标签:调度 lse 相互 pause nta 消失 完全 创建 失败
Pod是Kubernetes调度的最小单元。一个Pod可以包含一个或多个容器,因此它可以被看作是内部容器的逻辑宿主机。Pod的设计理念是为了支持多个容器在一个Pod中共享网络和文件系统 因此处于一个Pod中的多个容器共享以下资源:
PID命名空间:Pod中不同的应用程序可以看到其他应用程序的进程ID。
network命名空间:Pod中多个容器处于同一个网络命名空间,因此能够访问的IP和端口范围都是相同的。也可以通过localhost相互访问。
IPC命名空间:Pod中的多个容器共享Inner-process Communication命名空间,因此可以通过SystemV IPC或POSIX进行进程间通信。
UTS命名空间:Pod中的多个容器共享同一个主机名。
Volumes:Pod中各个容器可以共享在Pod中定义分存储卷(Volume)。
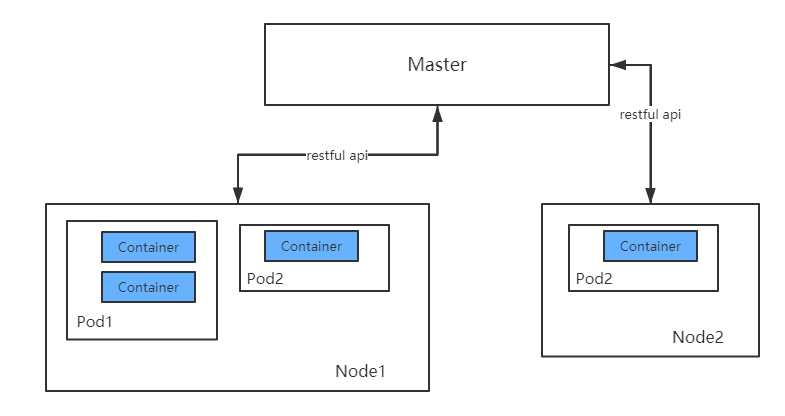
Pod,容器与Node(工作主机)之间的关系如下图所示:
通过yaml文件或者json描述Pod和其内容器的运行环境和期望状态,例如一个最简单的运行nginx应用的pod,定义如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
在生产环境中,推荐使用诸如Deployment,StatefulSet,Job或者CronJob等控制器来创建Pod,而不是直接创建。
将上述pod描述文件保存为nginx-pod.yaml,使用kubectl apply命令运行pod
kubectl apply -f nginx-pod.yaml下面简要分析一下上面的Pod定义文件:
spec: 其它描述信息,包含Pod中运行的容器,容器中运行的应用等等。不同类型的对象拥有不同的spec定义。详情参见API文档:https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.9/
Kubernetes在每个Pod启动时,会自动创建一个镜像为
gcr.io/google_containers/pause:version的容器,所有处于该Pod中的容器在启动时都会添加诸如--net=container:pause --ipc=contianer:pause --pid=container:pause的启动参数,因此pause容器成为Pod内共享命名空间的基础。所有容器共享pause容器的IP地址,也被称为Pod IP。
如果我们希望从外部访问这nginx应用,那么我们还需要创建Service对象来暴露IP和port。
Pod的生命周期是Replication Controller进行管理的。一个Pod的生命周期过程包括:
通过yaml或json对Pod进行描述
apiserver(运行在Master主机)收到创建Pod的请求后,将此Pod对象的定义存储在etcd中
scheduler(运行在Master主机)将此Pod分配到Node上运行
Pod内所有容器运行结束后此Pod也结束
在整个过程中,Pod通常处于以下的五种阶段之一:
Pending:Pod定义正确,提交到Master,但其所包含的容器镜像还未完全创建。通常,Master对Pod进行调度需要一些时间,Node进行容器镜像的下载也需要一些时间,启动容器也需要一定时间。(写数据到etcd,调度,pull镜像,启动容器)。
Running:Pod已经被分配到某个Node上,并且所有的容器都被创建完毕,至少有一个容器正在运行中,或者有容器正在启动或重启中。
Succeeded:Pod中所有的容器都成功运行结束,并且不会被重启。这是Pod的一种最终状态
Failed:Pod中所有的容器都运行结束了,其中至少有一个容器是非正常结束的(exit code不是0)。这也是Pod的一种最终状态。
Unknown:无法获得Pod的状态,通常是由于无法和Pod所在的Node进行通信。
定义Pod时,可以指定restartPolicy字段,表明此Pod中的容器在何种条件下会重启。restartPolicy拥有三个候选值:
Always:只要退出就重启
OnFailure:失败退出时(exit code不为0)才重启
Never:永远不重启
Pod本身不具备容错性,这意味着如果Pod运行的Node宕机了,那么该Pod无法恢复。因此推荐使用Deployment等控制器来创建Pod并管理。
一般来说,Pod不会自动消失,只能手动销毁或者被预先定义好的controller销毁。但有一种特殊情况,当Pod处于Succeeded或Failed阶段,并且超过一定时间后(由master决定),会触发超时过期从而被销毁。
总体上来说,Kubernetes中拥有三种类型的controller:
Job。通常用于管理一定会结束的Pod。如果希望Pod被Job controller管理,那么restartPolicy必须指定为OnFailure或Never。
ReplicationController,ReplicaSet和Deployment。用于管理永远处于运行状态的Pod。如果希望Pod被此类controller管理,那么restartPolicy必须指定为Always。
DaemonSet。它能够保证你的Pod在每一台Node都运行一个副本。
标签:调度 lse 相互 pause nta 消失 完全 创建 失败
原文地址:https://www.cnblogs.com/tylerzhou/p/10977482.html