标签:pen 16px 路径名 rip apach assembly 自己 Parquet park
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>test.TestOperFile</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
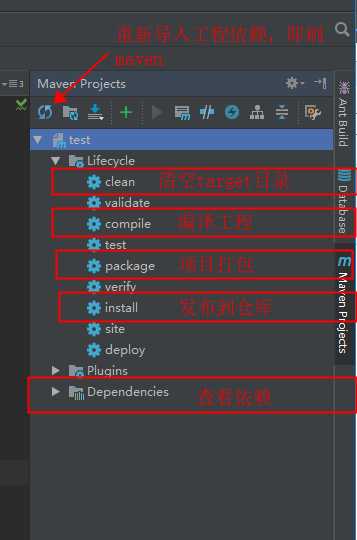
注意:关于插件中这个地方需要注意一下:

这里分为两种情况
a.打包scala程序
如果只是打包scala程序的话,这里代表的是主函数的方法名,一定是全路径名(包名+类名)
jar包运行方式:java -jar test.jar [参数1 参数2...]
b.打包spark程序
如果是打包spark程序的话,这里可以随意,不影响,运行的时候需要指定类名即可
jar包运行方式:
spark-submit --class test.testOperator \
--master yarn \
--deploy-mode client \
--driver-memory 3g \
--executor-memory 2g \
--executor-cores 1 \
--num-executors 4 \
--jars /hadoop/datadir/deploy/lib/mysql-connector-java-5.1.7-bin.jar \
--conf spark.sql.shuffle.partitions=100 \
--conf spark.shuffle.sort.bypassMergeThreshold=5 \
--conf spark.kryoserializer.buffer.max=128m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.parquet.compression.codec=snappy \
--conf spark.shuffle.sort.bypassMergeThreshold=5 \
--conf spark.locality.wait.node=6 \
--conf spark.locality.wait.process=6 \
test.jar [参数1,参数2...]
运行参数可以根据自己的需求进行调整
打包后的结果:
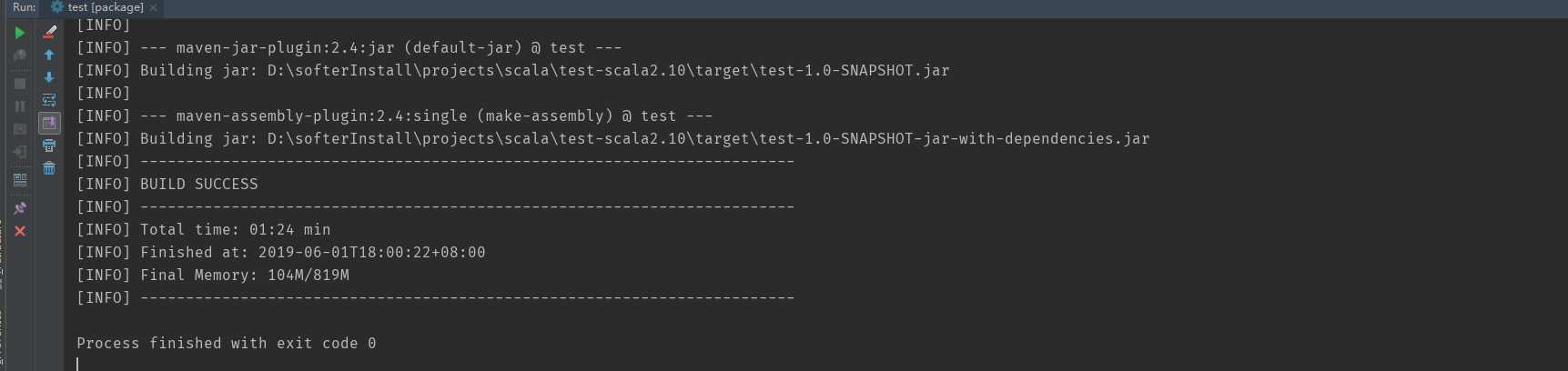
如果出现上图所示,说明打包成功,此时找到右边的target目录,下面会有两个包:
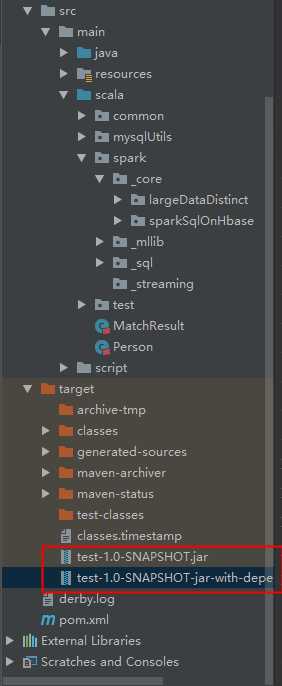
然后执行的时候,我们只需要执行第二个包就可以了,也就是名字长的那个包:
a.对于scala程序的jar包,因为main函数已经在pom中打包之前指定了,所以执行的时候如果有参数,只需要传入相应的参数即可,用空格分开
1、使用 "java -jar" 的方式提交:

2、使用submit的方式提交程序

可以看到,也可使用submit的方式进行提交,可以指定--class,也可以不指定
b.对于spark程序的jar包,此时即使是在pom中指定了main函数,在提交的执行的时候必须按照spark程序的提交方式进行提交,即使用submit的方式,不能用 java -jar的方式提交,否则会报错
1、使用submit的方式提交程序:
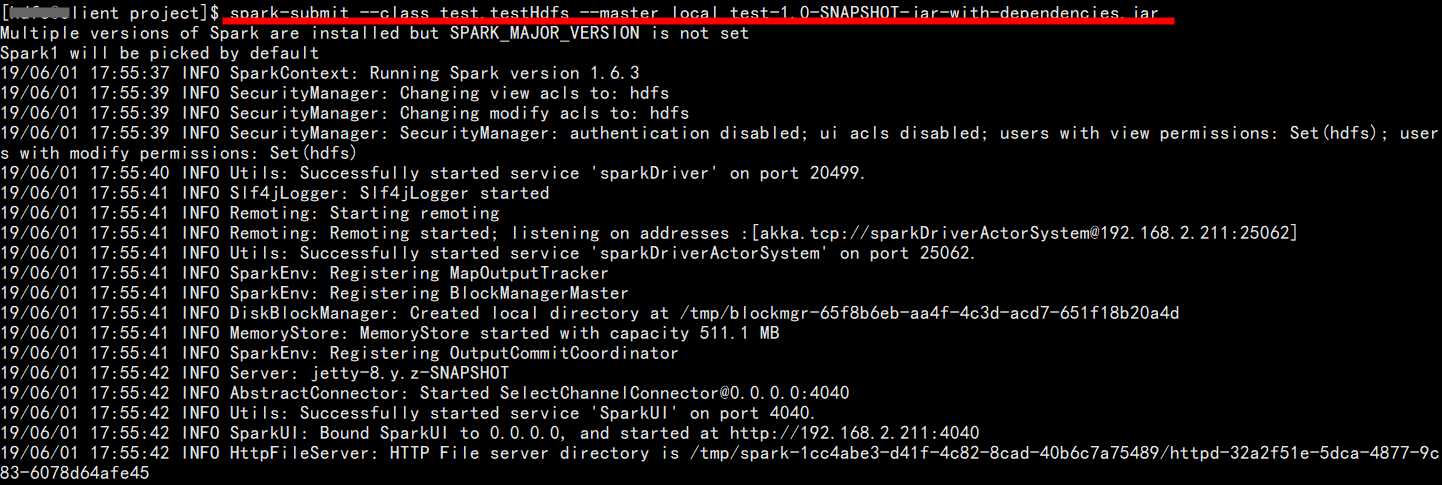
这样提交运行之后是没有什么问题的
2、使用 "java -jar" 的方式提交:
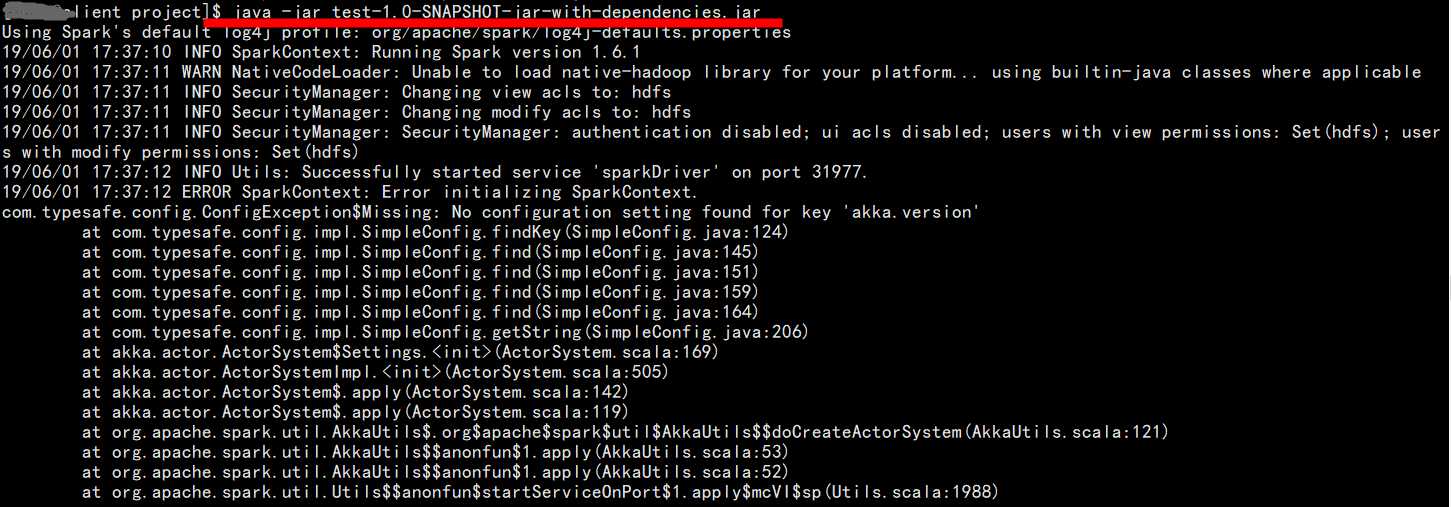
报错,至于如何解决,本人暂时还没有找到好的方案。希望能够帮到需要的童鞋
标签:pen 16px 路径名 rip apach assembly 自己 Parquet park
原文地址:https://www.cnblogs.com/Gxiaobai/p/10960599.html