标签:选择 root pat ttext eof 需要 path 偏移量 强制
摘要:这几天遇到个需要,需要提供用户下载电子证照,文件格式为OFD,一上网查瞬间懵了,几乎没有相关的,Google上也没有(咱们国家的国标文件没有相关资料也正常),时间紧,选择最简单的方法来实现,我将需要生成的文件用word做了一份模板,利用网页工具转成OFD文件,这个网站非常良心,不干coder blackmail coder的事儿,这
是地址http://www.yozodcs.com/page/example.html(因为OFD文件没有专业软件帮助几乎很难代码实现),(用7Z工具解压ofd文件,压缩使用WinZip,压缩的时候不能带根路径)得到文件目录结构如下:
首先我们来看OFD文件的目录结构,有助于我们用代码操作:
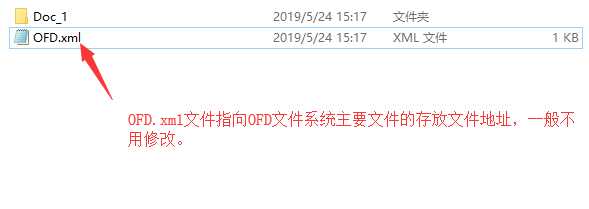
Doc_1文件夹下面是主要内容
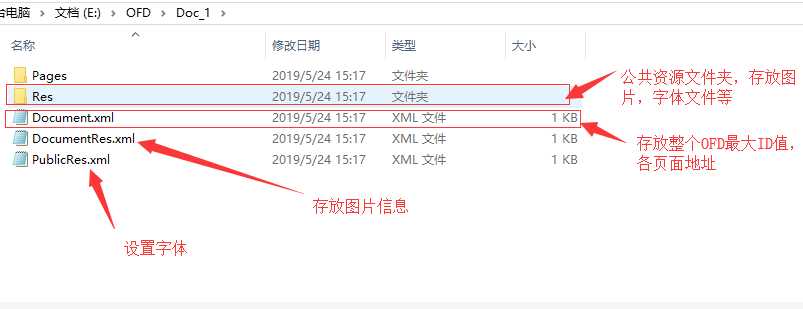
Pages下面存放OFD每个页面
下面简单说明Pages下面页面信息XML文件的标签及属性作用
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <ofd:Page xmlns:ofd="http://www.ofdspec.org/2016"> <ofd:Area> <ofd:PhysicalBox>0 0 209.90291 296.68628</ofd:PhysicalBox> <ofd:ApplicationBox>0 0 209.90291 296.68628</ofd:ApplicationBox> <ofd:ContentBox>0 0 209.90291 296.68628</ofd:ContentBox> </ofd:Area> <ofd:Content> <ofd:Layer ID="0"> <ofd:ImageObject ID="7" ResourceID="6" Boundary="0 -0.3528 210.2557 297.0391" CTM="210.2557 0 0 297.0391 0 0"/> <ofd:TextObject ID="9" Font="8" Size="7.761115550994873" Boundary="47.2723 67.0278 261.0557 15.5222"> <ofd:CGTransform CodePosition="0" CodeCount="17" GlyphCount="17"> <ofd:Glyphs>11738 12862 7255 17457 12235 14764 13842 11859 12078 11931 15952 14729 11465 7256 11113 11465 13610</ofd:Glyphs> </ofd:CGTransform> <ofd:TextCode X="0.0" Y="7.7611" DeltaX="7.7611 7.4083 7.4083 7.7611 7.7611 7.7611 7.7611 7.7611 7.7611 7.7611 7.7611 7.7611 8.1139 7.0556 7.7611 7.7611">填充字符填充字符填充字符填充字符填</ofd:TextCode> </ofd:TextObject> </ofd:Layer> </ofd:Content> </ofd:Page>
ofd:CGTransform:标签内的内容,为网站生成模板内,Res文件夹下的字体文件内的检索码,这里重点说明,我们通过网站得到的模板文件,在res文件加下面存放的字体文件只包含你OFD文件内存在的文字,所以你会发现这个字体文件特别小,你需要到你电脑的C:\Windows\Fonts下面找到你需要的字体文件,或者自己准备也行,这样可以保证OFD文件在各种环境下查看,打印字体的统一!!!然后在PublicRes.xml文件内设置你自己准备的字体,(自己准备的字体需要放到Res文件夹下面),ofd:CGTransform标签内存在内容(字符码),则去字体文件内寻找匹配的文字,没有则显示ofd:TextCode标签内的内容。这我选择使用ofd:TextCode显示内容,ofd:CGTransform标签则全部删掉。
字体文件设置文件 PublicRes.xml 如下
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <ofd:Res BaseLoc="Res" xmlns:ofd="http://www.ofdspec.org/2016"> <ofd:Fonts> <ofd:Font ID="" FontName="CBMOWR+STKaiti" FamilyName="CBMOWR+STKaiti"> <ofd:FontFile>font_1.otf</ofd:FontFile> </ofd:Font> <ofd:Font ID="8" FontName="STKaiti" FamilyName="STKaiti"> <FontFile>font.TTF</FontFile> </ofd:Font> </ofd:Fonts> </ofd:Res>
注意 ofd:Font 标签内的ID属性,页面信息XML文件内 ofd:TextObject 标签的font属性和此处的id一致即可引用字体。至于ofd:Font标签内的FontName属性则需要填入字体正确
的头文件信息内的名称.
重点说明标签 ofd:TextObject,这也是OFD文件为何如此DT的地方:
ofd:TextObject 标签下的 Boundary 属性:将ofd:TextObject看作一个box,前两个值分别为定位点的坐标,后两个值为X轴和Y轴相对与该定位点的偏移量,由此在页面上确定该box的位置,
也因为该属性,ofd:TextObject标签显示内容位置与XML文件内的顺序无关
ofd:TextCode 标签下的 DeltaX 属性:为字符X轴偏移量,第一个值为ofd:TextCode标签内第一个字符和第二个字符的偏移量,有n个字符就有n-1个偏移量,多个用空格隔开,如果你显示的内容
可能存在折行,你需要在模板文件内将显示内容填充满,通过上一层ofd:TextObject标签的Boundary属性的第二个值获取折行Y轴偏移量,折行内容还放不下,你需要调整 Size 属性来
调整字体大小,(这里建议再弄一份小字体文件再需要缩小字体的时候设置对应的Size,DeltaX属性),显示的内容有10个,偏移量最少得设置9个,如果显示内容字符数-偏移量数 > 1,
则会发生字符重叠现象;
现在有了模板文件,知道了基本的属性作用,我使用dom4j来操作xml文件,上代码-->
package code; import java.awt.Font; import java.awt.FontFormatException; import java.io.File; import java.io.FileInputStream; import java.io.FileWriter; import java.io.IOException; import java.io.ObjectInputStream.GetField; import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.poi.xslf.model.geom.Path; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.DocumentHelper; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.XPath; import org.dom4j.io.OutputFormat; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; import util.OprationFile; import util.ZipUtil; public class CreateElectronicCertification { //ofd文件迭代id,不能重复,数据折行新增节点设置id private static int index; public static void main(String[] args) throws DocumentException, IOException { Map<String, Object> map = new HashMap<String, Object>(); generateOFD(map); //OprationFile.deleteFiles(new File(newOFDFileSys));//删除生成的文件。这里自己操作参数,备份好文件,删除不可恢复, } public static boolean generateOFD(Map<String,Object> map) throws IOException, DocumentException{ //ofd文件模板文件夹位置 String resourcesAddress = "E:/OFD_model";//map.get("resourcesAddress"); //不折行最大字符长度 int lineWide = 19;//map.get("lineWide"); //强制换行符 String lineBreak = "/r";//map.get("lineBreak"); //折行Y轴偏移量 double Y_offset = 7.7611;//map.get("Y_offset"); //生成OFD文件存放文件夹 String OFDAddress = "E:/";//map.get("OFDAddress"); String modelForIDFileAddress = "/Doc_1/Document.xml";//map.get("modelForIDFileAddress"); //String newFileName = Common.createGUID(); String newFileName = "OFD";//随机OFD文件名 String maxIdAndPagesFile = modelForIDFileAddress;//OFD模板存放MaxID,pageAddress地址的Document位置 String newOFDFileSys = copyModelFileSys(newFileName,resourcesAddress);//拷贝模板文件,返回新文件路径 if(newOFDFileSys.equals("0")){ return false; } getMaxId(newOFDFileSys+maxIdAndPagesFile); //获取页面xml文件的地址 List<String> pageAddressList = getPagesAddress(newOFDFileSys+maxIdAndPagesFile); for(String pageAddress: pageAddressList){ pageAddress = newOFDFileSys+"/Doc_1/"+pageAddress; oprationXmlForDom4j(pageAddress, map, lineBreak, lineWide, Y_offset); } String OFDName = newFileName+".ofd"; //电子签章,二维码等图片在此覆盖模板内图片 //save(String str); //去根目录压缩(OFD文件压缩不能带根目录) ZipUtil.doCompress(newOFDFileSys, OFDAddress+OFDName,newFileName); return true; } //获取page页面存放地址 public static List<String> getPagesAddress(String maxIdAndPagesFile) throws DocumentException{ SAXReader reader = new SAXReader(); Document document = reader.read(new File(maxIdAndPagesFile)); List<Element> list =document.selectNodes("//ofd:Page");//XPath List<String> pageAddressList = new ArrayList<String>(); for(Element elment:list){ pageAddressList.add(elment.attributeValue("BaseLoc")); } pageAddressList.remove(0); return pageAddressList; } public static String copyModelFileSys(String newFileName,String resourcesAddress) throws IOException{ String oldFileName = new File(resourcesAddress).getName(); String newOFDFileSys = resourcesAddress.replaceAll(oldFileName, newFileName); if(OprationFile.copyDir(resourcesAddress, newOFDFileSys)){ return newOFDFileSys; } return "0"; } //获取最大id,OFD文件,XML内的ID属性类似前端页面的元素id,不可重复,这里取最大的在有新增节点时设置id用 public static void getMaxId(String address) throws DocumentException{ SAXReader reader = new SAXReader(); Document document = reader.read(new File(address)); @SuppressWarnings("unchecked") List<Node>list=document.selectNodes("//ofd:MaxUnitID"); index = Integer.parseInt(list.get(0).getText())+1; } public static void oprationXmlForDom4j(String fileAddress,Map<String, Object> map,String lineBreak,int lineWide,double Y_offset) throws DocumentException, IOException { File file = new File(fileAddress); SAXReader reader = new SAXReader(); Document document = reader.read(file); Element root = document.getRootElement(); Element layerElement = root.element("Content").element("Layer"); Iterator iterator = document.selectNodes("//ofd:TextObject").iterator(); List<Element> foldLineLsit = new ArrayList<Element>(); while (iterator.hasNext()) { Element textObjectElement = (Element) iterator.next(); for(String key : map.keySet()){ if((textObjectElement.element("TextCode").getText()).equals(key)){ if(key.equals("fj")){ lineWide = 27;//附记页最大行长度 } //-------------------------------------- System.out.println("匹配参数:"+textObjectElement.element("TextCode").getText()); List<String> paramList = new ArrayList<String>(); String boundary= textObjectElement.attributeValue("Boundary"); String[] b_split = boundary.split(" "); String boundaryStr = ""; Double at_Y_offset = Double.parseDouble(b_split[1]); String params = ((String)map.get(key)).trim(); String[] paramGroup = params.split(lineBreak); //自动折行 for(int i = 0 ; i<paramGroup.length ; i++){ if(paramGroup[i].length()>lineWide){ int flag = 0; int g_len = (paramGroup[i].length()+lineWide-1)/lineWide; for(int li = 0;li<g_len;li++){ if(li+1 == g_len){ paramList.add(paramGroup[i].substring(flag,paramGroup[i].length())); }else{ paramList.add((paramGroup[i].substring(flag,flag+lineWide))); } flag+=lineWide; } }else{ paramList.add(paramGroup[i]); } } //配置Y轴偏移量,首行直接替换参数,折行依次添加节点() for(int i = 0; i < paramList.size(); i++){ String param = paramList.get(i); if(i==0){ Element atElem = textObjectElement.element("TextCode"); atElem.setText(param); }else{ at_Y_offset = Double.parseDouble(String.format("%.4f", at_Y_offset+Y_offset)); boundaryStr = b_split[0]+" "+ at_Y_offset + " " + b_split[2]+ " "+b_split[3]; //setParam(textObjectElement,param,boundaryStr); Element newElement = (Element) textObjectElement.clone();//此处必须使用clone()方法,底层调用Object的clone(); Element elem = newElement.element("TextCode"); //第三页模板平均折行Y轴偏移量7.7611,Boundary第三,四个参数可忽略不设置,文件解析根据DeltaX偏移量自动布局Boundary宽度,高度为定植不用修改 index = index+1; elem.setText(param); newElement.attribute("ID").setValue(index+""); newElement.attribute("Boundary").setValue(boundaryStr.trim()); foldLineLsit.add(newElement); } } } } } if(foldLineLsit.size()>0){ for(Element e : foldLineLsit){ layerElement.add((Element)e.clone()); } } save(document, fileAddress); foldLineLsit.clear(); } public static void save(Document doc, String address) throws IOException { OutputFormat format = OutputFormat.createPrettyPrint(); format.setEncoding("UTF-8"); File file=new File(address); file.getParentFile().mkdirs(); XMLWriter writer = new XMLWriter(new FileWriter(file), format); writer.write(doc); writer.close(); } }
工具类
package util; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.util.Scanner; public class OprationFile { @SuppressWarnings("static-access") public static boolean copyDir(String sourcePath, String newPath) throws IOException { File file = new File(sourcePath); String[] filePath = file.list(); if (!(new File(newPath)).exists()) { (new File(newPath)).mkdir(); } for (int i = 0; i < filePath.length; i++) { if ((new File(sourcePath + file.separator + filePath[i])) .isDirectory()) { copyDir(sourcePath + file.separator + filePath[i], newPath + file.separator + filePath[i]); } if (new File(sourcePath + file.separator + filePath[i]).isFile()) { copyFile(sourcePath + file.separator + filePath[i], newPath + file.separator + filePath[i]); } } return true; } public static void copyFile(String oldPath, String newPath) throws IOException { File oldFile = new File(oldPath); File file = new File(newPath); FileInputStream in = new FileInputStream(oldFile); FileOutputStream out = new FileOutputStream(file);; byte[] buffer=new byte[2097152]; int readByte = 0; while((readByte = in.read(buffer)) != -1){ out.write(buffer, 0, readByte); } in.close(); out.close(); } public static void deleteFiles(File file){ if (file.isDirectory()) { File[] files=file.listFiles(); for (int i = 0; i < files.length; i++) { if (files[i].isDirectory()) { deleteFiles(files[i]); }else { files[i].delete(); } } } file.delete(); } public static void main(String[] args) throws IOException { Scanner sc = new Scanner(System.in); String filePath = sc.nextLine(); deleteFiles(new File(filePath)); } }
下面这个方法来自https://www.cnblogs.com/yzuzhang/p/4763606.html大佬的分享,建议自己写,重载太多不方便传参,这里需要重点说明,OFD文件压缩采用ZIP,一定注意不能有根目录,以我的为例,直接将Doc_1文件夹和OFD.xml文件压缩,用电脑操作也是一样,
package util; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.util.zip.ZipEntry; import java.util.zip.ZipOutputStream; public class ZipUtil { private ZipUtil() { } public static void doCompress(String srcFile, String zipFile,String rootdDirectory) throws IOException { doCompress(new File(srcFile), new File(zipFile),rootdDirectory); } /** * 文件压缩 * * @param srcFile * 目录或者单个文件 * @param zipFile * 压缩后的ZIP文件 */ public static void doCompress(File srcFile, File zipFile,String rootdDirectory) throws IOException { ZipOutputStream out = null; try { out = new ZipOutputStream(new FileOutputStream(zipFile)); doCompress(srcFile, out,rootdDirectory); } catch (Exception e) { throw e; } finally { out.close();// 记得关闭资源 } } public static void doCompress(File file, ZipOutputStream out,String rootdDirectory) throws IOException { doCompress(file, out, "",rootdDirectory); } public static void doCompress(File inFile, ZipOutputStream out, String dir,String rootdDirectory) throws IOException { if (inFile.isDirectory()) { File[] files = inFile.listFiles(); if (files != null && files.length > 0) { for (File file : files) { String name = inFile.getName(); if (!"".equals(dir)) { name = dir + "/" + name; } ZipUtil.doCompress(file, out, name,rootdDirectory); } } } else {
//将根目录干掉,否则无法打开OFD文件 dir = dir.replaceAll(rootdDirectory, ""); ZipUtil.doZip(inFile, out, dir); } } public static void doZip(File inFile, ZipOutputStream out, String dir) throws IOException { String entryName = null; if (!"".equals(dir)) { entryName = dir + "/" + inFile.getName(); } else { entryName = inFile.getName(); } ZipEntry entry = new ZipEntry(entryName); out.putNextEntry(entry); int len = 0; byte[] buffer = new byte[1024]; FileInputStream fis = new FileInputStream(inFile); while ((len = fis.read(buffer)) > 0) { out.write(buffer, 0, len); out.flush(); } out.closeEntry(); fis.close(); } public static void main(String[] args) throws IOException { String rootdDirectory = "OFD"; doCompress("E:/OFD/", "E:/OFD.ofd",rootdDirectory); } }
没了。。。
标签:选择 root pat ttext eof 需要 path 偏移量 强制
原文地址:https://www.cnblogs.com/fengqiyuanLK/p/10919544.html