标签:append pos long data spi 参数 rom 信息 没有
最近在学习数据分析的相关知识,打算找一份数据做训练,于是就打算用Python爬取链家在重庆地区的二手房数据。
链家的页面如下:
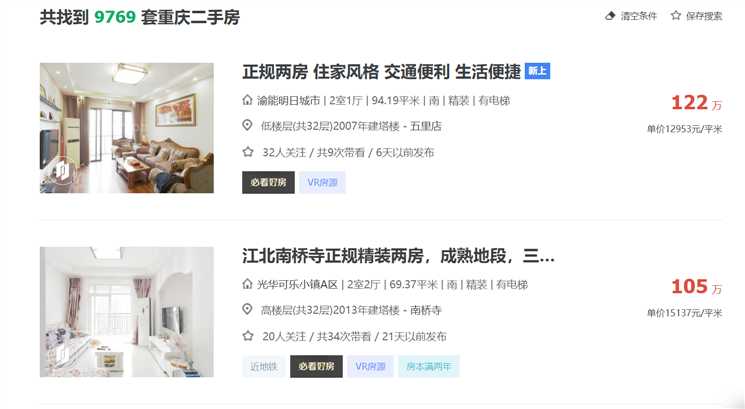
爬取代码如下:
import requests, json, time from bs4 import BeautifulSoup import re, csv def parse_one_page(url): headers={ ‘user-agent‘:‘Mozilla/5.0‘ } r = requests.get(url, headers=headers) soup = BeautifulSoup(r.text, ‘lxml‘) results = soup.find_all(class_="clear LOGCLICKDATA") for item in results: output = [] # 从url中获得区域 output.append(url.split(‘/‘)[-3]) # 获得户型、面积、朝向等信息,有无电梯的信息可能会有缺失,数据清理可以很方便的处理 info1 = item.find(‘div‘, ‘houseInfo‘).text.replace(‘ ‘, ‘‘).split(‘|‘) for t in info1: output.append(t) # 获得总价 output.append(item.find(‘div‘, ‘totalPrice‘).text) # 获得年份信息,如果没有就为空值 info2 = item.find(‘div‘, ‘positionInfo‘).text.replace(‘ ‘, ‘‘) if info2.find(‘年‘) != -1: pos = info2.find(‘年‘) output.append(info2[pos-4:pos]) else: output.append(‘ ‘) # 获得单价 output.append(item.find(‘div‘, ‘unitPrice‘).text) #print(output) write_to_file(output) def write_to_file(content): # 参数newline保证输出到csv后没有空行 with open(‘data.csv‘, ‘a‘, newline=‘‘) as csvfile: writer = csv.writer(csvfile) #writer.writerow([‘Region‘, ‘Garden‘, ‘Layout‘, ‘Area‘, ‘Direction‘, ‘Renovation‘, ‘Elevator‘, ‘Price‘, ‘Year‘, ‘PerPrice‘]) writer.writerow(content) def main(offset): regions = [‘jiangbei‘, ‘yubei‘, ‘nanan‘, ‘banan‘, ‘shapingba‘, ‘jiulongpo‘, ‘yuzhong‘, ‘dadukou‘, ‘jiangjing‘, ‘fuling‘, ‘wanzhou‘, ‘hechuang‘, ‘bishan‘, ‘changshou1‘, ‘tongliang‘, ‘beibei‘] for region in regions: for i in range(1, offset): url = ‘https://cq.lianjia.com/ershoufang/‘ + region + ‘/pg‘+ str(i) + ‘/‘ html = parse_one_page(url) time.sleep(1)
print(‘{} has been writen.‘.format(region))
main(101)
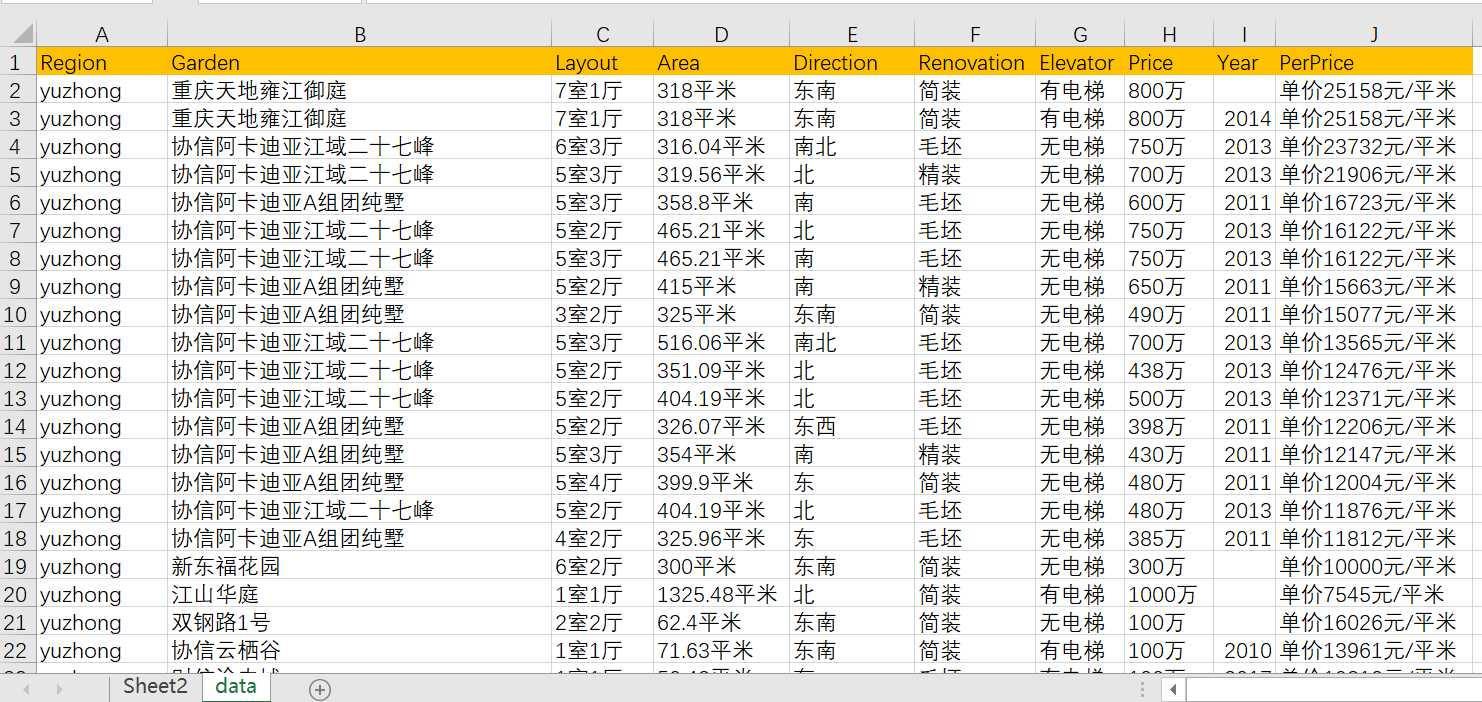
链家网站的数据最多只显示100页,所以这里我们爬取各个区域的前100页信息,有的可能没有100页,但并不影响,爬取结果如下(已经对数据做了一点处理,有问题的数据出现在有无电梯那一列和小区名那一列,只要排个序然后整体移动单元内容即可,年份缺失后面再做处理):
接下来,我们用Excel的数据透视表简单看一下数据的数量信息:
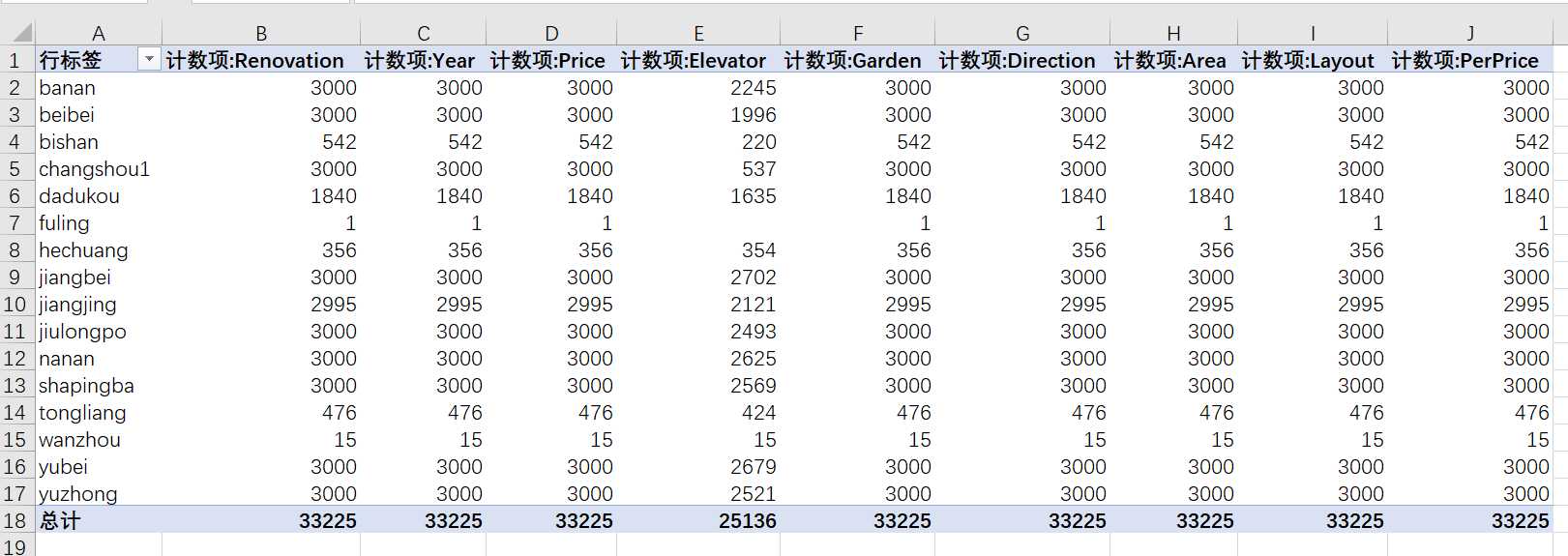
从表中我们可以看到,此次共爬取了33225条数据,Elevator这一项有很多数据缺失,Year这一项由于在爬虫时使用空格代替了空值,所以这一项也存在一些数据缺失。现在有了数据,后面就可以开始对这些数据进行分析了。
参考书籍:
[1] https://germey.gitbooks.io/python3webspider/content/
标签:append pos long data spi 参数 rom 信息 没有
原文地址:https://www.cnblogs.com/yunxiaofei/p/10946951.html