标签:之间 table 关闭 系统 根据 分组 select 查询条件 $$
1NF:对属性的原子性约束,即表的列具有原子性,不可再分解。
2NF:表中的记录是唯一的,实体属性完全依赖于主键,每张表只描述一件事情。
3NF:表中不能有冗余数据,任何非主属性不依赖于其他非主属性,从表的外键必须使用主表的主键。
反三范式:某些业务场景下,为了提高效率,可能会适当降低范式标准,增加字段,允许冗余。
主键索引:当一张表把某个列设为主键的时候,该列就是主键索引
普通索引:一般先创建表,再创建普通索引
create index 索引名 on 表(列)alter table 表名 add index 索引名 (列)全文索引:全文索引主要针对文件,文本的检索,比如文章,全文索引只针对myisam引擎有效
create table test (
? xxx VARCHAR(20),
? yyy TEXT,
? FULLTEXT(xxx,yyy)
)engine=myisam charset utf-8;
使用全文索引:select * from test where match(xxx,yyy) against(‘aaa‘);
fulltext索引只针对myisam生效;只针对英文生效->sphinx处理中文;停止词概念,因为在一个文本中,创建索引是一个无穷大的数,对一些常用词和字符,就不会创建,这些词叫停止词
唯一索引:当表的某列被指定为unique约束时,这列就是一个唯一索引
二叉树算法(BTREE)--->构建索引文件--->中间点为根节点--->再取中间--->小的放在左子树,大的右子树--->...
检索次数log ~2~N
没有创建索引时,dbms必须一条条检索,就算已经检索到指定记录,也要检索完所有记录才会停止
较为频繁作为查询条件的字段应创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
更新非常频繁的字段不适合创建索引
不会出现在where子句中的字段不该创建索引
总结:满足以下条件的字段,才应该创建索引:
%aaa不会使用索引,aaa%会使用索引,如果必须使用变化值,则考虑使用全文索引查看索引使用情况:show status like ‘Handler_read%‘
handler_read_key:值越高越好,越高表示使用索引查询到的次数
handler_read_rng_next:这个值越高,说明查询低效
#### show status命令
了解各种SQL的执行频率
show status like ‘xxx‘(uptime,com_insert,com_update,com_select,connection)
show [session|global] status like ‘xxx‘ 默认是session会话
show status like ‘slow_queries‘ 显示慢查询
定位执行效率较低的SQL语句(select)
通过explain分析低效率的SQL语句执行情况
确定问题采取优化措施
MyISAM:表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam引擎,比如论坛的发帖表,回复表,优势是访问速度快
optimize table 表名InnoDB:提供了具有提交/回滚和崩溃恢复能力的事务安全,但是效率差一些且会占用更多的磁盘你空间,例如订单表,账号表
Memory:数据频繁变化,不需要入库,同时又频繁的查询和修改,考虑使用memory
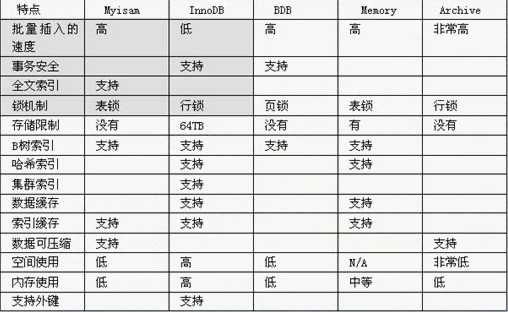
MyISAM和InnoDB区别:
例如:在开发addUser时,在添加用户时,各个用户的id确认,可以通过使用一个辅助表UUID帮助生成一个编号
分表规则:login0,login1,login2 根据用户id%3的值来判断这个用户在哪个表中
某些表的某些字段,这些字段在查询时并不是经常关心的,但是数据量很大,建议把这些字段单独放到另外一张表,从而提高效率
标签:之间 table 关闭 系统 根据 分组 select 查询条件 $$
原文地址:https://www.cnblogs.com/story-xc/p/10997069.html