标签:art 否则 img cep ted 引用 撤销 代码 重复
1、泛型的本质是将类型参数化,即将数据类型作为参数。
2、泛型可以在编译期进行检查,其所有的强制转换是隐式且自动的,提高了代码的安全性。
3、泛型可以用在类(泛型类)、接口(泛型接口)、方法(泛型方法)的创建。
4、泛型的类型参数只能为引用类型,不能为基本类型。
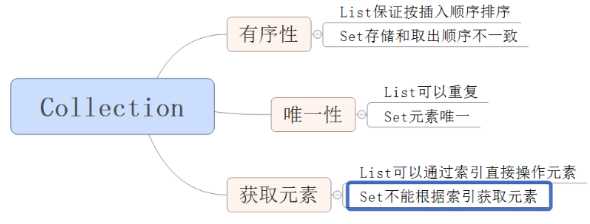
(1)Collection体系: Set、List、Queue。
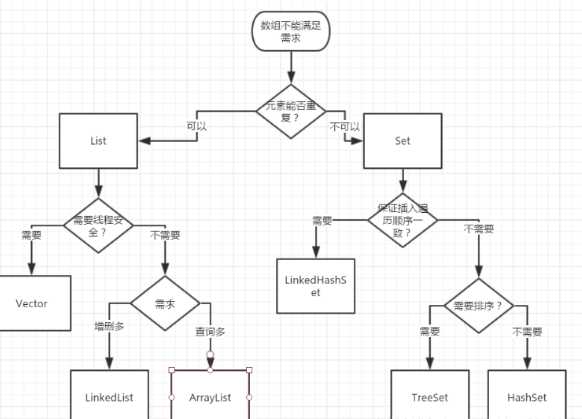
Set:元素无序且不可重复。HashSet,TreeSet。
List:元素有序且可重复。LinkedList,ArrayList。
Queue:队列,先进先出。Deque。
(2)Map体系:HashMap、TreeMap。



(1)使用Iterator接口,不能直接new,使用集合的方法去调用。即Iterator it = c.iterator();
(2) java.util.Iterator; 其使用流程为问,取,删(不必须)。
(3)方法:
boolean hasNext();问操作,查询当前集合是否还有元素。
Object next();取操作,取出集合元素。
Iterator remove() ;删操作,删除集合元素。
(4)使用迭代器过程中,不能使用集合的相关方法去改变集合中的元素,只能使用迭代器的方法。比如现有集合c,迭代器t,则只能使用 t.remove()删除刚next出来的元素,不能使用 c.remove(),使用的话会抛出异常。
for (Object t : c ) { //foreach循环 } //等价于 Iterator it = c.iterator(); while(it.hasNext){ Object obj = it.next(); }
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
(3)Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素

(1)HashSet:底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素(key只能有一个为null),元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。equals相同的两个对象,hashcode也要相同。但hashcode相同的两个对象,equals却不一定相同。
(2)LinkedHashSet:底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
(3)TreeSet:底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造,使元素自身具备比较性)和比较器排序(有参构造,使集合自身具备比较性),自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;比较器排序需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
(1)数组只能转到List集合,不能为Set集合,因为数组可能有重复的值,但Set为不可重复集合。
(2)List Arrays.asList(T array)方法来将数组转为集合。但此操作不能对集合进行任何添加删除操作,即此集合只可读。否则抛出异常java.lang.UnsupportedOperationException。若想操作集合,则将此集合整体加入到另一个集合中,使用构造方法加入,或者调用addAll()方法。
(1)先进先出原则(FirstInputFirstOutput)。
(2)java.util.Queue.。JDK提供Queue接口,LinkedList是其实现类,这是由于Queue频繁增删。offer添加,poll取出。
(3)方法:
boolean offer(T t); 入队方法,添加到队尾。
T poll();出队方法,用于获取队首元素。
T peek();不出队方法,用于获取队首元素。
遍历方法是一次性的,每次都是出队操作。
Queue<String> queue = new LinkedList<String>(); queue.offer("1"); queue.offer("2"); System.out.println(queue); //[1,2] String str = queue.poll(); System.out.println(queue);//[2] str = queue.peek(); System.out.println(queue);//[2]
(1)Deque为Queue的子接口。为双端队列,即两端均可以进行offer与poll操作。
(2)若将其限制为只准一端进行offer与poll操作,那么即为栈(Stack)的数据结构。其中入栈push,出栈pop。栈遵循先进后出原则(FirstInputLastOutput),用于记录一组可回溯的操作,比如撤销与前进操作。
(3)方法:
void push(T t); 入栈操作,压入一个元素。
T pop() ;出栈操作,取出栈顶元素。
T peek(); 取出栈顶元素,但不出栈。
遍历也是一次性的。
Deque<String> stack = new LinkedList<String>(); stack.push("1"); stack.push("2"); System.out.println(stack);//[2,1],后进先出 String str = stack.peek(); System.out.println(stack);//[2,1] str = stack.pop(); System.out.println(stack);//[1]
Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。 Map是接口,通常使用其实现类HashMap来创建它。也可以通过LinkedHashMap来创建它,可以保证存入与取出的顺序一致。
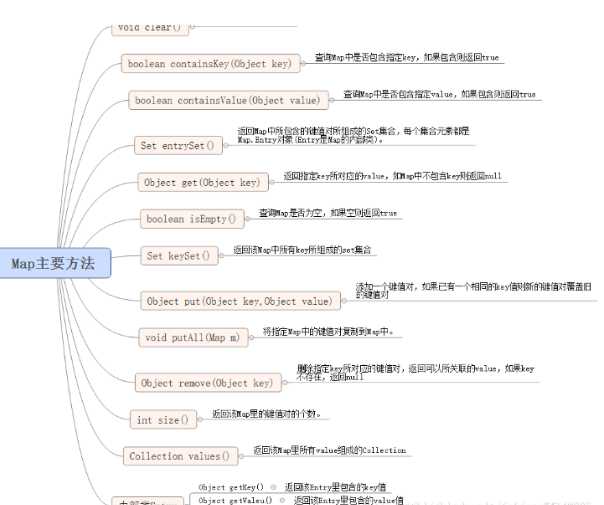
Map 的内容可以被当作一组 key 集合(Set keySet()),一组 value 集合(Collection values),或者一组 key-value 映射(Set entrySet())。
(1)HashMap: 基于哈希表实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。由链表与数组组合实现。首先根据hashcode计算一个哈希值,再根据hash算法计算一个值,此值代表的是数据在数组中的存储位置。当定位到同一个数组位置上时,会通过链表的形式将值保存。即使用数组保存数据的位置,使用链表保存每个数组位置的值。JDK8后,当链表的存储的数据个数大于8时,将自动转为红黑树保存。
非线程安全基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。适用于按自然顺序或自定义顺序遍历键(key)。

(1)LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
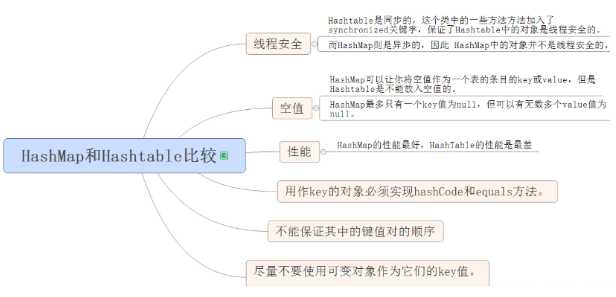
(2)HashMap是非线程安全的,HashTable是线程安全的;
(3)StringBuilder是非线程安全的,StringBuffer是线程安全的。
(1)ArrayXxx:底层数据结构是数组,查询快,增删慢
(2)LinkedXxx:底层数据结构是链表,查询慢,增删快
(3)HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
(4)TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序
https://blog.csdn.net/feiyanaffection/article/details/81394745
标签:art 否则 img cep ted 引用 撤销 代码 重复
原文地址:https://www.cnblogs.com/l-y-h/p/11001112.html