标签:sig image cep nes 响应 pat turn 文件命名 tput
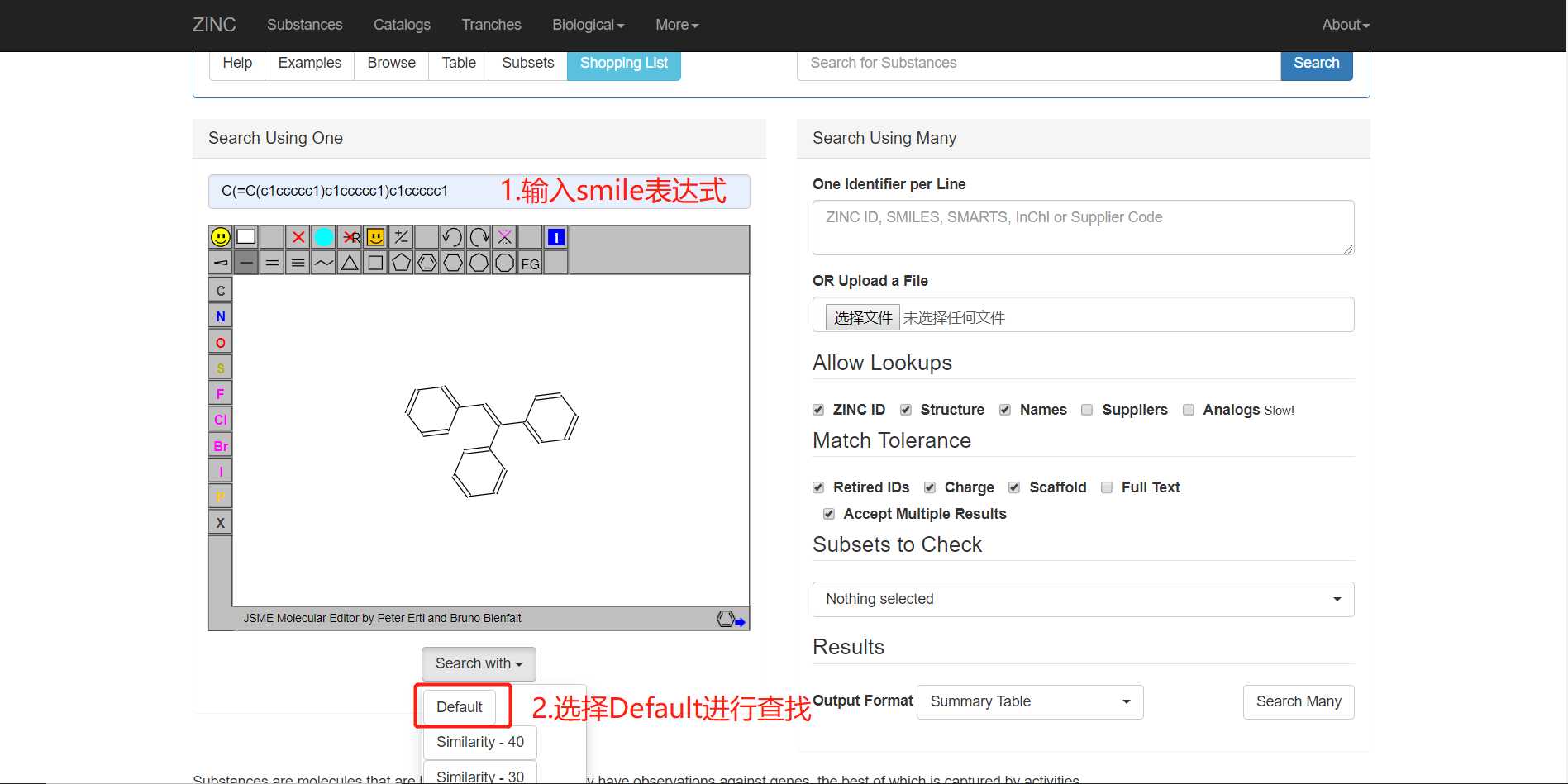
最近接到实验室的导师交给我的一个任务,就是他们手头有很多smile表达式,格式类似这种:C(=C(c1ccccc1)c1ccccc1)c1ccccc1(这是生物信息学中表达小分子结构的一种常用表达式),他们需要对每个smile表达式在ZINC网站(生物信息学数据网站)上进行搜索,然后找到对应的ZINC号、小分子供应商、构象预测等信息。基本步骤如下:
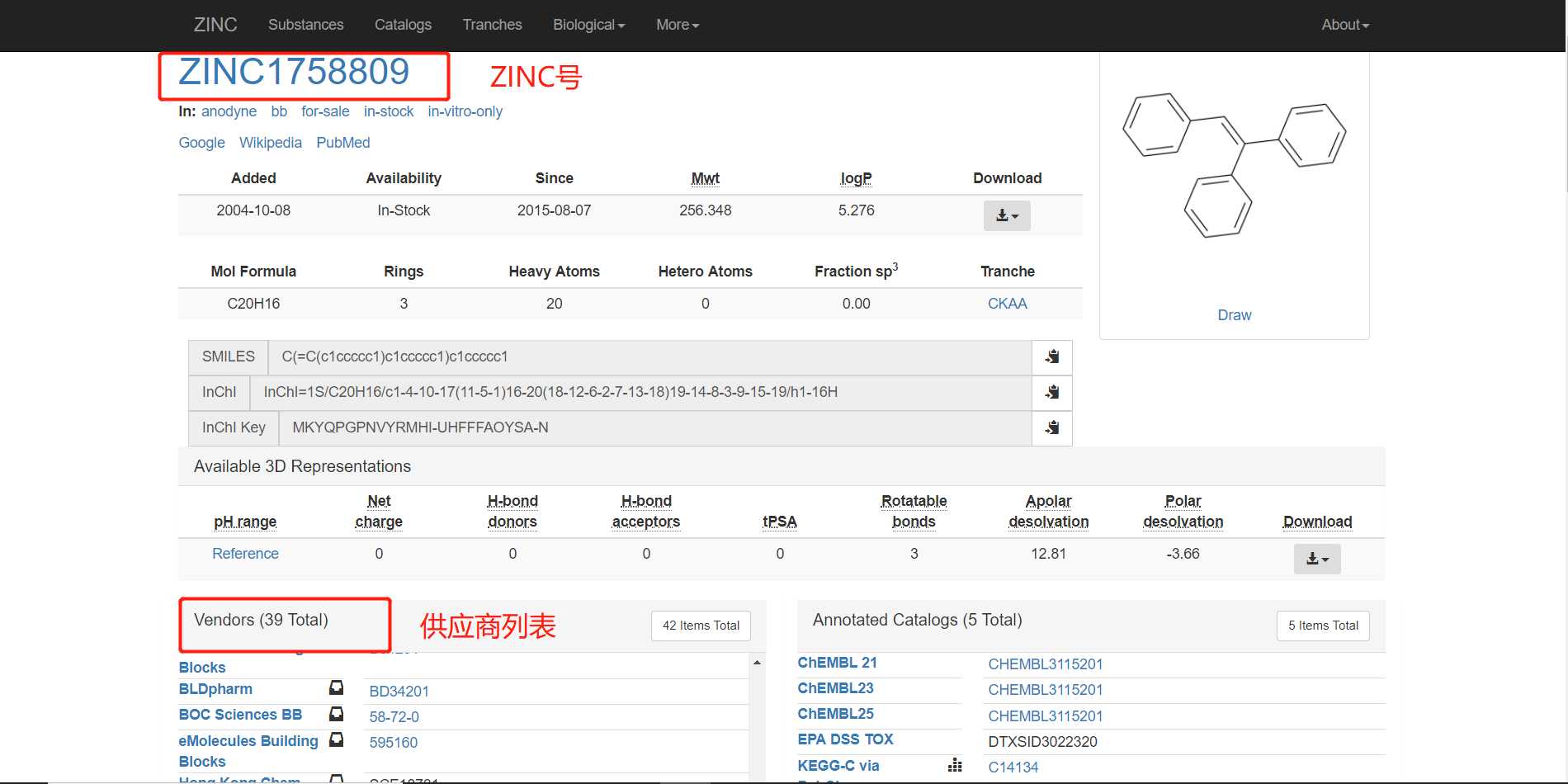
点击查找之后网页就会跳转到详细信息,我们需要获取它的ZINC号、小分子供应商、构象预测、CAS号等信息,如下:


这一套流程要是靠人工手动完成的话有点不太现实,毕竟他们有一千多个这样的smile号,要是一个一个搞还不要累死,于是他们想到了我,想让我写一个爬虫来自动化提取出这些信息,一劳永逸。说实话我当时接到这个任务的时候毫不犹豫答应了下来,一来是我之前确实写过类似的程序,二来自己最近确实很闲,毕业论文搞得差不多了,每天没啥事打打王者一天的时间就浪费掉了,还不如接个任务,也算是练练手。废话不多说,直接开干。
在撸代码之前我们要先搞清楚几个问题,不能蛮干。首先我们要知道在我们输入smile号并点击搜索的时候,这个时候前端和后端服务器交互的过程是什么样的,也就是说前端到底给后端发送了什么样的HTTP请求。要知道我们一开始可是只输入了一个smile号,网页就直接跳转到了http://zinc15.docking.org/substances/ZINC000001758809/,这肯定是后台根据smile号查出ZINC号之后回应了一个重定向请求,猜想是这样,我们来看看实际情况。在浏览器中右键点击检查,查看在我们操作的过程中浏览器到底向后台发送了哪些请求。
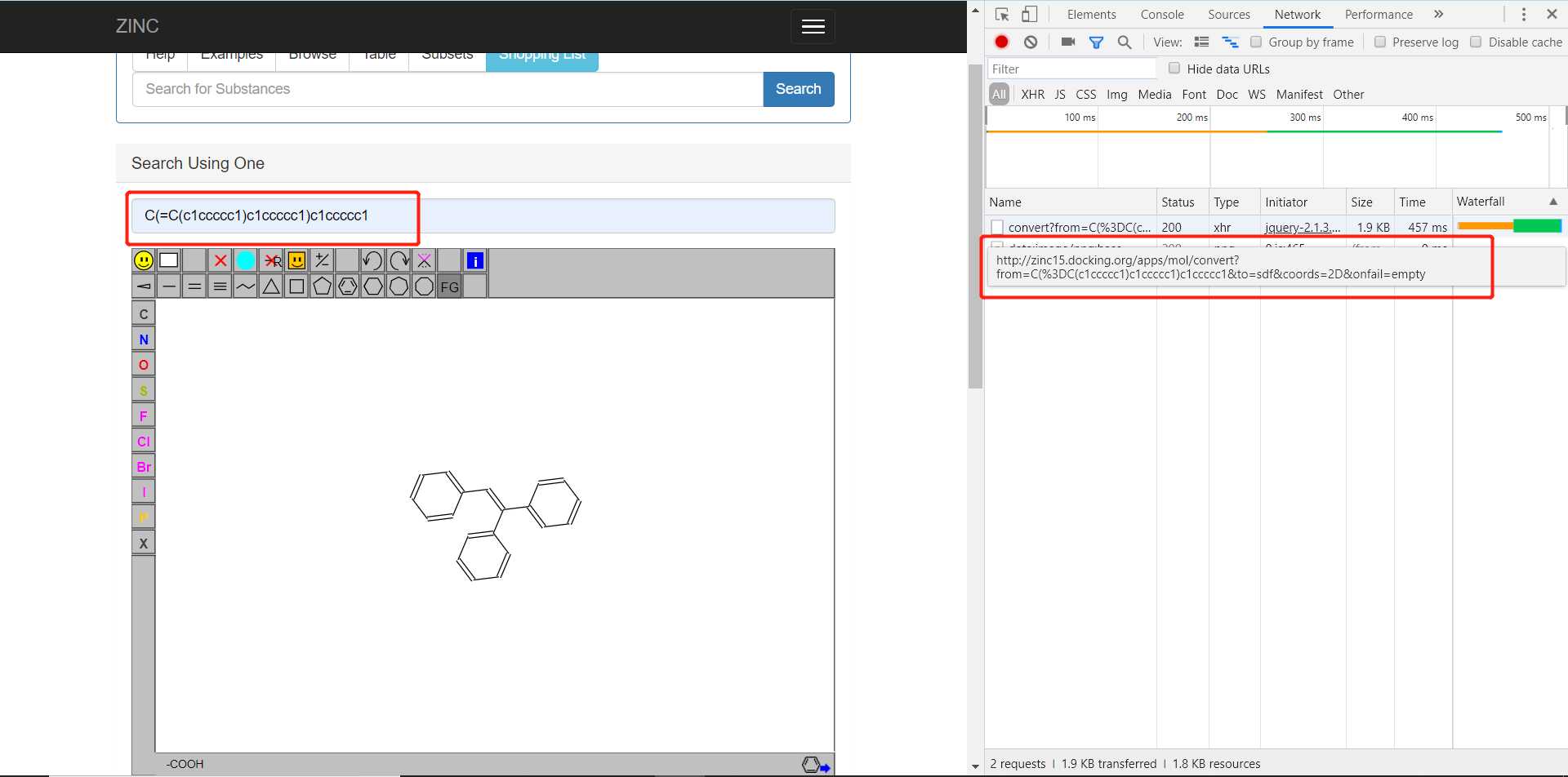
从上图可以看到,我们一旦键入smile表达式之后,浏览器立马给后台发送了一个请求,然后网页显示出一个小分子的图像,很显然这个请求是为了获取小分子构象信息然后生成图片的,这个流程我们不做深究,我们要知道到底发送什么请求才能获得重定向后的地址,并拿到真正有用的网页。我们点击搜索,接着往下看:
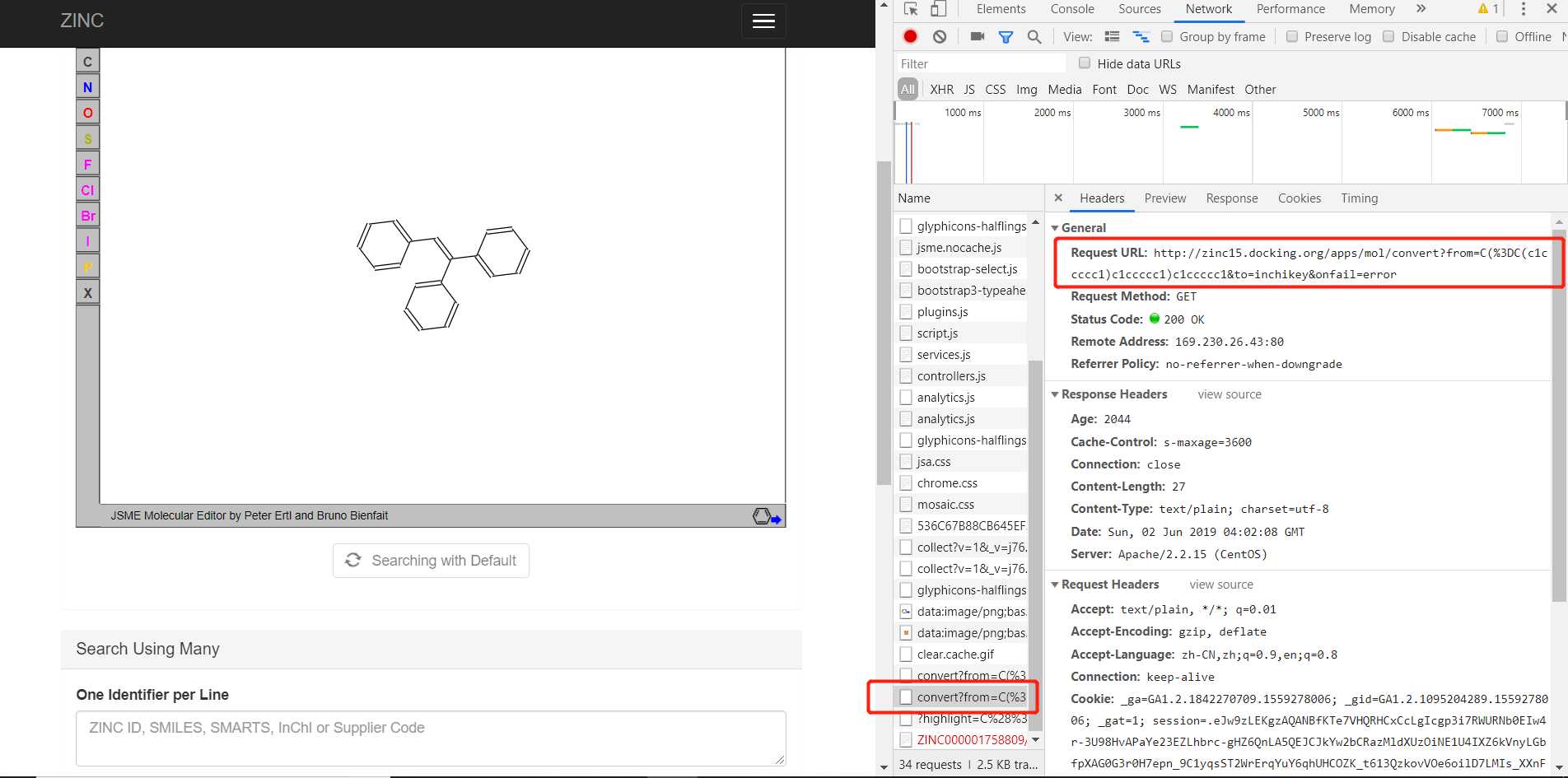
在接下来的请求中,我们发现了一个关键请求(上图标红处),这个请求的响应体返回的是一个序列号,如下图:
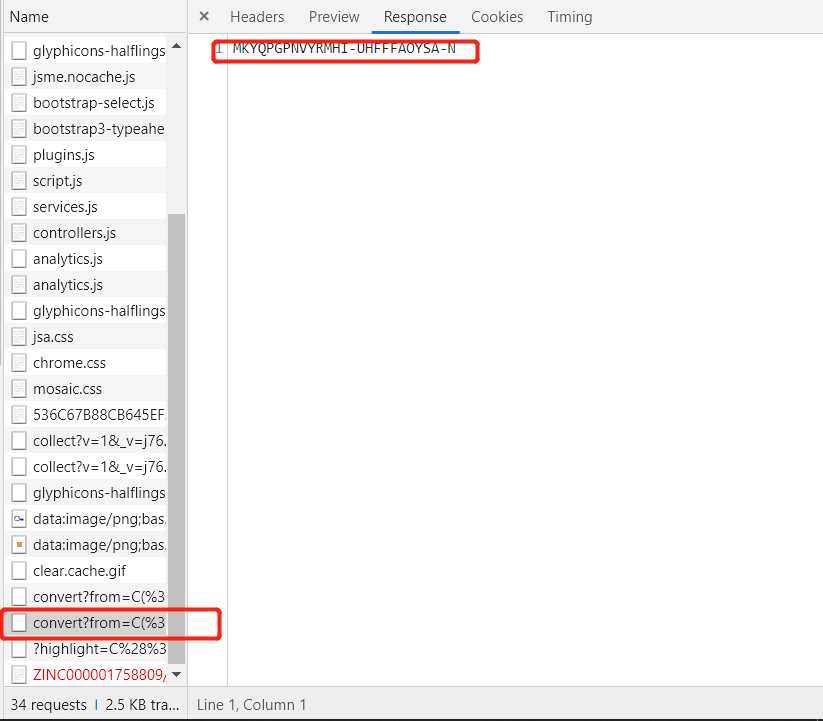
不要小看这个序列号,虽然我也不知道它具体代表什么意思,但是后面的请求充分向我们说明了这个序列号的重要性,即后面需要smile表达式带上这个序列号一起发送一个HTTP请求,才能获取到那个关键的重定向网页,如下图:
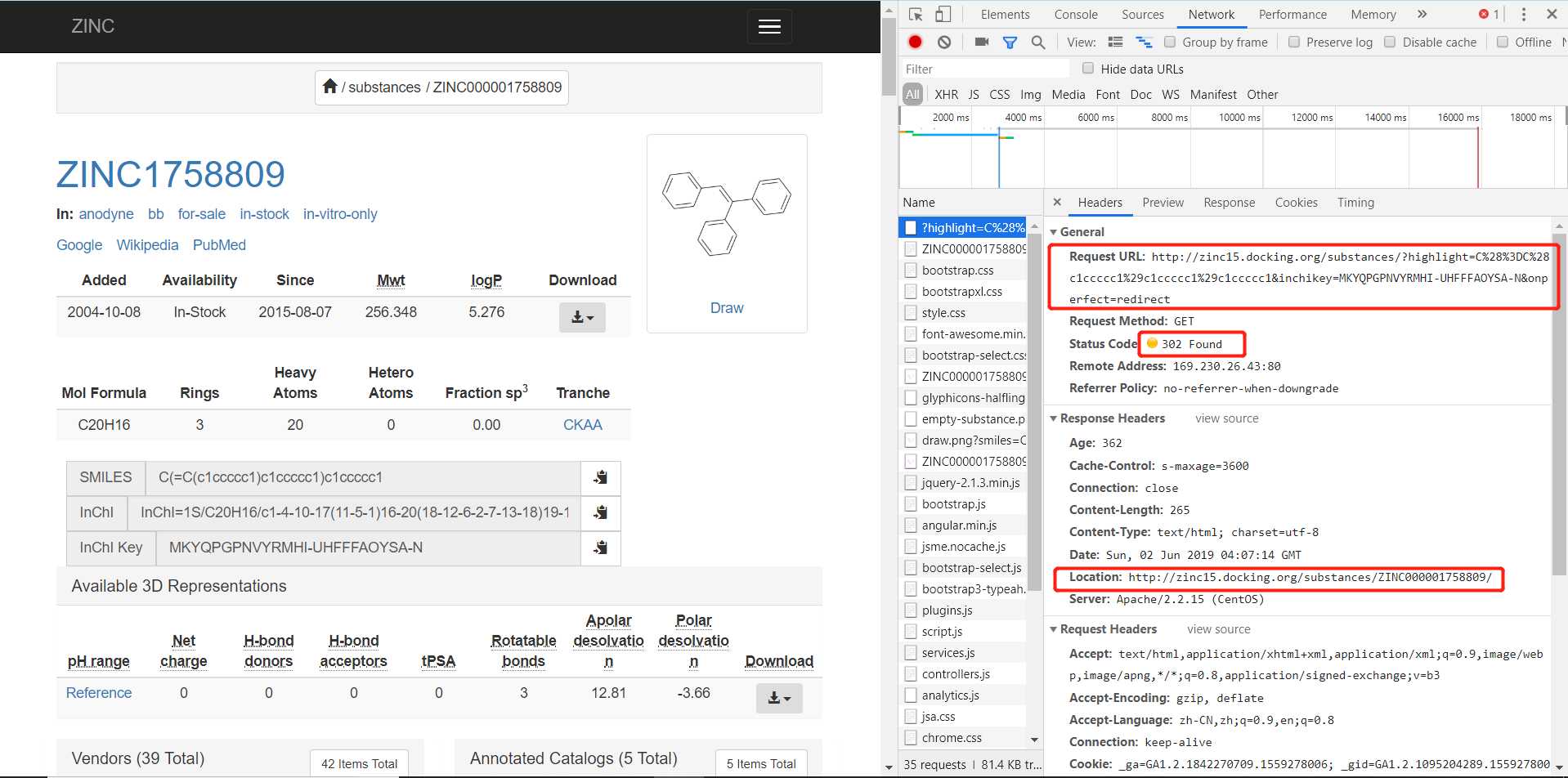
到目前为止,这个网页的请求逻辑已经很清楚了,我们只需要利用python模仿浏览器发送同样的请求,首先获取这个inchikey序列号,然后通过这个序列号和smile表达式再次发起请求就能得到重定向的网址了,然后对这个重定向网址发起请求就能获得我们所需要的关键网页了,我们所需要的全部信息都包含在这个重定向后的网页里,然后只要解析这个html网页,从中提取出我们想要的信息就行了。思路已经很清晰了,可以撸代码了,具体Python代码如下:
1 #coding=utf-8 2 3 ‘‘‘ 4 @Author: jeysin@qq.com 5 @Date: 2019-6-1 6 @Description: 7 本爬虫运行环境为python2.7,在python3中不能运行。运行前先将含有smile表达式的文件命名为SMILE.txt放在与本文件相同的目录下,执行程序后, 8 本爬虫会自动读取SMILE.txt文件中的内容,并根据smile表达式抓取ZINC网站的网页进行分析,得到的结果会以当前时间命名放在当前执行目录下。 9 PS:程序运行快慢取决于当前网速和SMILE.txt文件大小,请耐心等待。 10 ‘‘‘ 11 12 import os,sys 13 import urllib 14 import urllib2 15 import json 16 import time 17 import re 18 from HTMLParser import HTMLParser 19 from datetime import datetime 20 21 headers = { 22 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3", 23 "Accept-Encoding": "gzip, deflate", 24 "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", 25 "Host": "zinc15.docking.org", 26 "Referer": "http://zinc15.docking.org/substances/home/", 27 "Upgrade-Insecure-Requests": "1", 28 "Cookie": "_ga=GA1.2.1842270709.1559278006; _gid=GA1.2.1095204289.1559278006; _gat=1; session=.eJw9zLEKgzAQANBfKTd3qcRFcEgJBIdLQE7hbhFqW6pRC20hGPHf26nvA94G3XCFYoPDBQoQCjlm7YCzTDLWk6N2xBSi2CoKcXSzjGJ0zqkvYT9C_37du88z3JZ_gXP98MTJWY6eesXUKG85RwonTs3q6BzEyOQMrmirzCWtUJe_bv8CllwtkQ.D9Kh8w.M2p5DfE-_En2mAGby_xvS01rLiU", 29 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36" 30 } 31 32 #解析SEA Predictions 33 def getSeaPredictions(html): 34 seaPrediction = [] 35 begin = html.find("SEA Predictions", 0) 36 if(begin == -1): 37 return seaPrediction 38 end = html.find("</tbody>", begin) 39 left = html.find("<td>", begin) 40 right = html.find("</td>", left) 41 pattern = re.compile(‘>(.*?)<‘) 42 while(right < end): 43 str = html[left:right+5] 44 str = str.replace("\n", "").replace("\t", "") 45 str = ‘‘.join(pattern.findall(str)) 46 str = str.strip() 47 seaPrediction.append(‘ ‘.join(str.split())) 48 left = html.find("<td>", right) 49 right = html.find("</td>", left) 50 if(left == -1 or right == -1): 51 break 52 return seaPrediction 53 54 #解析Vendors 55 def getVendors(zincNum): 56 url = "http://zinc15.docking.org/substances/" + zincNum + "/catitems/subsets/for-sale/table.html" 57 request = urllib2.Request(url, headers = headers) 58 response = urllib2.urlopen(request) 59 html = response.read() 60 61 #获取More about字段结束的位置列表,在其附近查找Vendors 62 indexList = [] 63 begin = 0 64 index = html.find("More about ", begin) 65 while(index != -1): 66 indexList.append(index + 11) 67 begin = index + 11 68 index = html.find("More about ", begin) 69 70 vendors = [] 71 pattern = re.compile(‘>(.*?)<‘) 72 for i in range(len(indexList)): 73 begin = indexList[i] 74 end = html.find(‘">‘, begin) 75 vendors.append(html[begin:end]) 76 77 begin = html.find("<td>", end) 78 end = html.find("</td>", begin) 79 str = html[begin:end+5] 80 vendors.append(‘‘.join(pattern.findall(str))) 81 82 return vendors 83 84 #解析CAS numbers 85 def getCasNum(html): 86 result = re.search("<dt>CAS Numbers</dt>", html) 87 if(result == None): 88 return "None" 89 begin = result.span()[1] 90 begin = html.find("<dd>", begin, len(html)) 91 begin = begin + 4 92 end = html.find("</dd>", begin, len(html)) 93 if(begin + 1 >= end): 94 return "None" 95 str = html[begin:end] 96 casNumList = re.findall(‘[0-9]+-[0-9]+-[0-9]+‘, str) 97 if(casNumList == None): 98 return "None" 99 casNumStr = "" 100 for i in range(len(casNumList)): 101 casNumStr = casNumStr + casNumList[i] 102 if(i != len(casNumList)-1): 103 casNumStr = casNumStr + "," 104 return casNumStr 105 106 #解析ZINC号 107 def getZincNum(html): 108 result = re.search("Permalink", html) 109 if result is None: 110 return None 111 else: 112 begin = result.span()[1] 113 while(html[begin] != ‘\n‘): 114 begin = begin +1 115 begin = begin + 1 116 end = begin 117 while(html[end] != ‘\n‘): 118 end = end + 1 119 zincNum = html[begin:end] 120 return zincNum.strip() 121 122 #解析网页数据并写入文件 123 def parseHtmlAndWriteToFile(smile, html, output): 124 125 zincNum = getZincNum(html) 126 if zincNum is None: 127 print "ZINC number:\tNone" 128 output.write("ZINC number:\tNone\n") 129 return 130 else: 131 print "ZINC number: " + zincNum 132 output.write("ZINC number:\t" + zincNum + ‘\n‘) 133 134 casNum = getCasNum(html) 135 print "CAS numbers: " + casNum 136 output.write("CAS numbers:\t" + casNum + ‘\n‘) 137 138 output.write(‘\n‘) 139 140 vendors = getVendors(zincNum) 141 if(0 == len(vendors)): 142 print "Vendors:\tNone" 143 output.write("Vendors:\tNone\n") 144 else: 145 print "Vendors:\t"+str(len(vendors)/2)+" total" 146 output.write("Vendors:\t"+str(len(vendors)/2)+" total\n") 147 i = 0 148 while(i < len(vendors)-1): 149 output.write(vendors[i]+" | "+vendors[i+1]+"\n") 150 i = i + 2 151 152 output.write(‘\n‘) 153 154 seaPrediction = getSeaPredictions(html) 155 if(0 == len(seaPrediction)): 156 print "SEA Prediction:\tNone" 157 output.write("SEA Prediction:\tNone\n") 158 else: 159 print "SEA Prediction:\t"+str(len(seaPrediction)/5)+" total" 160 output.write("SEA Prediction:\t"+str(len(seaPrediction)/5)+" total\n") 161 i = 0 162 while(i < len(seaPrediction)-4): 163 output.write(seaPrediction[i] + " | " + seaPrediction[i+1] + " | " + seaPrediction[i+2] + " | " + seaPrediction[i+3] + " | " + seaPrediction[i+4] +"\n") 164 i = i + 5 165 166 #向重定向地址发起请求,获取网页数据 167 def getPage(url): 168 request = urllib2.Request(url, headers = headers) 169 response = urllib2.urlopen(request) 170 html = response.read() 171 return html 172 173 174 #构造url发起请求,获取inchikey然后获取重定向地址 175 def getRedirectUrl(smile): 176 encodeSmile = urllib.quote(smile, ‘utf-8‘) 177 url = ‘http://zinc15.docking.org/apps/mol/convert?from=‘ + encodeSmile + ‘&to=inchikey&onfail=error‘ 178 request = urllib2.Request(url, headers = headers) 179 response = urllib2.urlopen(request) 180 inchikey = response.read() 181 182 url = ‘http://zinc15.docking.org/substances/?highlight=‘ + encodeSmile + ‘&inchikey=‘ + inchikey + ‘&onperfect=redirect‘ 183 request = urllib2.Request(url, headers = headers) 184 newUrl = urllib2.urlopen(request).geturl() 185 return newUrl 186 187 188 def main(): 189 inputFilename = "D:\python\SMILE.txt" 190 #outputFilename = datetime.now().strftime(‘%Y-%m-%d-%H-%M-%S‘) + ".txt" 191 outputFilename = "result.txt" 192 with open(inputFilename, "r") as input, open(outputFilename, "w") as output: 193 for line in input.readlines(): 194 smile = line.strip() 195 print "SMILE:\t" + smile 196 output.write("SMILE:\t" + smile + ‘\n‘) 197 newUrl = getRedirectUrl(smile) 198 print newUrl 199 html = getPage(newUrl) 200 parseHtmlAndWriteToFile(smile, html, output) 201 print ‘\n‘ 202 output.write(‘\n\n\n‘) 203 204 if __name__ == "__main__": 205 main()
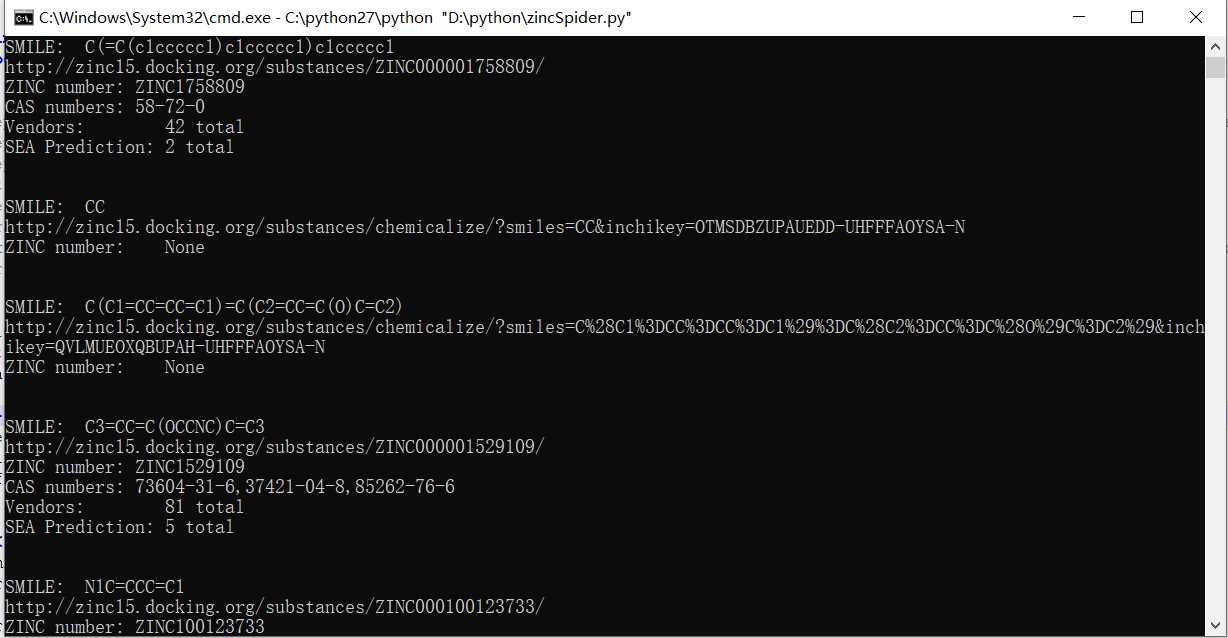
以下是程序运行时截图:
最终抓取到的文本信息截图:
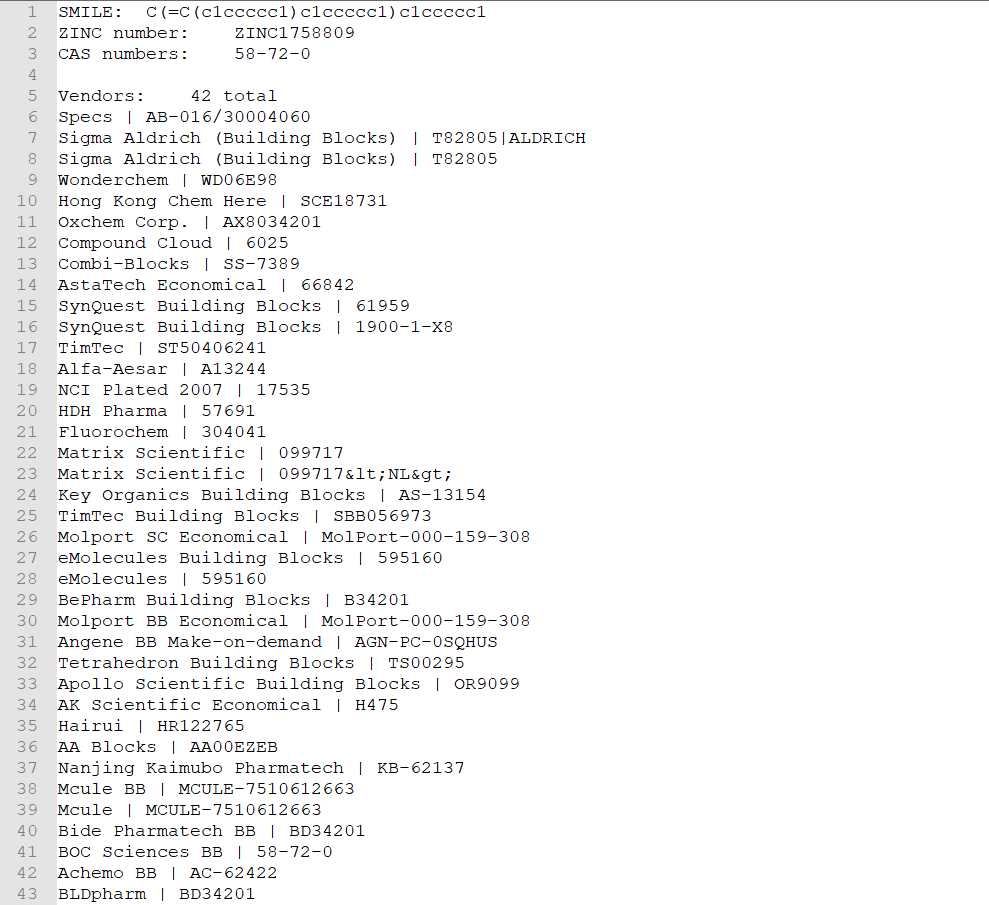
完美解决问题!!!
这里总结一下写爬虫需要注意哪些问题:
1、要摸清楚网站前后端交互的逻辑,要明确知道你的爬虫需要哪些网页,哪些网页是包含关键信息的网页,我们应该怎样构造请求获取它们。逻辑清晰了,思路就有了,代码写起来就快了。
2、解析html文件的时候思路灵活一点,各种正则表达式和查询过滤操作可以混着来,解析html文件归根到底还是对于字符串的处理,尤其是不规范的html文件,更能考验编程功底。
以上,可能是我大学在校期间做的最后一个项目了,四年的大学生活即将结束,感慨颇多。毕业之后即将走上工作岗位,心里既有一份期待也有一些焦虑,程序员这条道路我走得并不容易,希望以后一切顺利,与诸君共勉!
用Python实现一个爬虫爬取ZINC网站进行生物信息学数据分析
标签:sig image cep nes 响应 pat turn 文件命名 tput
原文地址:https://www.cnblogs.com/jeysin/p/10962316.html