标签:独立 复杂 length 要求 而不是 hello solution else 怎么
这个leetcode题目是这样的:
这个数组的特点是会形成一个山峰,而题目要求返回这个山峰的索引。
如果按题意来想,很快就想到一个解决办法:把a[i]跟a[i+1]作比较,如果a[i+1]比a[i]小了,那就是到山峰了,返回i即可。这个算法需要遍历数组,一直找到开始变小的情况。
对于这个算法,可以这样实现(因为山峰一定不会在最后出现,所以不必担心A[i+1]会越界):
int peakIndexInMountainArray(int* A, int ASize) {
int i;
for (i = 0; i < ASize; i ++) {
if (A[i] > A[i+1]) {
break;
}
}
return i;
}
把这个实现提交到leetcode,反馈是这样的:
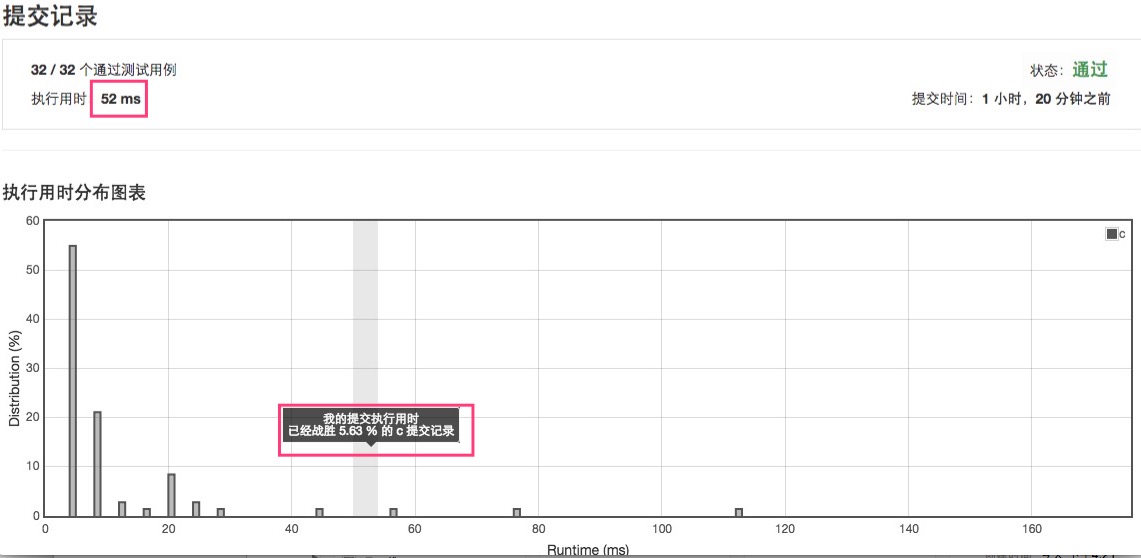
从反馈来看,这并不是一个速度很快的算法设计,但这不代表它不可行,实际上,很多情况,我们宁愿简单一点的实现也不要复杂但性能很佳的设计,因为有时简单就是最重要的。但是,这里的训练就是要追求更好的设计,而不是考虑实际情况。
小程之前已经提过:一般自然的想法,都不是高效的算法设计。
所以,除了理解题意外,还需要有独立的时间来进行算法设计(而不是简单地按着题意来解答),这对于其它场景也是一样,使用什么套路,有时候是很关键的。
另外,高效是相对的,检测是不是高效有两个办法,一个办法是运行起来看执行速度,一般需要对比其它解决办法,另一个办法是分析时间复杂度,这两个都不是小程重点讲解的内容,读者不应该陷入时间复杂度的分析当中,而应该把时间放在经典的算法套路的理解上。
对于这个题目,如果换一个角度,那实际就是求最大值的索引,依然可以套用小程之前反复提到的“分治”与“重用”的套路。
假如一开始就决定使用分治与重用的套路,那思考的过程可能是这样的:
1. 这里的分治,只需要简单的分,从中间一分为二即可。
2. 然后就是重用,也就是标准作业,就是自己,即返回最大值的索引。整体的思路是这样的:把数列分为两部分,然后重用自己,求得两部分的最大值的索引,然后对这两个索引对应的值再比较一次,最终返回整体的最大值的索引。
分到什么时候结束呢?分到只有一个元素时结束,或者,在程序实现时再考虑都可以。在算法设计上,可以不考虑细节。
这个算法的实现是这样的:
int maxindex(int* A, int b, int e) {
if (b < e) {
int m = (b+e)>>1;
int l = maxindex(A, b, m);
int r = maxindex(A, m+1, e);
int ret = l;
if (A[l] < A[r]) {
ret = r;
}
return ret;
}
return b;
}
int peakIndexInMountainArray(int* A, int ASize) {
return maxindex(A, 0, ASize-1);
}
把这个代码提交到leetcode,反馈如下(可见速度大幅提升了):
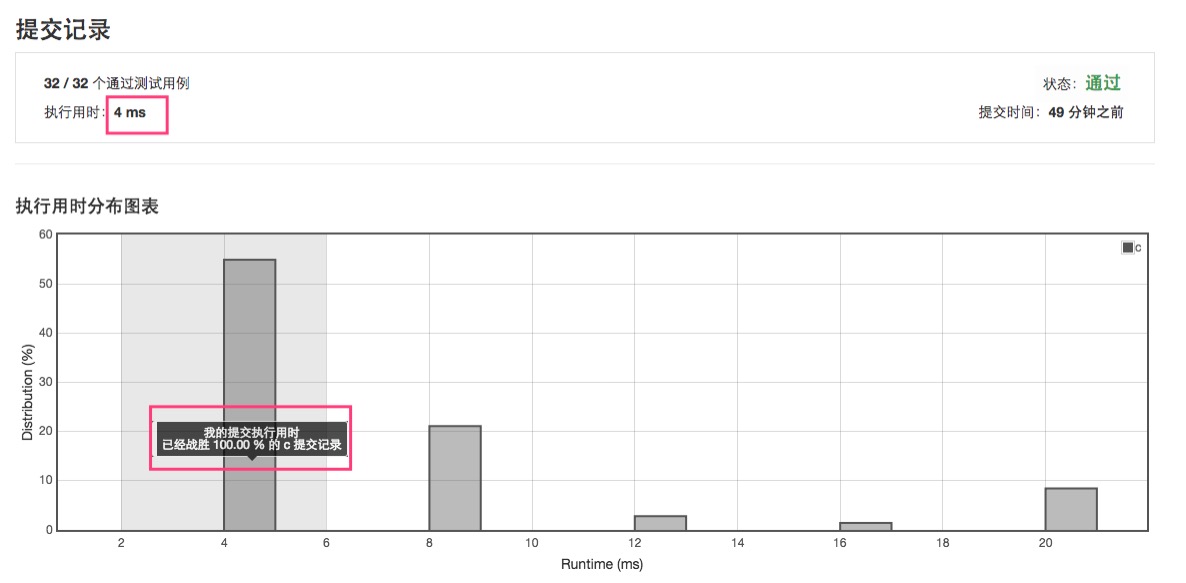
以上是同时使用“分治”与“重用”,而且“重用”的标准作业是自身,所设计出来的算法。
实际上,还有其它套路可以优雅地解决这个问题,比如“排除”的套路,不断地排除掉不符合答案的区域,最终定位到答案。对于这个“排除”套路,可以用折半查找的办法来实现。
对于“排除”套路,小程另作介绍,这里只给出对应的代码实现并结束本文的主要内容:
public class Solution {
public int PeakIndexInMountainArray(int[] A) {
int ret = 0;
int l = 0, r = A.Length - 1;
while (l < r) {
int m = (l+r) >> 1;
if (A[m] < A[m + 1]) l = m;
else if (A[m-1] > A[m]) r = m;
else {
ret = m;
break;
}
}
return ret;
}
}
简单来说。分治,就是大事化小,难点在于,怎么分,跟分到什么程度为止。重用,就是反复使用标准作业,可能要先假设有某种能力,再使用它,并真的达到某种能力,需要有空手套白狼的勇气。你自己领悟一下。
总结一下,本文再次介绍“分治”与“重用”套路的使用,分治能使问题规模变小并最终得到解决,重用能简化思考的复杂度并让思路简洁,这两个套路经常出现在算法设计当中。

标签:独立 复杂 length 要求 而不是 hello solution else 怎么
原文地址:https://www.cnblogs.com/freeself/p/10950612.html