标签:port new ati ring 对比 utf-8 col max stroke
Python有很多库,现在我们来学习MongoDB库
(1)MongoDB的概念
MongoDB基本概念是文档、集合、数据库、如下表:
|
SQL术语/概念 |
MongoDB术语/概念 |
解释/说明 |
|
database |
database |
数据库 |
|
table |
collection |
数据库表/集合 |
|
row |
document |
数据记录行/文档 |
|
column |
field |
数据字段/域 |
|
index |
index |
索引 |
|
table joins |
|
表连接,MongoDB不支持 |
|
primary key |
primary key |
主键,MongoDB自动将_id字段设置为主键 |
(2)MongoDB的数据类型
| 数据类型 | 描述 |
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
(3)MongoDB的常用命令为
|
> show dbs -- 查看数据库列表 |
|
> use admin --创建admin数据库,如果存在admin数据库则使用admin数据库 |
|
> db ---显示当前使用的数据库名称 |
|
> db.getName() ---显示当前使用的数据库名称 |
|
> db.dropDatabase() --删当前使用的数据库 |
|
> db.repairDatabase() --修复当前数据库 |
|
> db.version() --当前数据库版本 |
|
> db.getMongo() --查看当前数据库的链接机器地址 |
|
> db.stats() 显示当前数据库状态,包含数据库名称,集合个数,当前数据库大小 ... |
|
> db.getCollectionNames() --查看数据库中有那些个集合(表) |
|
> show collections --查看数据库中有那些个集合(表) |
|
> db.person.drop() --删除当前集合(表)person |
考虑到爬取的数据太多,此次只爬取最好大学排名前100名
其代码如下:
import requests import pandas as pd import numpy as np from bs4 import BeautifulSoup import sqlite3 allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding = ‘utf-8‘ return r.text except: return "" def fillUnivList(soup): data = soup.find_all(‘tr‘) for tr in data: ltd = tr.find_all(‘td‘) if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): with open(r‘C:\Users\Administrator\Desktop\大学排名.csv‘,‘w‘) as f: f.write("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}\n".format((chr(12288)),"排名","学校名称","省市","总分","科研规模")) for i in range(num): u=allUniv[i] f.write("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}\n".format((chr(12288)),i+1,u[1],u[2],eval(u[3]),u[6])) f.close() if 1: print("successful") else: print("fail") def main(num): url=‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html‘ html = getHTMLText(url) soup = BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(100)
爬取最好大学网2017中国最好大学前100名的结果显示如下:
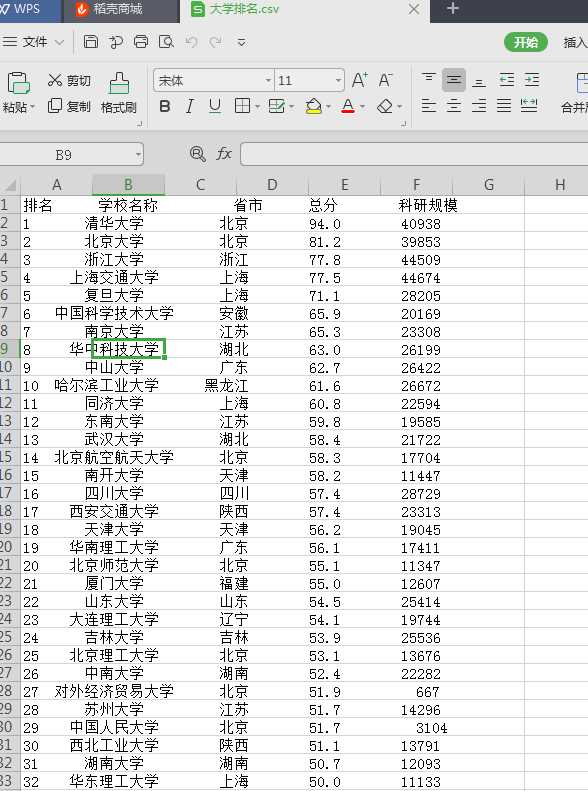
由于篇幅的问题就只显示前32名大学的排名情况.....................................
代码为:
import requests
from bs4 import BeautifulSoup
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = ‘utf-8‘
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all(‘tr‘)
for tr in data:
ltd = tr.find_all(‘td‘)
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def printUnivList(num):
a="广东"
print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","科研规模"))
for i in range(num):
u=allUniv[i]
#print(u[1])
if a in u:
print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),i+1,u[1],u[2],eval(u[3]),u[6]))
def main():
url=‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html‘
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
num=len(allUniv)
printUnivList(num)
main()
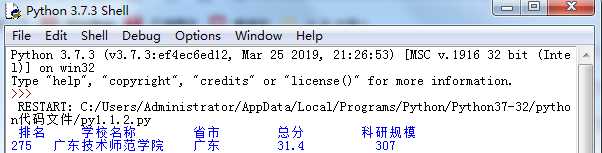
由于广东技术师范学院是在2019年改名为广东技术师范大学,上面代码的查询为“广东技术师范学院”
其显示为
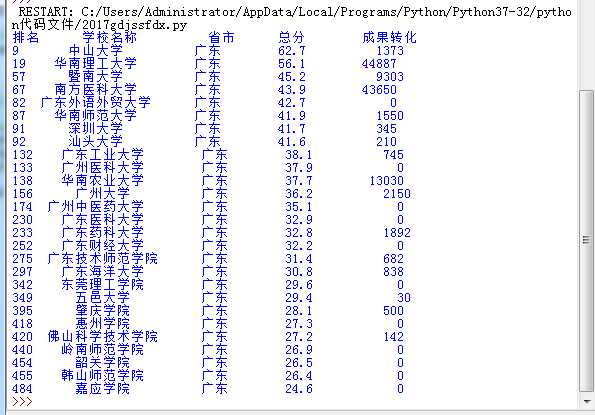
在上面查询“”广东技术师范学院”的代码改为“广东”将上面爬取的改为其“成果转化”
结果显示如下:
此次学习到此结束!!!期待下回分享...................................
标签:port new ati ring 对比 utf-8 col max stroke
原文地址:https://www.cnblogs.com/psl1234/p/10926654.html