标签:查看 join mysql数据库 com 取数据 https limit 读取 操作
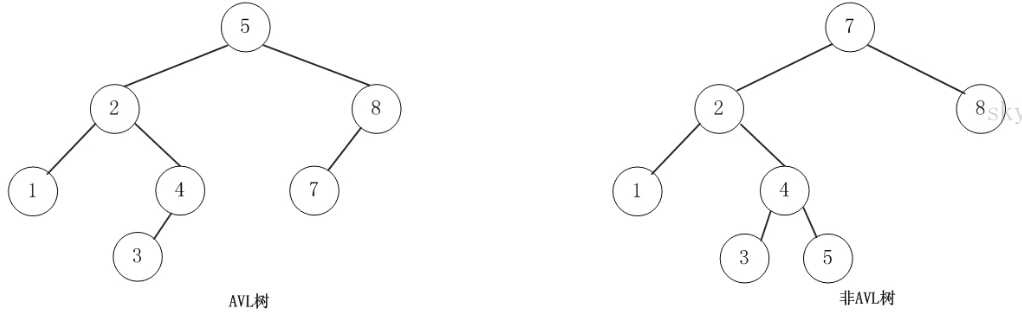
二叉树具有以下性质:左子树的键值小于根的键值,右子树的键值大于根的键值。二叉树的查询效率就低了。因此若想二叉树的查询效率尽可能高,需要这棵二叉树是平衡的。




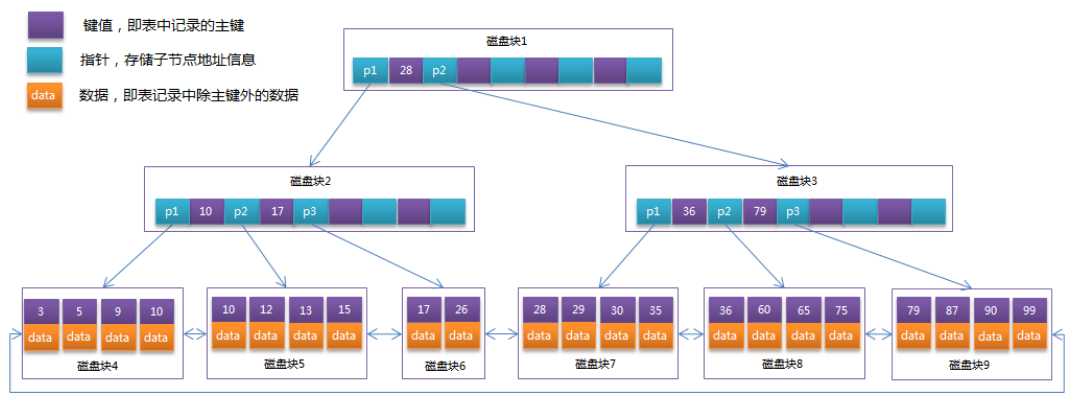
缺点:每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。

二、聚集索引与非聚集索引
聚集索引:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引,一般指主键。
非聚集索引:除聚集索引外其他都是的,包括普通索引,唯一索引,全文索引。叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键。使用非聚集索引查询,而查询列中包含了其他该索引没有覆盖的列,那么他还要进行第二次的查询,查询节点上对应的数据行的数据。
mysql索引一般建5-8个左右,索引过多,影响数据的操作(insert、update、delete)。优化建议使用联合索引。大字段值不建议建索引。创建索引和维护索引需要耗费时间,这个时间随着数据量的增加而增加;索引需要占用物理空间,不光是表需要占用数据空间,每个索引也需要占用物理空间;当对表进行增、删、改、的时候索引也要动态维护,这样就降低了数据的维护速度。
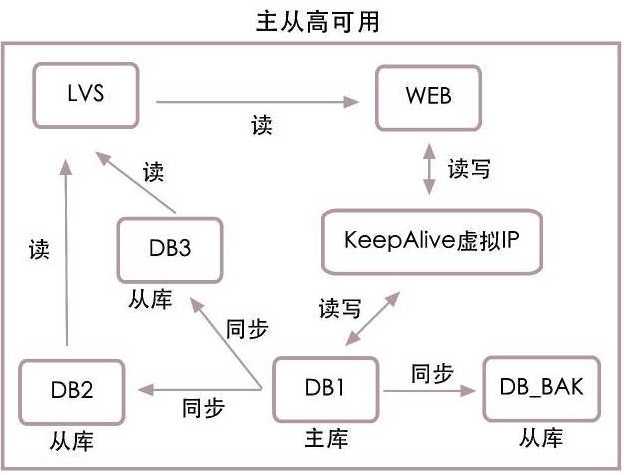

主从复制原理:
采用异步复制模型


十三、mysql索引条件下推ICP
含义:mysql查询条件列在索引范围内,可以根据索引条件直接获取数据,可以减少存储引擎必须访问基表的次数以及MySQL服务器必须访问存储引擎的次数。
1.ICP 只适用于非聚集索引呀
2.只是适用于单表查询,非子查询
3.索引下推开关打开。
标签:查看 join mysql数据库 com 取数据 https limit 读取 操作
原文地址:https://www.cnblogs.com/a747895159/p/10975305.html