标签:特征 sample 出图 pyplot 中心 技术 使用 code data
Kmeans是无监督学习的代表,没有所谓的Y。主要目的是分类,分类的依据就是样本之间的距离。比如要分为K类。步骤是:
Kmeans的基本原理是计算距离。一般有三种距离可选:
欧氏距离
\[ d(x,u)=\sqrt{\sum_{i=1}^n(x_i-\mu_i)^2} \]
曼哈顿距离
\[ d(x,u)=\sum_{i=1}^n(|x_i-\mu|) \]
余弦距离
\[ cos\theta=\frac{\sum_{i=1}^n(x_i*\mu)}{\sqrt{\sum_i^n(x_i)^2}*\sqrt{\sum_1^n(\mu)^2}} \]
每个簇内到其质心的距离相加,叫inertia。各个簇的inertia相加的和越小,即簇内越相似。(但是k越大inertia越小,追求k越大对应用无益处)
模拟数据:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500, # 500个样本
n_features=2, # 每个样本2个特征
centers=4, # 4个中心
random_state=1 #控制随机性
)画出图像:
color = ['red', 'pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(4):
axi1.scatter(X[y==i, 0], X[y==i,1],
marker='o',
s=8,
c=color[i]
)
plt.show()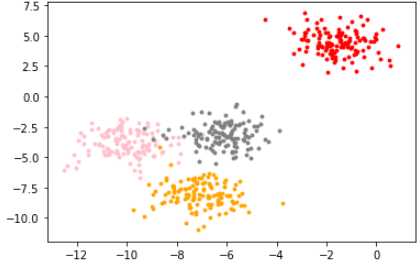
使用KMeans类建模:
from sklearn.cluster import KMeans
n_clusters=3
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(X)也可先用fit, 再用predict,但是可能数据不准确。用于数据量较大时。
此时就可以查看其属性了:质心、inertia.
centroid=cluster.cluster_centers_
centroid # 查看质心查看inertia:
inertia=cluster.inertia_
inertia画出所在位置。
color=['red','pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(n_clusters):
axi1.scatter(X[y_pred==i, 0], X[y_pred==i, 1],
marker='o',
s=8,
c=color[i])
axi1.scatter(centroid[:,0],centroid[:,1],marker='x',s=100,c='black')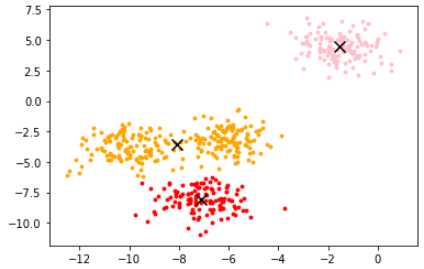
标签:特征 sample 出图 pyplot 中心 技术 使用 code data
原文地址:https://www.cnblogs.com/heenhui2016/p/10988892.html