标签:show load print 访问 opened 语言 总结 pac 共享库
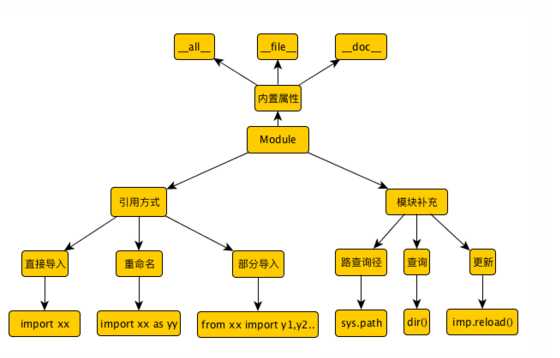
模块就是一组功能的集合体,我们的程序可以导入模块来复用模块里的功能。每一个 Python 脚本.py文件都可以被当成是一个模块。模块以磁盘文件的形式存在。当一个模块变得过大,并且驱动了太多功能的话,就应该考虑拆一些代码出来另外建一个模块。模块里的代码可以是一段直接执行的脚本,也可以是一堆类似库函数的代码,从而可以被别的模块导 入(import)调用。模块可以包含直接运行的代码块、类定义、 函数定义或这几者的组合。
模块分类:Python标准库模块、Python第三方模块、应用程序自定义模块。
Python标准库模块:有些模块直接被构建在解析器里,这些虽然不是一些语言内置的功能,但是他却能很高效的使用,甚至是系统级调用也没问题。这些组件会根据不同的操作系统进行不同形式的配置,比如 winreg (Windows注册表访问)这个模块就只会提供给 Windows 系统。应该注意到这有一个特别的模块 sys ,它内置在每一个 Python 解析器中。可参考:https://www.cnblogs.com/ribavnu/p/4886472.html
https://blog.csdn.net/sadfishsc/article/details/10390065
Python第三方模块:非在解析器里的他人写的python脚本,可到官方提供的第三方模块网址查找、下载:https://pypi.org/。
应用程序自定义模块:自己写的python脚本。
模块作用:
1.可把程序分成一个个的文件,这样做程序的结构更清晰,方便管理。
2.文件里实现的功能可重复利用,提高开发效率。
在Python中用关键字import来引入某个模块,比如要导入模块time,就可以在文件最开始或使用之前的地方用 import 来引入。
语法:import 模块名
在调用模块中的函数时,必须加上模块名调用,因为可能存在多个模块中含有相同名称的函数,此时,如果只是通过函数名来调用,解释器无法知道到底要调用哪个函数。为了避免这样的情况,调用函数时,必须加上模块名。
import加载的模块分为四个通用类别:
1 使用python编写的.py文件
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包,把一系列模块组织到一起的文件夹(注:文件夹下有一个__init__.py文件,该文件夹称之为包)
4 使用C编写并链接到python解释器的内置模块
import time time.sleep(1) #时间睡眠 # sleep() #会报错
我们可以从sys.module中找到当前已经加载的模块,sys.module是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
一行导入多个模块
import time,random #模块之间用逗号隔开 print(time.time()) print(random.randint(1,3))
导入模块重命名:import ... as
有时候你导入的模块名称已经在你的程序中使用了, 或者你不想使用现有的名称。可以使用一个新的名称替换原始的名称。
import time as tm print(tm.time())
python模块搜索路径
在任何一个python程序启动时,都会将模块的搜索路径收集到sys模块的path属性中(sys.path)。当python需要搜索模块文件在何处时,首先搜索内置模块,如果不是内置模块,则搜索sys.path中的路径列表,搜索时会从该属性列出的路径中按照从前向后的顺序进行搜索,并且只要找到就立即停止搜索该模块文件。所以如果当前路径或 PythonPATH中存在与标准module同样的module,则会覆盖标准module。也就是说,如果当前目录下存在xml.py,那么在执行import xml时,导入的是当前目录下的module,而不是系统标准的xml.py。
import sys print(sys.path)
import语句是导入模块中的所有属性,并且访问时需要使用模块变量来引用,Python的from语句让你从模块中导入一个指定的部分到当前命名空间中。使用这种方式导入,不会整个模块导入到当前命名空间,它只会将import的内容导入。from.....import 也支持as模式,给导入的模块重命名。
from time import time,sleep start_time = time() print(start_time) sleep(2) stop_time = time() print(stop_time) print(stop_time-start_time)
导入一个模块的所有内容也可以使用from…import*,但不推荐使用,因为可能造成变量命名冲突。
from time import * print(time()) #可直接使用time模块的所有功能,不需在前缀加模块名
命名冲突示例
from time import * #假如我们不知道time模块里是否有time(),但在导入time模块的下方自己定义了一个名为time的函数 def time(): return ‘自己定义的time函数被调用‘ #在自己定义的time函数下方使用from time import * # from time import * print(time()) #函数名即变量名储存的是函数对象的引用,同名函数会存在引用覆盖。
注意:当Python程序导入其他模块时,要避免循环导入,,即A文件导入了B,B文件又导入了A.,不然总会出意向不到的问题….
使用模块可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块B
目录中只有包含一个叫做__init__.py的文件才会被认作是一个包,__init__.py文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码。当包当作模块被导入时,__init__.py就会被执行加载。
在导入包的时候,Python会从sys.path中的目录来寻找这个包中包含的子目录。
Notes: 自己创建模块时要注意命名,不能和Python自带的模块名称冲突。例如,系统自带了sys模块,自己的模块就不可命名为sys.py,否则将无法导入系统自带的sys模块。
类的属性:
__doc__ 文档字符串
__name__ 类名称
__bases__ 父类组成的元组
__dict__ 保存类方法和变量等的字典
实例的属性:
__class__ 实例所属的类
__dict__ 保存实例数据的字典
模块的属性:
__dict__ 与模块相关的字典
__name__ 模块的名称
__file__ 模块文件的绝对路径
导入包:
导入包与导入模块的方式是一样的。当执行导入包时,__init__.py就会被执行加载。所以包其实也是个模块,__init__.py可以是空文件,不过会影响from <包名> import * 和 import <包名> 这两种导入方式。
创建__init__.py文件:
目录中只有包含了叫做__init__.py的文件,才能被程序认作是包,模块才能被导入成功。现在我们就在msg文件夹下创建一个__init__.py文件,并且在文件中写入__all__=[ ‘module_name‘, ‘module_name‘ ]。
可以在__init__.py中编写其他内容,在导入时,这些编写的内容就会被执行。
可以在__init__.py中向sys.path添加当前被调用模块路径。
__all__总结:
编写Python代码(不建议在__init__中写python模块,可以在包中在创建另外的模块来写,尽量保证__init__.py简单)。
模块中不使用__all__属性,则导入模块内的所有公有属性,方法和类 。 模块中使用__all__属性,包中使用__all__属性,则表示只导入__all__中指定的属性,定义了当我们使用 from <module> import * 导入某个模块/包的时候能导出的符号(这里代表变量,函数,类等) (当然下划线开头的变量,方法和类除外)。
需要注意的是 __all__ 只影响到了 from <package> import * 或 import <package> 这种导入方式, 对于 from <module|package> import <member> 导入方式并没有影响,仍然可以从外部导入。
reload()简介:
无论时import还是from,默认情况下,模块在第一次被导入之后,其他的导入都不再有效。如果此时在另一个窗口中改变并保存了模块的源代码文件,也无法更新该模块。这样设计原因在于,导入是一个开销很大的操作(导入必须找到文件,将其编译成字节码,并且运行代码),以至于每个文件、每个程序运行不能够重复多于一次。当一个模块被导入到一个脚本,模块代码只会被执行一次。因此,如果你想重新执行模块里代码,可以用reload()函数,该函数会重新导入之前导入过的模块。reload()是imp模块中的一个函数,所以要使用imp.reload()之前,必须先导入imp,它的参数是一个已经成功被导入过的模块变量。也就是说该模块必须在内存中已经有自己的模块对象。reload()会重新执行模块文件,并将执行得到的属性完全覆盖到原有的模块对象中。也就是说,reload()会重新执行模块文件,但不会在内存中建立新的模块对象,所以原有模块对象中的属性可能会被修改。语法:reload(module_name)。
import random def mul(x,y): return x*y print(random.randint(3,3)) #此时random.randint()是随机函数。 random.randint = mul #变为乘法函数 print(random.randint(3,3)) from imp import reload reload(random) print(random.randint(3,3)) #变回随机函数。
py文件分两种:用于执行的程序文件和用于导入的模块文件。当直接使用python a.py的时候表示a.py是用于执行的程序文件,通过import/from方式导入的py文件是模块文件。
__name__属性用来区分py文件是程序文件还是模块文件:
__main__对于python来说,因为隐式自动设置,该属性就有了特殊妙用:直接在模块文件中通过if __name__ == "__main__"来判断,然后写属于执行程序的代码,如果直接用python执行这个文件,说明这个文件是程序文件,于是会执行属于if代码块的代码,如果是被导入,则是模块文件,if代码块中的代码不会被执行。
导入模块的过程:
python的import是在程序运行期间执行的,并非像其它很多语言一样是在编译期间执行。也就是说,import可以出现在任何地方,只有执行到这个import行时,才会执行导入操作。且在import某个模块之前,无法访问这个模块的属性。
python在import导入模块时,首先搜索模块的路径,然后编译并执行这个模块文件。虽然概括起来只有两个过程,但实际上很复杂。
Python中所有加载到内存的模块都放在sys.modules。sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员import一个模块文件时,首先会在这个字典查找是否已经加载了此模块,如果加载了则只是将模块的名字加入到正在调用import的模块的Local名字空间中(如果在全局作用域导入模块,则把模块名加入全局命名称空间,如果是在局部作用域导入模块,则模块名加入局部名称空间)。如果没有加载则从sys.path目录中按照模块名称查找模块文件,模块文件可以是py、pyc、pyd,找到后创建新的module对象(此时module对象的 __dict__ 属性为空),并将模块名与module对象的引用加入字典sys.modules中,然后编译、执行模块文件载入内存,并填充module对象的属性__dict__,按照一定的规则将一些结果放进这个module对象中,最后将模块名称导入到当前的Local名字空间。
注意细节:编译、执行模块文件、将结果保存到module对象中。
关于编译、执行模块文件的细说:
模块第一次被导入的时候,会进行编译,并生成.pyc字节码文件,然后python执行这个pyc文件。当模块被再次导入时,如果检查到pyc文件的存在,且和源代码文件的上一次修改时间戳mtime完全对应(也就是说,编译后模块文件的源代码没有进行过修改),则直接装载这个pyc文件并执行,不会再进行额外的编译过程。当然,如果修改过模块文件的源代码,将会重新编译得到新的pyc文件。
注意,并非所有的py文件都会生成编译得到的pyc文件,对于那些只执行一次的程序文件,会将内存中的编译结果在执行完成后直接丢弃(多数时候如此,但仍有例外,比如使用compileall模块可以强制编译成pyc文件),但模块会将内存中的编译结果持久化到pyc文件中。另外,运行字节码pyc文件并不会比直接运行py文件更快,执行它也一样是一行行地解释、执行,唯一快的地方在于导入装载的时候无需重新编译而已。
执行模块文件(已完成编译)的时候,按照一般的执行流程执行:一行一行地、以代码块为单元执行。一般地,模块文件中只用来声明变量、函数等属性,以便提供给导入它的模块使用,而不应该有其他任何操作性的行为,比如print()操作不应该出现在模块文件中,但这并非强制。
总之,执行完模块文件后,这个模块文件将有一个自己的全局名称空间,在此模块文件中定义的变量、函数等属性,都会记录在此名称空间中。
最后,模块的这些属性都会保存到模块对象中。由于这个模块对象赋值给了模块变量module_name,所以通过变量module_name可以访问到这个对象中的属性(比如变量、函数等),也就是模块文件内定义的全局属性。
参考链接:https://www.cnblogs.com/qq78292959/archive/2013/05/17/3083961.html
目录结构package目录与test目录是同级的:
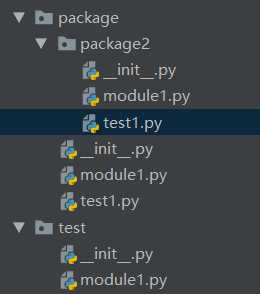

print(‘package/package2目录下的__init__模块被加载‘)
print(‘package/package2目录下的module1.py执行加载‘) print(‘package/package2目录下module1模块的__name__属性值为:{}‘.format(__name__))
‘‘‘导入与父目录的父目录同级的模块‘‘‘ # import test.module1 as md from test import module1
__all__ = [‘module1‘] print(‘package目录下的__init__模块被加载‘)
print(‘package目录下的module1.py执行加载‘) print(‘package目录下的module1模块的__name__属性值为:{}‘.format(__name__)) def add(x,y): return x+y def mul(x,y): return x*y
‘‘‘同目录下的模块导入方式‘‘‘ # import module1 # from package import module1 # from module2 import * #不推荐使用,避免命名冲突 # print(‘package目录下的module1.py执行加载‘) # print(‘module1模块的__name__属性值为:{}‘.format(__name__)) # def add(x,y,z): # return x+y+z # def mul(x,y,z): # return x*y*z # print(module1.add(2,3)) ‘‘‘导入与父目录同级的模块的方法‘‘‘ # import test #导入test包,实质上是导入test目录下的 __init__模块,此模块有什么属性,导入的test就有什么属性。 # print(test.module1.__name__) # import test.module1 as md # from test import module1 ‘‘‘导入同目录下的包‘‘‘ # import package2.module1 as md # from package2 import module1
print(‘test目录下的__init__.py被加载‘) __all__ = [‘module1‘] # 若允许通过包名导入所有模块,必须给__all__实现赋值 from test import * #表示导入同目录的所有模块
print(‘test目录下的module1被加载‘)
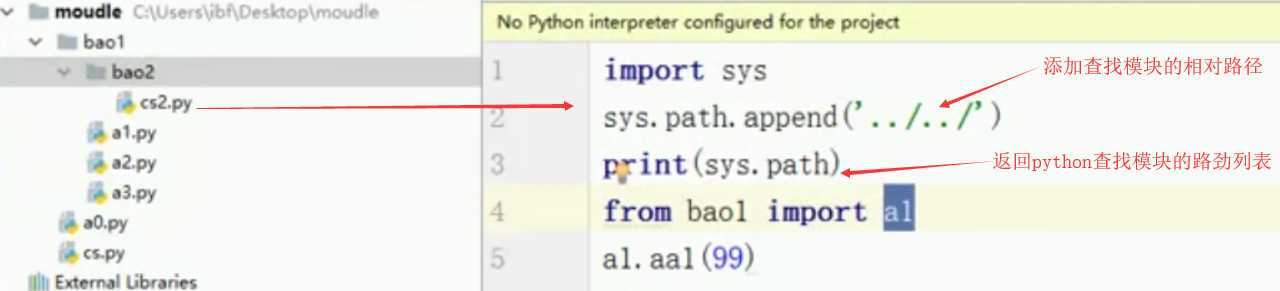
若python解释器无法找到可根据模块的所在目录给sys.path添加搜索路径:
编写一个hello.py的模块
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 4 ‘ a test module ‘ 5 6 __author__ = ‘Michael Liao‘ 7 8 import sys 9 10 def test(): 11 args = sys.argv # argv参数用列表存储命令行的所有参数 12 if len(args)==1: # 当列表长度为1时即只有一个参数时 13 print(‘Hello, world!‘) 14 elif len(args)==2: # 当命令行有两个参数时 15 print(‘Hello, %s!‘ % args[1]) 16 else: 17 print(‘Too many arguments!‘) 18 19 if __name__==‘__main__‘: 20 test()
第1行和第2行是标准注释,第1行注释可以让这个hello.py文件直接在Unix/Linux/Mac上运行,第2行注释表示.py文件本身使用标准UTF-8编码;
第4行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;
第6行使用__author__变量把作者写进去,这样当你公开源代码后别人就可以瞻仰你的大名;
第8行是导入sys模块,导入sys模块后,我们就有了变量sys指向该模块,利用sys这个变量,就可以访问sys模块的所有功能。sys模块有一个argv变量,用list存储了命令行的所有参数。argv至少有一个元素,因为第一个参数永远是该.py文件的名称,例如:运行python3 hello.py获得的sys.argv就是[‘hello.py‘],注意这里python3不算是参数;运行python3 hello.py Michael获得的sys.argv就是[‘hello.py‘, ‘Michael]。
第19行表示当我们在命令行运行hello模块文件时,Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该hello模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
以上就是Python模块的标准文件模板,当然也可以全部删掉不写,但是,按标准办事肯定没错。
标签:show load print 访问 opened 语言 总结 pac 共享库
原文地址:https://www.cnblogs.com/us-wjz/p/10958625.html
