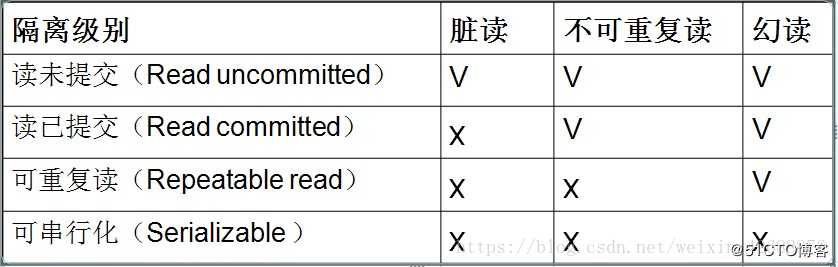
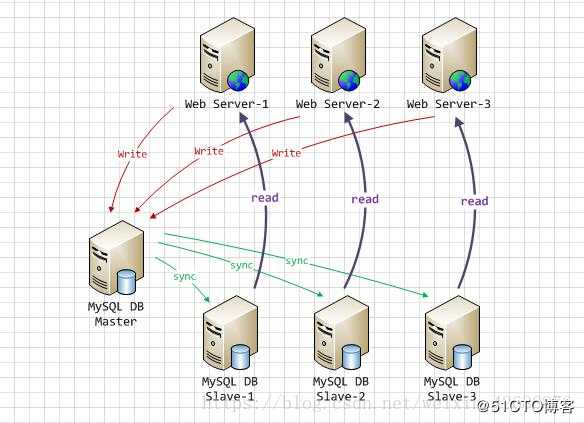
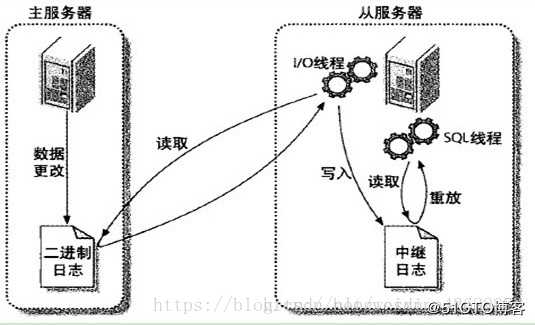
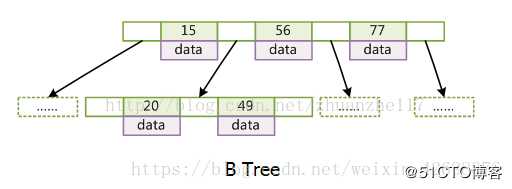
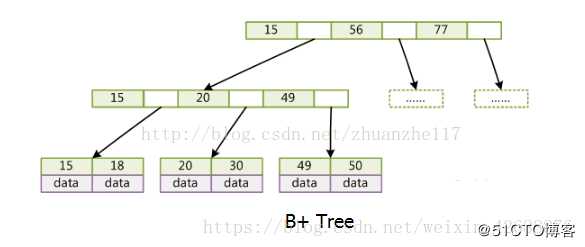
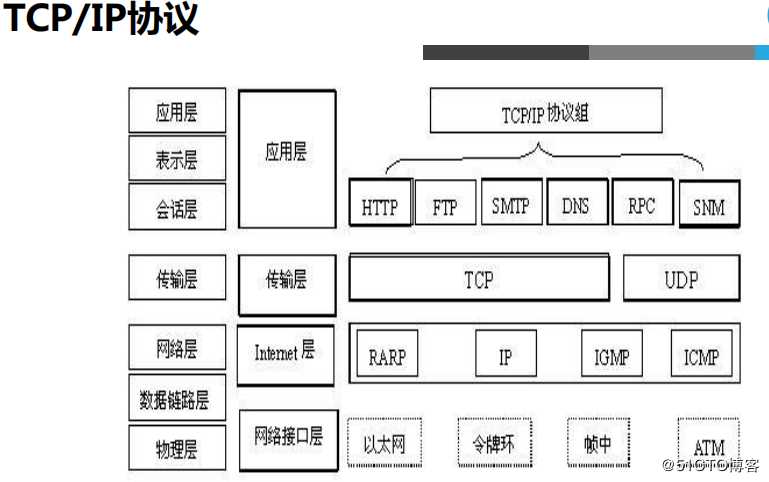
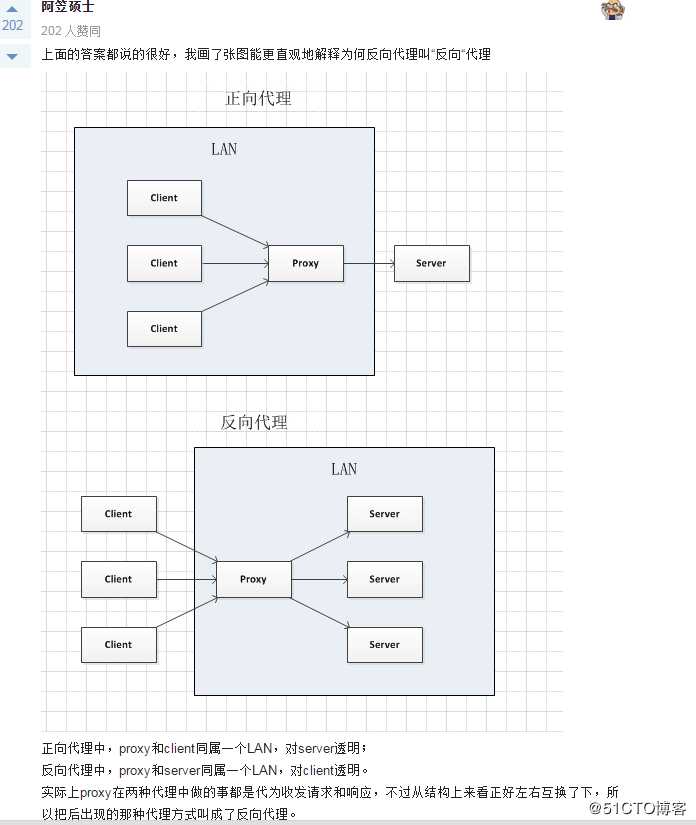
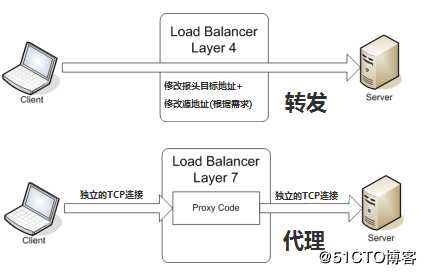
标签:applet string 运行时 注意 技术 签到 从服务器 端口 三次握手
Linux运维跳槽必备面试题
原文地址:https://blog.51cto.com/14128387/2402989