标签:网络 tpc monitor backend url cal etc bin img
后端web服务器状态检测HAProxy有三种状态检测方式:
1.基于四层的传输端口做状态监测
2.基于指定的uri做状态监测
3.基于指定的URI的resquest请求头部内容做状态监测
四层传输时可以基于ip或者port做监测,也可以将ip和port监测在后端服务器上的另一个地址和端口用来实现数据通道和监测通道的分离
示例:
1.修改配置文件
[root@localhost ~]# vim /etc/haproxy/haproxy.cfg
frontend web
bind 172.20.27.20:80
mode tcp
use_backend web_server
backend web_server
server web1 192.168.27.21 check addr 192.168.27.21 port 80 inter 3s fall 3 rise 5
server web2 192.168.27.22 check addr 192.168.27.22 port 80 inter 3s fall 3 rise 5 测试
将web1的nginx服务停止
[root@localhost ~]# nginx -s stop查看状态页面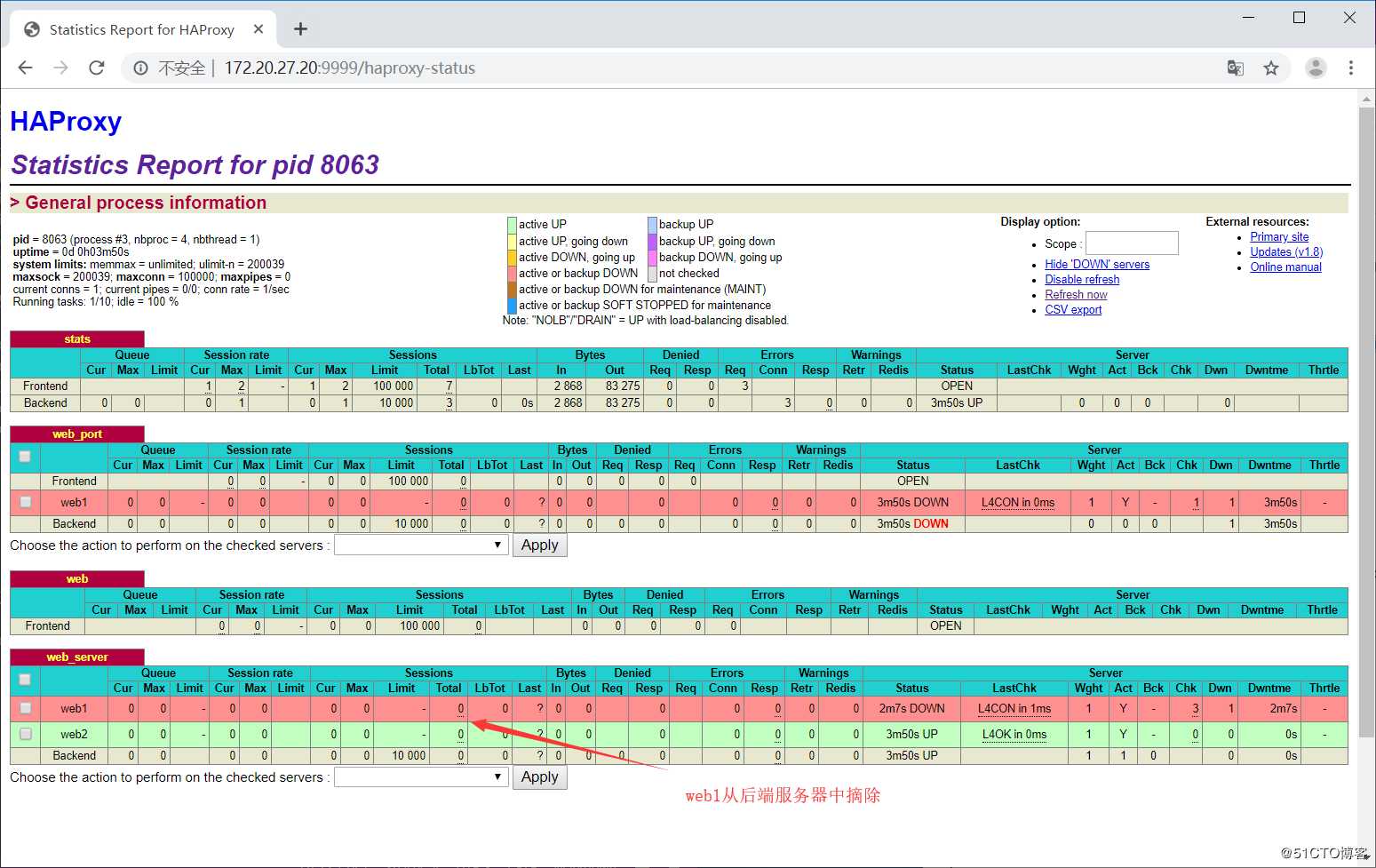
指定uri做状态监测是,在后端服务器上建立一个用户无法访问到的页面,然后再haproxy上对此页面做监测,如果能访问到此页面则表示后端服务器正常
示例:
1.在web2上创建一个moniter-page,仅用于探测,不给用户连接
[root@web2 ~]# mkdir /apps/nginx/html/monitor-page
[root@web2 ~]# echo ojbk > /apps/niginx/html/monitor-page/index.php #网页文件创建在用户无法访问到的地方2.修改haproxy配置文件
frontend web
bind 172.20.27.20:80
mode http
use_backend web_server
option httpchk GET /monitor-page/index.html HTTP/1.0 #添加需要监测的uri
backend web_server
server web1 192.168.27.21 check addr 192.168.27.21 port 80 inter 3s fall 3 rise 5
server web2 192.168.27.22 check addr 192.168.27.22 port 80 inter 3s fall 3 rise 5查看状态页面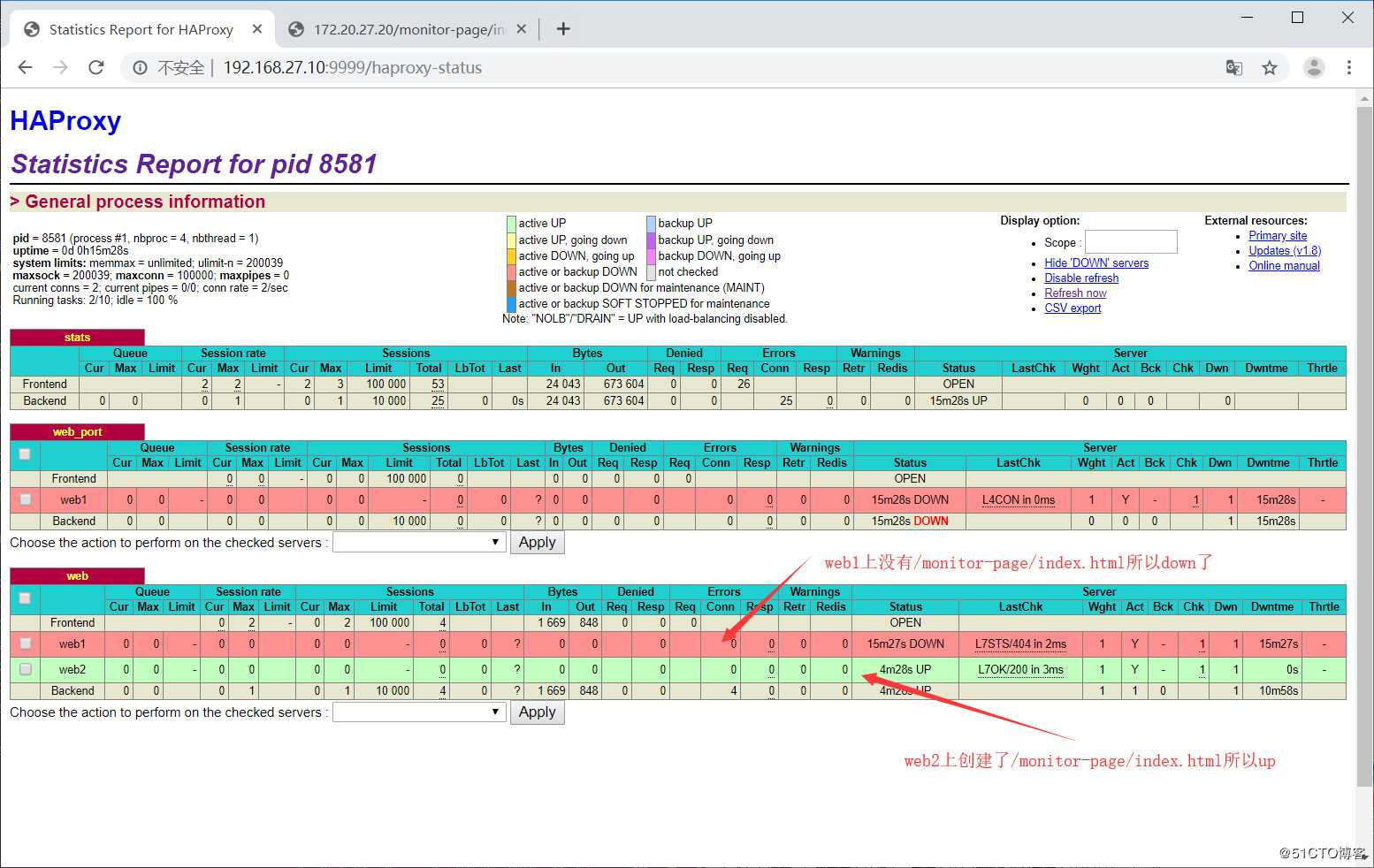
GET的监测方式存在一点问题,如果页面文件很大,页面每隔几面就需要完整的传输一次,这样就造成了不必要的了网络消耗,所以将探测方式改为只查看请求头部内容做状态监测
基于uri的request请求头部的状态做监测和url做监测类似
示例:
1.修改haproxy的配置文件
listen web
bind 172.20.27.20:80
mode http
option httpchk HEAD /monitor-page/index.html HTTP/1.0 #改为监测HEAD只监测页面的状态
server web1 192.168.27.21:80 weight 1 check inter 3s fall 3 rise 5
server web2 192.168.27.22:80 weight 1 check inter 3s fall 3 rise 52.在web1上创建监测文件
[root@web1 ~]# echo ojbk > /apps/nginx/html/monitor-page/index.html3.查看状态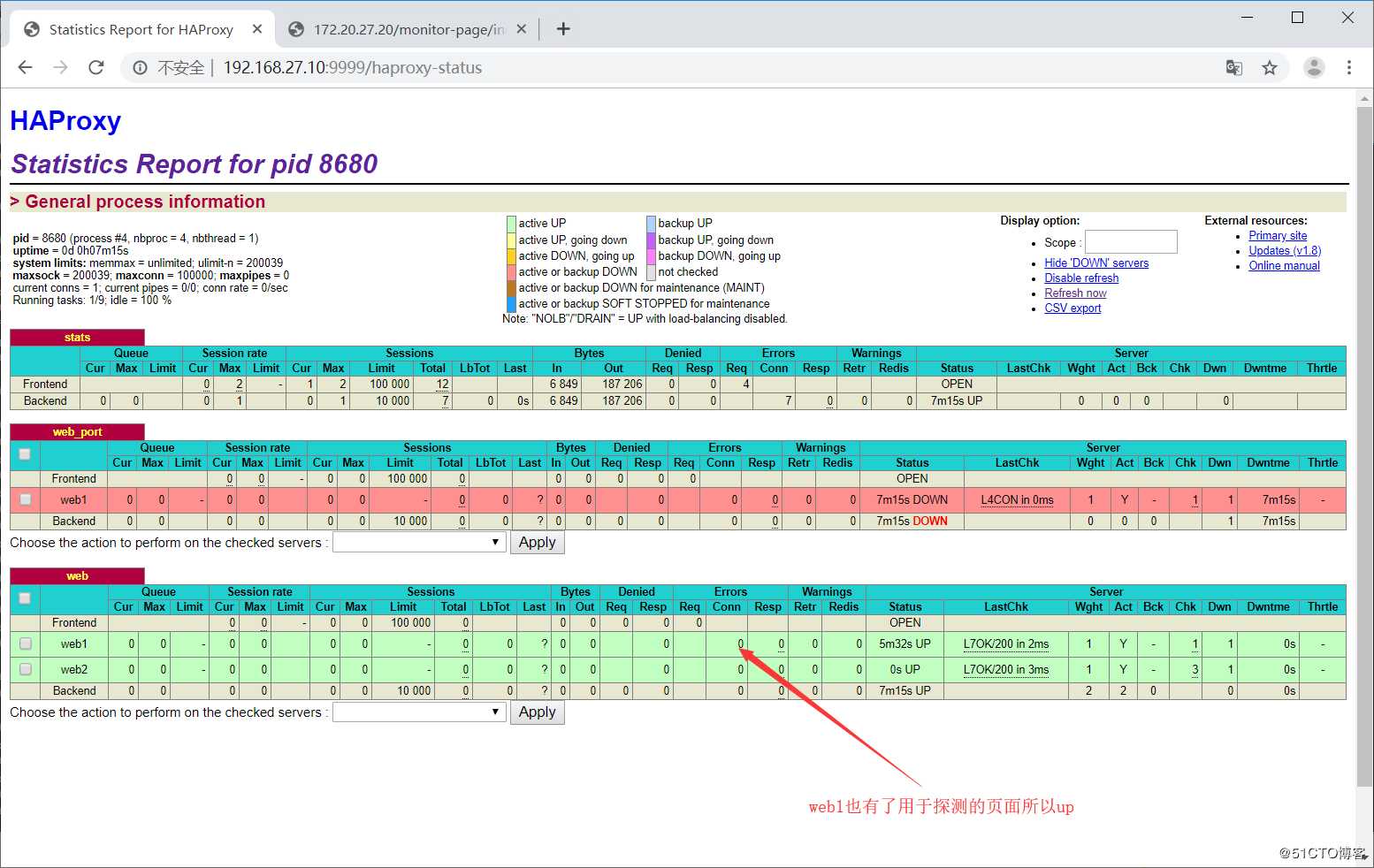
注意:用于探测的页面需要和开发进行协商,否则可能造成页面的丢失,将后端服务器全部down造成事故
标签:网络 tpc monitor backend url cal etc bin img
原文地址:https://blog.51cto.com/11886307/2406616