标签:ble 情况 垃圾收集 模型 自动分配 基本数据类型 开发人员 根据 功能
GC简单的了解
GC:Garbage Collection 字面意思是垃圾回收器,释放垃圾占用的内存空间。让创建的对象不需要像c、c++那样delete、free掉。对于c、c++的开发人员分配的,也就是说还要对内存进行维护和释放。对于java程序员来说,一个对象的内存分配是在虚拟机的自动分配机制的帮助下,不再需要为每一个new操作去写配对的delete/free代码,而且不容易出现内存泄漏和内存溢出的问题,但是,如果出现了内存泄漏和内存溢出问题,而开发者又不了解虚拟机怎么分配内存的话,那么定位错误和排除错误将是一件很痛苦的事。
jvm内存管理结构,如图
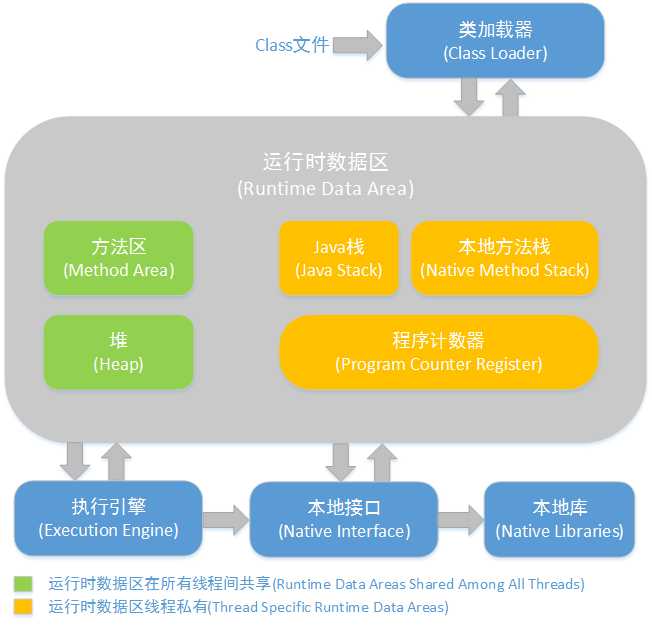
JVM运行时数据区
-XX:MaxMetaspaceSize=128m 设置最大的元内存空间128兆
对象被判定为垃圾的标准
1、没有被其他对象引用
判定对象是否为垃圾的算法
1、引用计数算法
判断对象的引用数量
1)、通过判断对象的引用数量来决定对象是否可以被回收
2)、每个对象实例都有一个引用计数器,被引用则+1,完成引用-1
3)、任何引用数为0的对象实例可以被当做垃圾收集
优点:执行效率高,程序执行受影响较小
缺点:无法检测出循环引用的情况,导致内存泄漏
2、可达性分析算法
通过判断对象的引用链是否可达来决定对象是否可以被回收
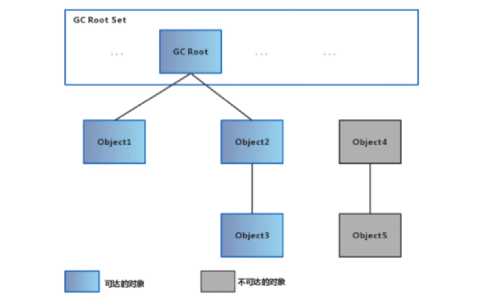
可以作为GC ROOT的对象:
1)、虚拟机栈中引用的对象(栈帧中的本地变量表)
2)、方法区中的常量引用的对象
3)、方法区中的类静态属性引用的对象
4)、本地方法栈中JNI(native方法)的引用对象
5)、活跃线程的引用对象
垃圾回收算法
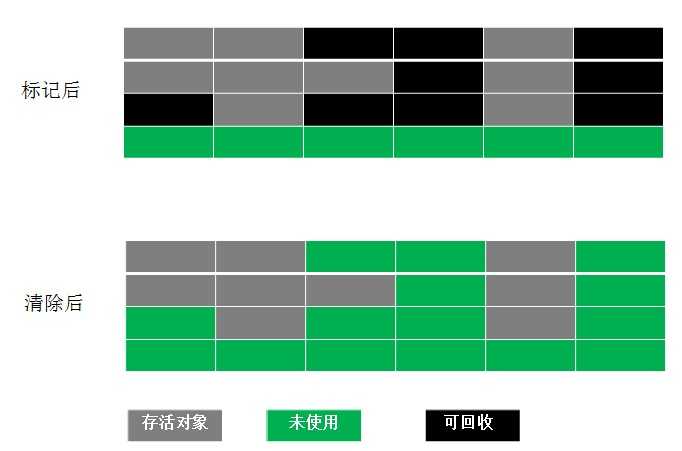
1、标记-清除算法
最基础的收集算法,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统计回收所有被被标记的对象。
缺点:
2、复制算法
为了解决效率问题,一种称为“复制”(Copying)的收集算法出现了,它将可用的内存按容量划分为大小相等的两块,每次只使用其中的一块,当这块内存用完了,就将还存活着的对象复制到另一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,未免太高了一点。新生代GC算法采用的就是这种算法。Hotspot虚拟机默认为Eden和Survivor的比例是8:1:1。
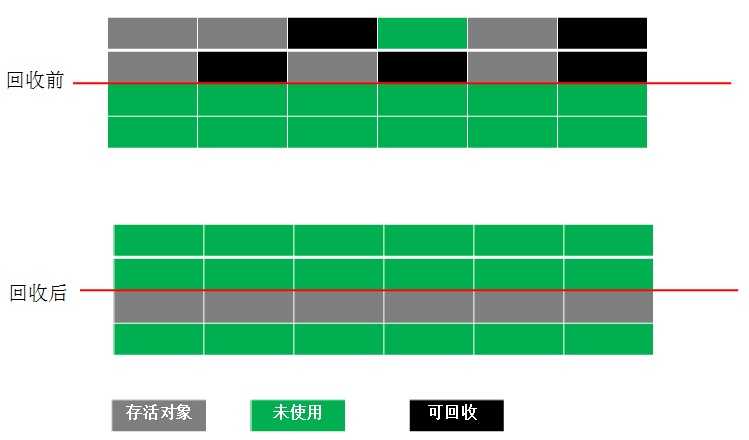
3、标记-整理算法
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接使用这种算法。
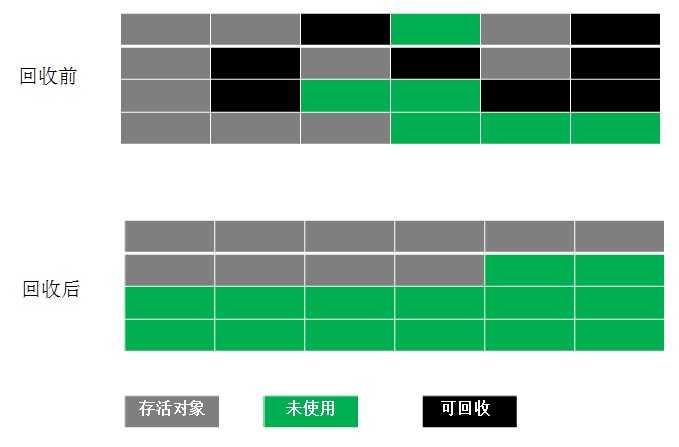
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存,“标记-整理”算法如图
4、分代收集算法
当前商业虚拟机的垃圾收集都采用“分代收集”算法,这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块,一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高,没有额外空间对它进行分配担保,就必须使用“标记-清理”或者“标记-整理”算法来进行回收。
标签:ble 情况 垃圾收集 模型 自动分配 基本数据类型 开发人员 根据 功能
原文地址:https://www.cnblogs.com/dasha/p/10889480.html