标签:consumer 结合 ica 自己 关闭 相关 terminal 依次 out
??安装环境:Ubuntu16.04
??前提条件:
??Apache基金会开源的这些软件基本上安装都比较方便,只需要下载、解压、配置环境变量三步即可完成,kafka也一样,官网选择对应版本下载后直接解压到一个安装目录下就可以使用了,如果为了方便可以在~/.bashrc里配置一下环境变量,这样使用的时候就不需要每次都切换到安装目录了。
??接下来可以通过简单的console窗口来测试kafka是否安装正确。
??(1)首先启动ZooKeeper服务。
??如果启动自己安装的ZooKeeper,使用命令zkServer.sh start即可。
??如果使用kafka自带的ZK服务,启动命令如下(启动之后shell不会返回,后续其他命令需要另开一个Terminal):
$ cd /opt/tools/kafka #进入安装目录
$ bin/zookeeper-server-start.sh config/zookeeper.properties??(2)第二步启动kafka服务
??启动Kafka服务的命令如下所示:
$ cd /opt/tools/kafka #进入安装目录
$ bin/kafka-server-start.sh config/server.properties??(3)第三步创建一个topic,假设为“test”
??创建topic的命令如下所示,其参数也都比较好理解,依次指定了依赖的ZooKeeper,副本数量,分区数量,topic的名字:
$ cd /opt/tools/kafka #进入安装目录
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1??创建完成后,可以通过如下所示的命令查看topic列表:
$ bin/kafka-topics.sh --list --zookeeper localhost:2181 ??(4)开启Producer和Consumer服务
??kafka提供了生产者和消费者对应的console窗口程序,可以先通过这两个console程序来进行验证。
??首先启动Producer:
$ cd /opt/tools/kafka #进入安装目录
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test??然后启动Consumer:
$ cd /opt/tools/kafka #进入安装目录
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning??在打开生产者服务的终端输入一些数据,回车后,在打开消费者服务的终端能看到生产者终端输入的数据,则说明kafka安装成功。
??安装好Kafka之后,本节我们通过一些实例来使用kafka,了解其基本的API和使用方法。
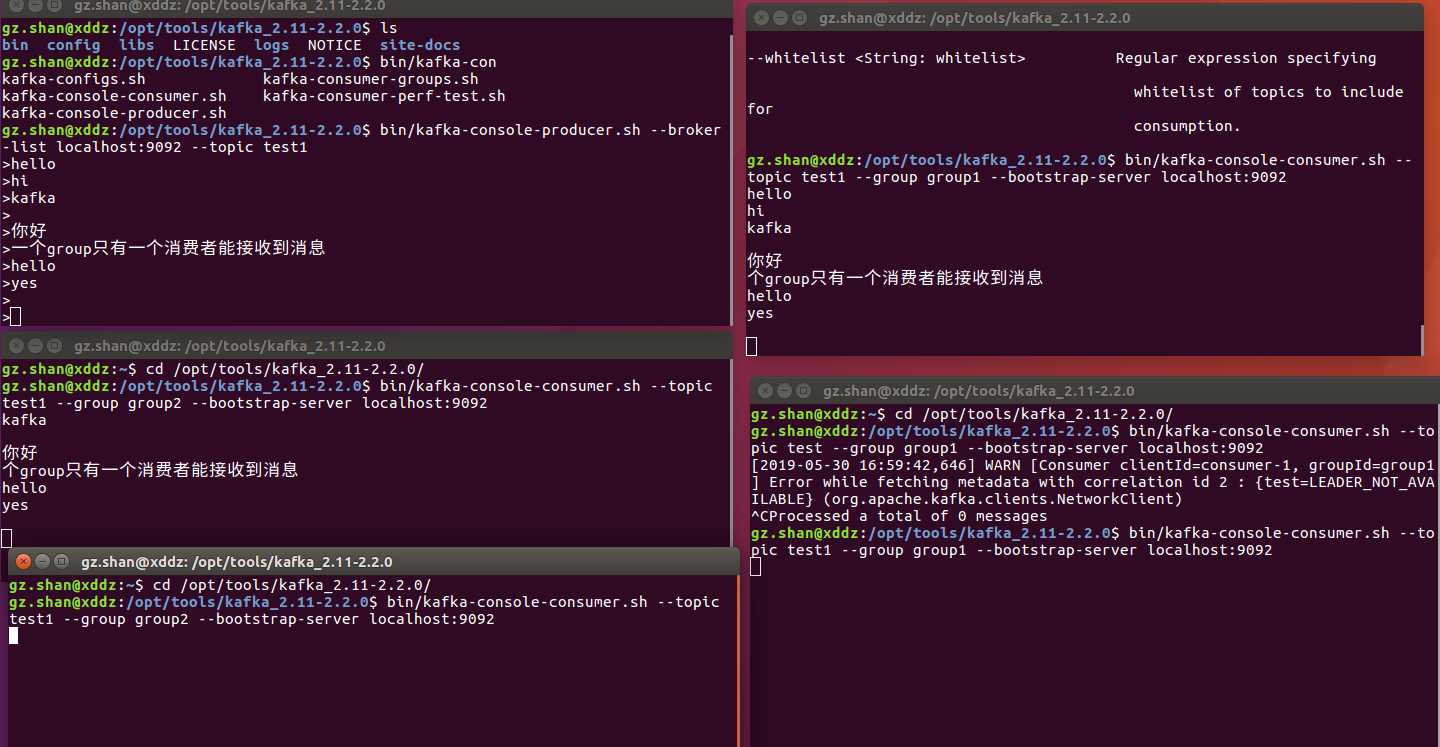
??我们通过一个简单的例子来验证同一个消费组的两个消费者不会同时消费一个partition中的数据,首先,启动一个生产者服务,对应的topic只有一个分区,然后创建4个消费者,其中两个属于同一组,另外两个属于另一组,即可验证则原理,验证情况如下图所示:
??通过以下程序给出一个kafka的java简单示例:
package com.kafka.sgz;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**生产者示例*/
public class KafkaProducerTest {
private static Producer<String, String> producer;
public final static String TOPIC="test1";
public KafkaProducerTest(){
Properties props=new Properties();
props.put("bootstrap.servers","localhost:9092");
props.put("acks","all");
props.put("retries",0);
props.put("batch.size",16384);
props.put("linger.ms",1);
props.put("buffer.memory",33554432);
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<String,String>(props);
}
public void produce(){
int messageNum=100;
final int count=120;
while(messageNum<count){
String key=String.valueOf(messageNum);
String data="@@@@hello kafka message"+key;
producer.send(new ProducerRecord<String,String>(TOPIC,key,data));
System.out.println(data);
messageNum++;
}
producer.close(); //注意发送完数据要关闭,否则可能出错
}
public static void main(String[] args){
new KafkaProducerTest().produce();
}
}package com.kafka.sgz;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class KafkaConsumerTest {
private static Consumer<String,String> consumer;
public final static String TOPIC="test1";
public KafkaConsumerTest(){
Properties props=new Properties();
props.put("bootstrap.servers","localhost:9092");
props.put("group.id","test-consumer-group"); //组号
props.put("enable.auto.commit","true"); //如果value合法,将自动提交偏移量
props.put("auto.commit.interval.ms","1000"); //设置多久更新一次被消费信息的偏移量
props.put("session.timeout.ms","30000"); //设置会话响应时间,超过可以放弃消费或者直接消费下一条
props.put("auto.offset.reset","earliest"); //自动重置Offset
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
consumer=new KafkaConsumer<String,String>(props);
}
public void consume(){
consumer.subscribe(Arrays.asList(TOPIC));
while(true){
ConsumerRecords<String,String> records=consumer.poll(100);
for(ConsumerRecord<String,String> record:records){
System.out.println("get message:"+record.key()+"---"+record.value());
}
}
}
public static void main(String[] args){
new KafkaConsumerTest().consume();
}
}??通过以下程序给出一个kafka的java简单示例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
import json
class Kafka_producer():
'''
使用kafka的生产模块
'''
def __init__(self, kafkahost,kafkaport, kafkatopic):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.producer = KafkaProducer(bootstrap_servers = '{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort
))
def sendjsondata(self, params):
try:
parmas_message = json.dumps(params)
producer = self.producer
producer.send(self.kafkatopic, parmas_message.encode('utf-8'))
producer.flush()
except KafkaError as e:
print e
class Kafka_consumer():
'''
使用Kafka—python的消费模块
'''
def __init__(self, kafkahost, kafkaport, kafkatopic, groupid):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.consumer = KafkaConsumer(self.kafkatopic, group_id = self.groupid,
bootstrap_servers = '{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort ))
def consume_data(self):
try:
for message in self.consumer:
# print json.loads(message.value)
yield message
except KeyboardInterrupt, e:
print e
def main():
'''
测试consumer和producer
:return:
'''
# 测试生产模块
producer = Kafka_producer("127.0.0.1", 9092, "ranktest")
for id in range(10):
params = '{abetst}:{null}---'+str(i)
producer.sendjsondata(params)
##测试消费模块
#消费模块的返回格式为ConsumerRecord(topic=u'ranktest', partition=0, offset=202, timestamp=None,
#\timestamp_type=None, key=None, value='"{abetst}:{null}---0"', checksum=-1868164195,
#\serialized_key_size=-1, serialized_value_size=21)
consumer = Kafka_consumer('127.0.0.1', 9092, "ranktest", 'test-python-ranktest')
message = consumer.consume_data()
for i in message:
print i.value
if __name__ == '__main__':
main()??本文从实践的角度介绍了kafka的安装和相关API的使用,结合上一篇文章的原理,可以对Kafka有一个比较基础的理解和认识。
标签:consumer 结合 ica 自己 关闭 相关 terminal 依次 out
原文地址:https://www.cnblogs.com/gzshan/p/10959215.html