标签:ima admin span dir process pipe title awl 爬虫
在做两者结合之前,需要先准备一个可以独立运行的Scrapy框架和一个可以独立运行的Django框架!
当准备好这两个框架之后,就可以做两者的结合了。
一、
把scrapy框架,移动到Django框架的目录下!( jiqi 是Django、 Seo是Scrapy )
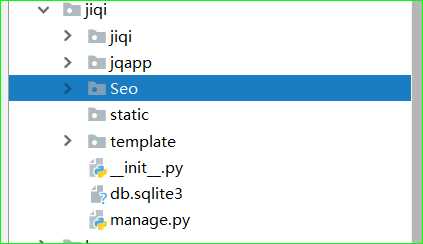
二、
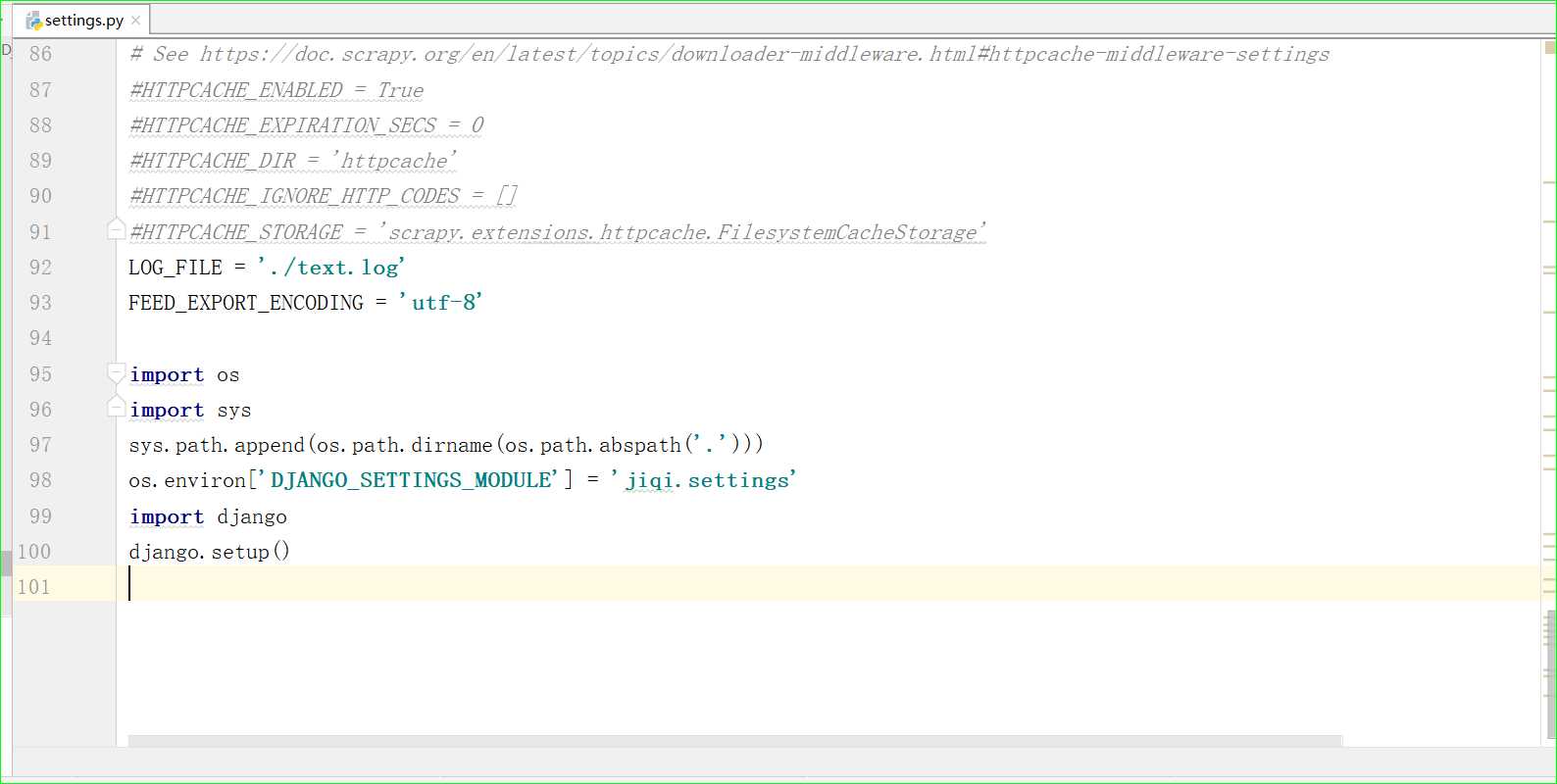
打开scrapy 中的setting.py:
加上:
import os import sys sys.path.append(os.path.dirname(os.path.abspath(‘.‘))) os.environ[‘DJANGO_SETTINGS_MODULE‘] = ‘django项目名.settings‘ import django django.setup()
三、
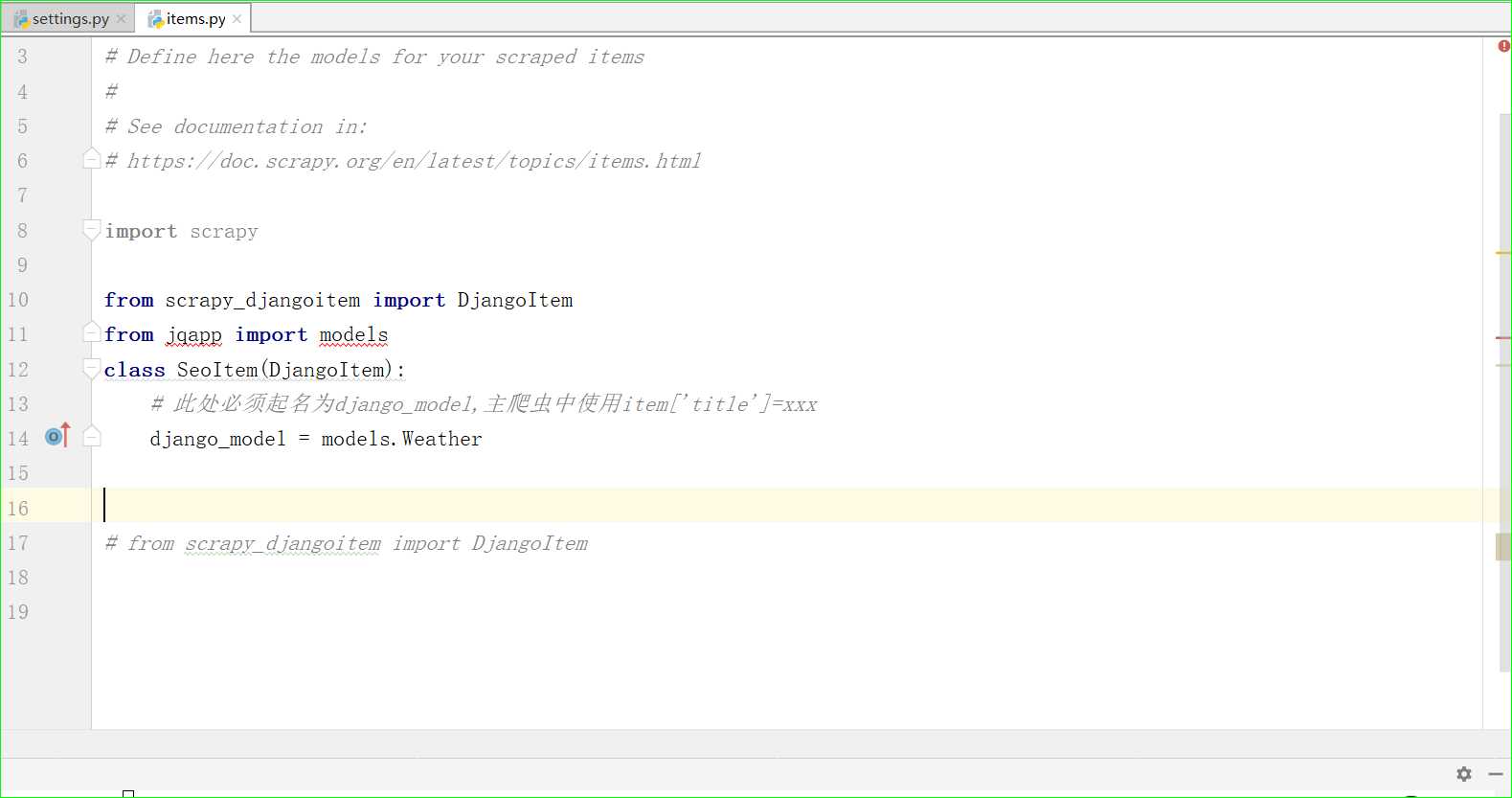
Scrapy中的.item.py中引入Django模型类
安装命令:pip install scrapy-djangoitem
然后在item中加入Django的模型类:
from scrapy_djangoitem import DjangoItem from app import models class SeoItem (DjangoItem): # 此处必须起名为django_model,主爬虫中使用item[‘title‘]=xxx django_model = models.AbckgModel
Django中的模型类(models.py):

四、
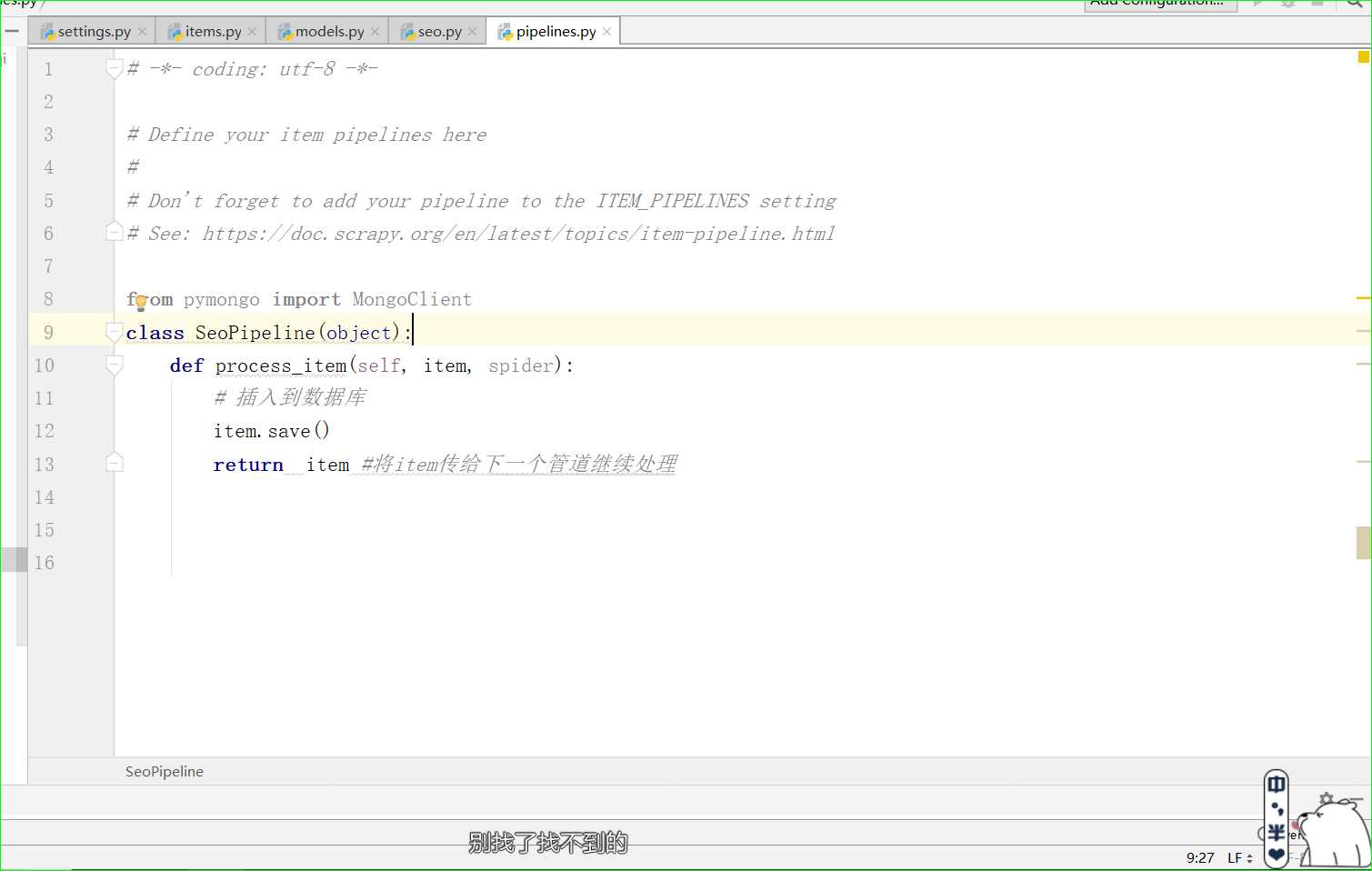
在scrapy的 pipelines.py中调用save()
class SeoPipeline(object): def process_item(self, item, spider): # 插入到数据库 item.save() return item #将item传给下一个管道继续处理
五、启动爬虫:
scrapy crawl seo
六、刷新django-admin后台
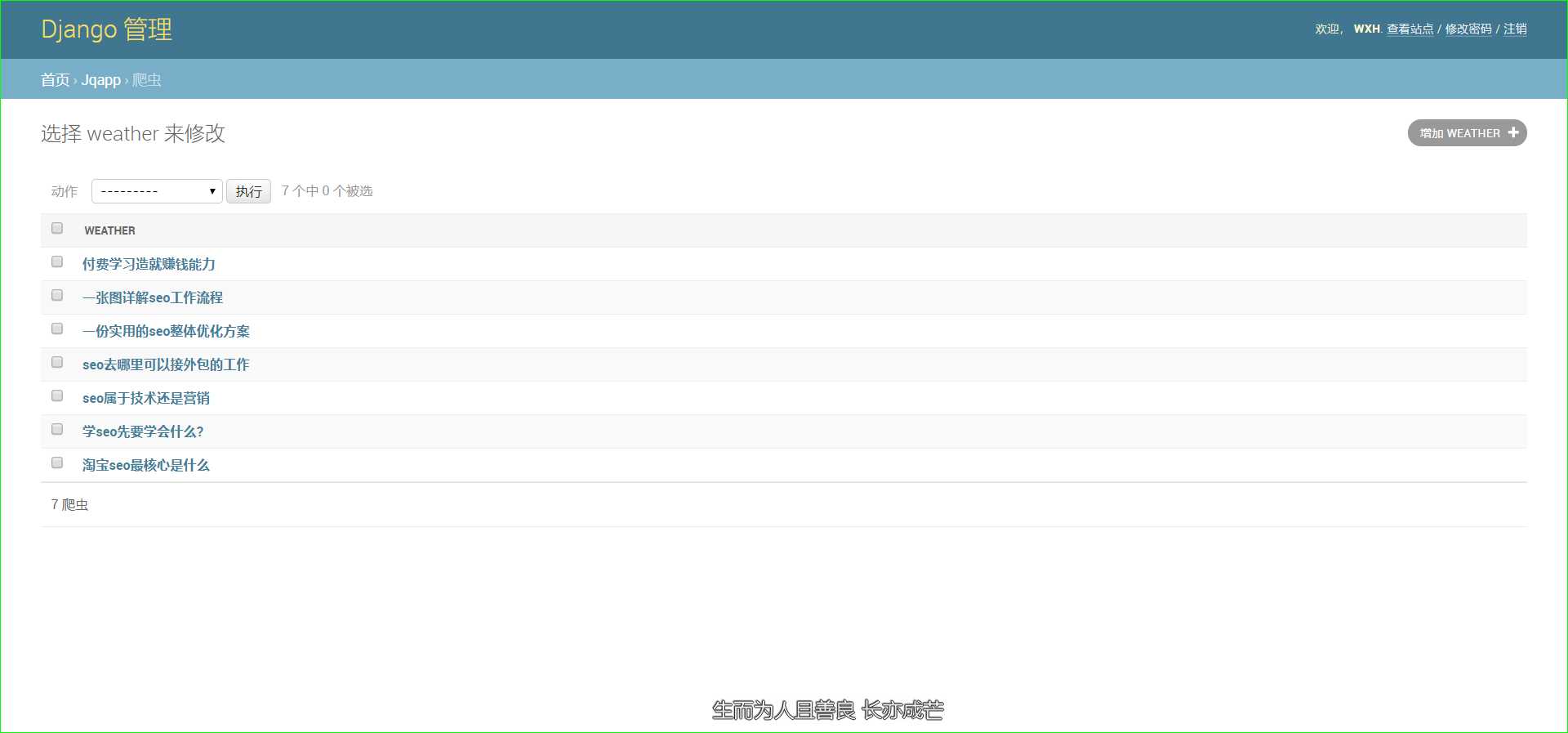
好了 ,这样就把scrapy爬取出来的数据,加到了Django_admin后台!
# 注:如有转载,请标明作者出处,谢谢!
标签:ima admin span dir process pipe title awl 爬虫
原文地址:https://www.cnblogs.com/coolwxh/p/10930931.html