 04行
请注意,您已覆盖了您的data表。您可能会反对,因为您似乎正在丢失数据。但是,只要您不更改源文件(您永远不应该这样做),您就不会丢失任何内容。保持表的总数很小有很多好处。最好不要在内存中存储许多大型数据对象,因为在极端情况下,这会导致性能问题。另一个原因是你会积累相同数据的副本,其中一些数据陈旧。您可能会意外编写适用于数据副本的代码。当你测试代码时它似乎运行正常,但只是因为你在R环境中仍然有一个正确的对象版本。如果您重新启动会话,并且您将不得不在某个时刻,您的代码可能会突然中断,因为缺少正确的数据。在长时间工作会话之后调试此类代码可能令人沮丧,
如果您覆盖数据,则可以保证转换一致地应用于所有数据。如果您发现自己犯了错误,只需重新启动会话并将其运行到您进行更改的位置即可。每隔一段时间刷新一次会话就是防止系统内存过时的好方法。这将减少不必要的开发工作和头痛。如果您担心将来可能会或可能不会使用的旧代码部分,请使用类似的版本控制系统git。您可以保持代码库没有死代码,同时仍然能够从旧版本中恢复您的精彩创意。这使得从长远来看更容易处理代码。洁净仅次于圣洁。
通常,您希望制作更精确的代码,例如下面的代码。值得注意的是,这样的代码是逐行执行代码的多次迭代的结果,并且验证步骤已经导致期望的结果。通过保持代码库整洁,您可以更自由地进行实验,而不必担心数据会丢失。
让我们删除一些派生日期列,如工作日,月和年。这些列不会立即使用,但可能会导致一致性问题,例如,当不同的日期与同一工作日不对应时。您可以利用该机会强制执行某些正确的列类型。使用该factor函数强制执行分类数据是明智的,因为它在某种程度上简化了某些分析,但也减少了所需的内存量。
data <- d
当您分离出一些玩家数据时,您可以专注于接下来应该构建的表格。有很多重复的元信息可以外包给较小的表。正如每个玩家都是具有某些特征的实体一样,每个游戏都是如此。有一个表包含每个游戏的所有元信息是明智的,因为这减少了原始data集所展示的一些双行冗余。
game_info <
r is the only quantity not redundant in each row
num_players = max(number))
由于game_info它本身已经很整洁,你可以获得一些关于游戏中玩家数量分布的有用信息。
game_inf## 4 5 1
显然,绝大多数游戏都是双人游戏。单人游戏可能是与缺失数据相关的问题,应该进一步调查。显然,有人设法报告了一个5人游戏,但总体数字非常小。此时,您可能会问为是否为地图和播放器颜色等创建查找表是明智的。答案是:这取决于。
坚持完全规范化的数据库纯粹主义者(基本上是应用于关系数据库的整洁数据的概念)会说是。虽然这可能是真的,但您知道每个游戏只有一个地图,因此将地图信息保存为游戏元数据似乎实际上足够了。
通过将地图编码为一个因子,您可以在地图上将地图转换为整数表示。在记忆方面没有真正的实际收益。通过保持原样,您可以减少描述数据所需的表总数,这是一件好事。您将在环境中存储更少的对象,并且值得瞄准这种简单性。
由于双人游戏如此普遍,并且您不会改变基础原始数据,因此您可以让执行决策仅关注双人游戏。他们有一个简化的结构,因为只有一个赢家和一个输家。首先,您找到属于这些游戏的所有游戏ID,然后您编码两个玩家中的哪一个赢得游戏。这样每个双人游戏只占据数据表中的一行,结果是布尔值。这个新变量以后可以作为学习算法的目标。
# Extract the您还可以通过运行summary新的tibble 快速浏览。
summary(:2738.00嗯,有趣。总体而言,似乎第一个玩家比第二个玩家更有可能获胜,这种洞察力在未来的建模中非常有用。
接下来,您可以查看各个球员的排名。玩家的等级是游戏后分配的Elo编号。玩家的Elo是衡量他或她相对于其他玩家的力量以及随时间变化的指标。简单地说,你不希望改变Elo来告诉我们某人是否会赢。每一行中的Elo是游戏后的值。显然,Elo将与胜利相关联,也许只是微弱的。在游戏之后获得数据是一种微妙的数据蠕变形式。在游戏之前,您没有这方面的知识,因此如果您要对该数据进行模型训练,您可能对预测结果的能力过于自信。
作为一个整洁的替代方案,将播放器的所有Elo号码和Elo的录音时间存储在一个表格中是有意义的。然后可以更好地跟踪单个玩家的Elo变化,并且您可以更轻松地强制执行只有最新的已知值用于任何预测。
Elos出现在数据的两个位置,因此您可以使用该bind_rows函数创建组合排名表。游戏结束时玩家的Elo与他或她是否赢得或失去该游戏无关,而Elo表不应分为赢家和输家。
winner_elos## 6 12 1785 2015-11-16 21:06:00
在处理完所有玩家和游戏后,您现在可以尝试捕获特定于每个玩家 - 游戏组合的信息。大多数信息存储在以stats但不是单位统计信息的列中。
player_game_statistics <- data %>%
select(game_id, player_id, color, team,number, faction, leader,
cost = stats.cost,
infliced_expected = stats.inflicted_expected,
bl>,...这些专栏意味着什么?
由于游戏的随机性,存在预期/造成的实际区别。所有攻击都是随机的。无论攻击是否失败,掷骰都会被击中,所造成的伤害也是如此。分析玩家的幸运程度,比如他或她所造成的伤害与游戏期间的预期相比有多大,以及这是否会对游戏的输赢产生可测量的影响,这可能会很有趣。
最后一项重要任务是提取单元数据,该数据负责大多数列。由于单元名称是列名称的一部分,因此可以使用正则表达式来提取名称。
如果您需要复习正则表达式 。它们本质上是一小段代码,允许您从较大的字符串中提取特定的模式。
命名列的结构是‘stats.name_of_statistic.name_of_unit‘,您想要提取‘name_of_statistic‘和‘name_of_unit‘,而无需手动处理500列。该rebus软件包非常便于从较小的部分构造较大的正则表达式,这使得它更容易推理它们。请记住,正则表达式是使用%R%运算符管道而不是标准管道%>%。
statisti ‘stats.‘ %R% # Uninformative identifier
sample_unit”输出的不同列str_match对应于各种捕获的部分。
您必须将数据集从宽格式(其中列对应于值)转换为长格式,其中列表示变量。您可以使用该gather功能执行此操作。使用key,指定由列名组成的新变量的名称,并使用value,指定保存原始值的新变量的名称。
完成后,您可以匹配statistic_pattern新key变量(即原始列名称),以提取单元名称和所描述的统计信息。
# The stothsayer## 6 94 143 1推进了saurian_soothsayer
现在您已经拥有了所有单位的列表,您可以像对玩家和游戏一样创建查找。
unit_lookup ## 6 drake_glider 6
这里的单位信息相当简单。幸运的是, 包括所有单位信息,例如不同地形上的生命值,特殊攻击,抵抗和移动惩罚。当然,所有这些数据最好也存储在整洁的数据中。
该rvest软件包是抓取此信息的理想选择。
既然每个单元都分配了一个ID,那么用统计表中的单元ID替换单元名是有意义的。
player_unit_s
您甚至可以将统计数据拆分为相关类别。
advances_stats
kills_stats <- player_unit_statistics %>%
filte
到目前为止,您通过将数据集分成几个较小的整洁集来清理数据集。这非常麻烦,但它有一个目的。新数据发布后会发生什么?您不希望逐个重新运行所有步骤。或者想象一下,您希望将数据清理流程转移到公司的更大管道中。对于所有这些要求,最好编写一个函数。功能很棒,因为它们将数据与该数据的计算分开。它们允许数据流经您的应用程序并且可维护。
如果您的清洁过程发生变化,但您的功能界面相同,即输入和输出的结构不会改变,那么其他过程将继续工作而无需任何额外的干预。您可以再次重新运行该功能,数据流仍然存在。
要编写函数,您需要将计算包装到函数参数中并考虑输入和输出。编写可以在以后覆盖的默认参数是合理的。这样,您的功能大部分时间都很方便,并且在需要时也很灵活。在这里,您的输入是您导入的数据的路径以及将控制输出的附加参数。主要部分是您已在上面编写的代码片段。
load_statistics,
‘elos‘ = elos,
‘advances_stats‘ = advances_stats,
通过该return_object关键字,您可以控制是否将表作为列表对象返回,其中每个元素对应一个表,或者表是否单独加载到R环境中。后者当然很方便,但也很混乱。此外,您可能会覆盖环境中的其他对象,这是一种不必要的副作用。如果将该函数保存为脚本(例如,调用)tidy_function.R,则可以简单地获取文件并将数据加载到一行中。
# Import the f## 5 5 9 10 1
## 6 6 11 12 0
您还可以将数据直接加载到R环境中。
load_wesno## 5 5 9 10 1
## 6 6 11 12 0
您也可以将其打包到您自己的R包中,而不是从脚本加载函数,这些包可以轻松地与其他人共享。
恭喜,您现在拥有易于加载和准备分析状态的数据。
什么比清理数据更有趣?分析吧!您可以开始回答有关数据的一些简单问题。哪个玩家玩过最多的游戏?
player_g玩家player_id == 3玩的游戏最多。他的胜率是多少?
win_first## 1 391 609
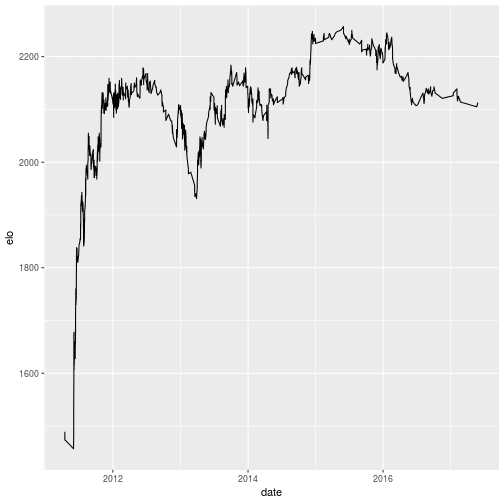
总赢率(总计所有比赛赢得球员1和球员2并除以比赛总数:(437 + 391)/(618 + 609)= 0.6748166,确实是一个非常稳定的球员。那个球员的Elo怎么样随着时间的推移而变化?
elos %>% lo)) +
geom_line()
![]() ?
?
他的Elo在半年的时间内迅速上升,然后或多或少地平稳,偶尔出现高峰和低谷。从2015年开始,它似乎略有下降。
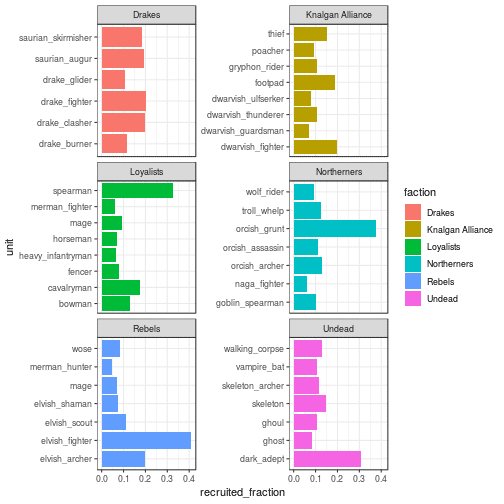
另一个非常有趣的事情是军队的平均构成。竞争性球员招募哪些单位?
player_game_statistics %>%
select(game_id, player_id, faction) %>%
intncol = 2, scales = ‘free_y‘)+
coord_flip() +
theme_bw()
![]() ?
?
你看到一些明确的偏好。例如,有些单位在某些派系中被高度招募,例如长枪兵,兽人咕噜声,精灵战士或黑暗擅长者。这些都是好的主要单位,不应该在任何军队中失踪。然而,Knalgan联盟和德雷克斯阵营似乎要求所有来自其招募池的单位发挥最有效率。可能存在针对特定阵营比赛或地图的子策略,您可以进一步调查!
您学会了构建数据以进行分析。如果您的数据不是很整洁,大部分时间都是如此,那么您就知道需要做些什么来清理它。在清理过程中,您将查看表格并运行简单的摘要以了解数据。通过这种方式,您可以更加密切地了解您的数据,并且您将更快地增加您作为数据分析师或数据科学家的角色的价值。
当数据整洁时,您可以通过检查来可视化数据。在这里,您经常可以获得有关测试的新假设的第一个想法,或者在数据集中设计工程的功能,这些都是良好数据模型的先决条件。通过保持数据和代码整洁,您可以更轻松地让其他人使用您的数据并分析您的代码。
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?QQ:3025393450
?QQ:3025393450

![]() ?
?
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询服务
![]() ?
?
标签:关键字 函数 数据对象 base64 默认 sel lookup wpa 结果
原文地址:https://www.cnblogs.com/tecdat/p/10919455.html

